標題是最近 (2020/10) 在 Facebook 上的熱門話題,經過幾天之後,看了很多業界高手、前輩、專家的熱烈討論之後,沈澱了幾天,昨天 (10/17 Sat) 午休睡醒後迷迷糊糊寫下的, 原始文章連結 … 過程中,陸續修補一些想法和參考資料。
Updated:
- 2023/07/19: 本文全文內容收錄在個人著作 《SRE 實踐與開發平台指南》 - 2023/08 上市
- 2026/06/17: 「星期五要不要部署」五年後:當主詞不再是人
標題是最近 (2020/10) 在 Facebook 上的熱門話題,經過幾天之後,看了很多業界高手、前輩、專家的熱烈討論之後,沈澱了幾天,昨天 (10/17 Sat) 午休睡醒後迷迷糊糊寫下的, 原始文章連結 … 過程中,陸續修補一些想法和參考資料。
Updated:
- 2023/07/19: 本文全文內容收錄在個人著作 《SRE 實踐與開發平台指南》 - 2023/08 上市
- 2026/06/17: 「星期五要不要部署」五年後:當主詞不再是人
原文是 2020/08/13 寫下的 memo,主要是有效的會議,最後一段則是 08/06 寫的一段想法,也是會議效率化的想法。與標題相對應的,則是 一場失敗的會議。
整理 同步機制 (Synchronization) 的基礎概念,基本上就是作業系統概念的第六章內容。
Operating System Concepts,俗稱恐龍書,整理筆記時最新是第十版 (2018)。
面試是雙向的,資方要用人,勞方要找機會,雙方透過面試找到彼此的交集、找到共事的可能與機會。本文整理數百次面試經驗過程中,常見的面試問題,希望可以協助更多求職者順利找到理想工作。
問題分成以下幾類:
這些問題種類,裡面各有代表性的各別整理問題的現象。
最後整理一些建議做法,給求職者參考。
分散式交易 (Distributed Transactions) 指分散在各個運算單元的一系列任務操作 (Operations) 或任務 (Tasks)、有次序的 (Ordered)、且彼此是隔離 (Isolation)、最終達成一致的過程。達成一致 指的是全部動作都成功、或者全部動作都失敗,後者則透過 Rollback 還原。
分散式交易對應的就是單機交易,也就是在一個運算資源上,完成交易動作,電商最常見的案例就是:
這兩的操作 (Operations) 滿足次序性、最後達成交易,也就是關聯式資料庫常說的 ACID 原則。如果這個過程是在分散式系統,就必須有其他機制達到此需求。
常見的分散式交易有幾種協議,像是:
本文整理 XA、二階段提交 (2PC)、三階段提交 (3PC)、TCC (Try-Confirm-Cancel) … 等基礎概念。文章資料主要參考自 Distributed Systems: Concepts and Design (5th Edition)、分佈式事務:All or nothing 兩篇的整理。
Using AWS for Disaster Recovery 整理 AWS 針對災難還原的實踐原則,而去年 (2019) 我在公司真實執行災難演練,這是第二次的經驗。這段過程,在年初 (2020/01/08) 的 AWS reInvent reCAP 2019 跟大家分享整個執行過程。
在整理 如何量測系統的容量? 給自己挖了一個坑,整理這篇,先起個頭。可靠性工程 (Reliability Engineering)1 是系統工程的子項目之一,概念上非常類似於 可用性 (Available),但不全然。依據 Practical Reliability Engineering 的定義,可靠性如下:
The probability that an item will perform a required function without failure under stated conditions for a statd period of time.
可靠性是指某套系統在指定的環境下,在要求的時間內成功持續執行某個功能的機率。
這段定義在 SRE 序中也有引用。
這篇整理個人的理解與簡單總結,不見得與一般的書本一樣,主要專注在 What (可靠性的定義)、How (工程實踐)。
溝通就是把資訊從自己腦袋裡挖出來,然後透過載體,像是用語言、文字、圖畫、藝術、肢體 …. 傳達給另一個人,讓對方知道你在想啥。溝通的理想結果是彼此 100% 知道彼此的感受、體驗、想法,藉由此相互的理解,然後進一步的合作、協作、或者是情感交流。一般透過語言的溝通程序大概如下圖:

整個過程有幾個階段:
本文同步發佈在 Matters: 廢文:溝通的原理
整理一些 密碼學 (Cryptography) 與 資訊安全 (Information Security) 的專有名詞、重要概念、密碼學演算法、應用協議、資訊安全概念,主要資料都參考自 Wikipedia。
- 本文非一次性整理,相關筆記漸進式整理上來。
- 本文只是個人學習的梳理,可能有誤,如有建議歡迎給予指導,感謝。
整理 Key Management Service (KMS) 的學習筆記,包含以下:
KMS 需要有密碼學與資訊安全的概念,所以另外整理 摘要密碼學與資訊安全 的筆記。
下班前 (02/07 Fri) 同事問 Container 除了可以讓應用程式在本機與正式環境一樣,跟 VM 比較起來還有什麼好處?認真說可以說很多,簡單整理 我在三分鐘內口述的東西,因為要趕公車,三分鐘到了我就先跑了XDD,這段文字是在公車上敲下的,原文點 這裡。
當下第一個直覺就是清楚的資源邊界:
隔離性,衍生的議題就是資源管理與成本。第二個想到的就是資安,衍生議題就是系統維運 (Operations)。所以先針對這兩個部分描述。
最近因為武漢肺炎事件,國家必須用各種方式通報國民,包含嚴重性、通報的方法、交付有意義的資訊。
這整個過程就是事件管理是一樣的。摘錄我在 2017 年分享的一段想法:淺談系統監控與 CloudWatch 的應用,其中第四部分談的異常通報 就是談事件通報與管理的核心概念。
Updated 2023/07/19: 本文部分收錄在個人著作 《SRE 實踐與開發平台指南》 - 2023/08 上市
整理我認識的計算機科學家。
在組織裡推動事情,最困難的往往不是技術上的執行問題、不是成本問題、溝通問題、協作問題,困難的是:
如何讓高層、主管、團隊成員
意識 (Awareness)到:這是一個必須被正視的問題。
當問題被正視了,大家都 Awareness 了,接下來才有開始討論如何解決、如何 有效定義目標與執行、落地、資源才會進來 …
SRE 讀書會 Round 3 從今年 2019/03/15 開始,在 2019/12/05 (四) 的寒流之下完結了,大家頂著 15 度低溫、加上下著雨,依舊準時出席讀書會,走完這次最後的章節。
今年一整年,起了好幾個跨部門、跨組織的任務,在這過程一直在嘗試讓一個成員、或者讓一個團隊可以自主完成任務的方法,過程中踩了很多雷,像七傷拳一樣,常常是還沒發拳自己就先中了內傷,內力不夠深厚打七傷拳才會傷到自己,後來慢慢梳理出一套可以執行的方法,年底也看到成果了。
除了這些大範圍的協作,工作上經常交付任務給團隊執行,交辦的方式會是口頭交辦、公開的指派、正式的賦予權責,交辦的對象則有自己團隊的資深、到資遣成員,協作團隊的成員 … 不管怎樣的交付任務,都需要一個有效的方法來確立目標是可以執行。
這篇整理了一些歷程與土炮方法,分成以下幾個部分:
CloudFront 是 AWS 非常重要的服務,用了幾年,斷斷續續有一些心得與想法,這次換個方式整理筆記,先全部用 Q and A 方式記錄學習。
本文整理的 Delivery Method 以 Web 為主
最近有朋友問我一些測試的問題,問題層面很廣,像是去一家新創 Startup 如何 Build Up QA Team?自動化測試該用哪一套?測試的方法論該怎麼落地?聊到後來我發現問題背後的期待有問題,期待是什麼?
測試想要一步到位
基於這個前提,後來我把觀察到的現象與問題寫下,起筆是 2018/07/03 的隨筆,在不同時間陸陸續續整理以下文章:
這篇文章整理上述文章的想法與整合。
本文的思路,後來整理成專文: 如何意識到問題的存在
20230523 更新:本文內容部分收錄在 共同著作《軟體測試實務》 第一冊 第一章之中,歡迎大家彭場指導。
這幾年工作關係,經常讀一些資料,但有幾篇是經常重複閱讀、重複分享,這幾篇文字影響我很多,整理起來需要分享時比較快 XD
所有文章標題都是原文連結。
整理 EKS 的 Networking 相關的問題,主要有規劃、管理 … 等觀測,如下:
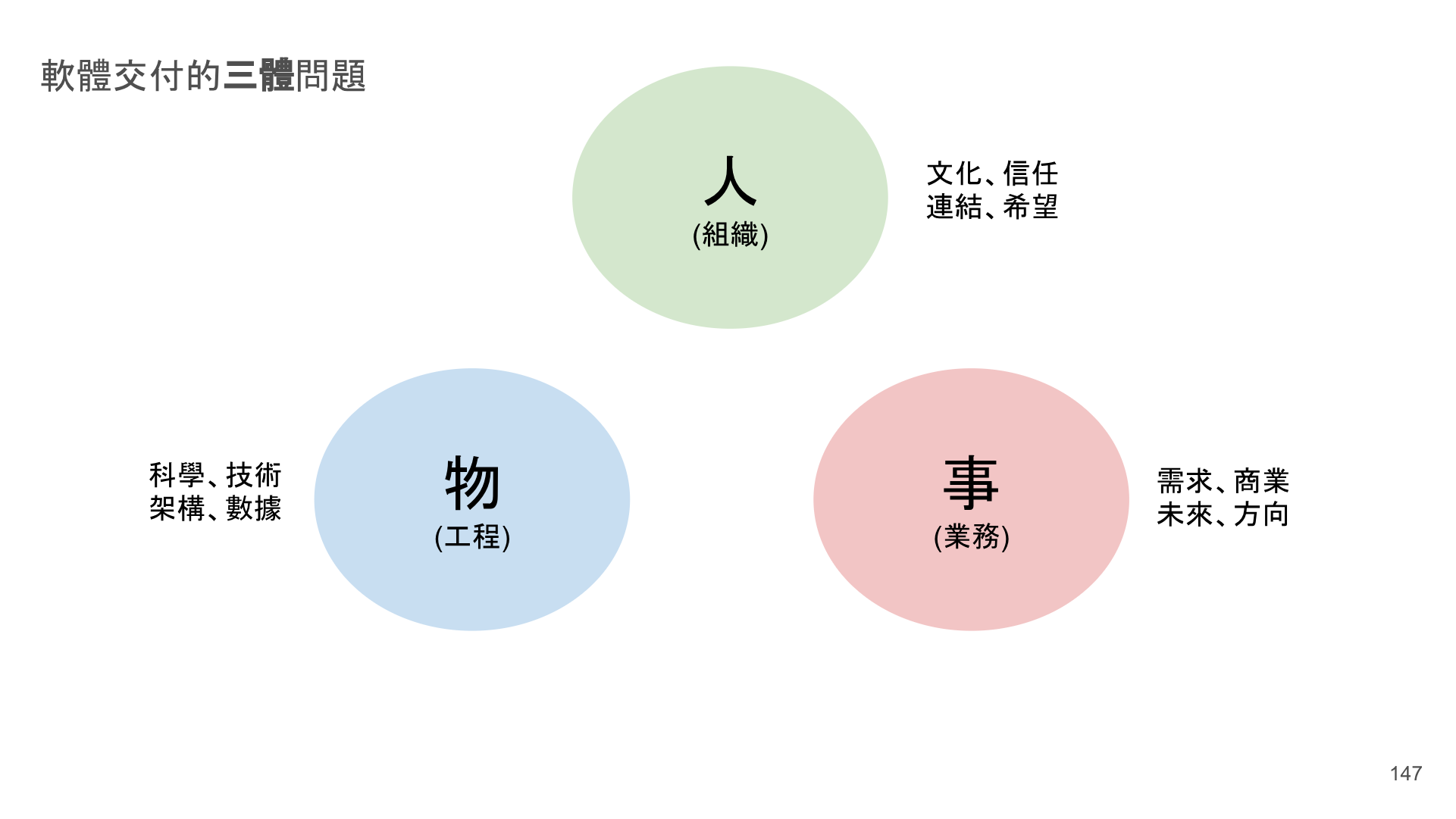
這段個別剪接出來的三分鐘錄影,是今年 (2019) 四月我在新竹敏捷 (交大) 分享的,我稱為 軟體交付的三體問題。
Updated 2023/07/19: 本文收錄在個人著作 《SRE 實踐與開發平台指南》 - 2023/08 上市
整理相關 EKS 的學習筆記,包含規劃 (Planning)、建置 (Provisioning)、管理 (Management / Operation) 等。
上一篇 整理了使用 kubeadm 安裝 K8s Cluster / Worker Nodes / CNI … 等,同樣的,本文整理使用 AWS EKS 安裝 K8s v1.14 的筆記,安裝過程則以 AWS CLI 為主,同樣方式也可以使用 eksctl、AWS Console、CloudFormation 執行。
如同之前提及,雖然 EKS 是 Managed Service,但是實際上只有針對 Master Nodes,而 Worker Nodes 還是需要自行管理以及維護的,另外針對 Ingress、使用者權限、Log 蒐集、資源監控、網路 (CNI 相關) … 等,還是需要額外規劃。
筆記內容:
這也是個朋友問的問題,問題截圖如下:

先不管誰有沒有穿褲子,從整體來看,重新整理問題:
系統發生異常時,第一時間如何快速止血?
底下整理我經常在處理分析時的思路。
Updated 2023/07/19: 本文收錄在個人著作 《SRE 實踐與開發平台指南》 - 2023/08 上市
淺談效能測試 整理了關於 Capacity、Reliabilty、Stability 的概念與定義。本文針對如何量測 系統容量 (Capacity),整理怎麼做的方法論,可以當作 Capacity Plan Guideline。
系統容量是透過
量測 (Measure)出來的,結果是數據統計的報表,而測試的結果通常是 pass or fail,故本文的描述不用測試這個動詞。
這篇文章整理的是如何執行的概念,但不包含以下:
更新:
- 20230523: 本文全文收錄在 共同著作《軟體測試實務》 第二冊 第一章之中,歡迎大家彭場指導。
- 20260519: 《Mini PC 效能實驗:實測 Throughput / RPS / C10K》 是本文方法論實際執行筆記,
CloudWatch Agent (底下簡稱 CWA) 是 awslogs 的後續版本,提供了更強大的功能與整合能力。整理 CWA 的基本概念、如何安裝與配置、以及常見問題。
本文範例為
地端 (On-Premise)Linux (Ubuntu 16.04) 為例。
幾段隨筆,談 IoC / DI 與管理的想法。
以下這張照片是 Jan, 2015 在 AWS Virginia Data Center 火災的照片:

圖片來源: Amazon data center on fire in Virginia - CNN
其實災難,不管是個人還是在企業,隨時隨地都有可能發生。當企業成長到一定的規模,災難還原計畫,就越來越重要。但是做災難還原準備工作,本身在公司裡面不是所謂的 產出 任務,他屬於 備援 計畫,而且災難復原在傳統的 IT 架構裡,所需要的預算、人力、資源、時間是相當龐大的,大部份的老闆,對於這件事情是不會支持,或者也不太願意投資的。最多做所謂的 異地備援 就算是很不錯的了。
以下整理 Whitepaper - Using AWS for Disaster Recovery (Oct, 2014) 內容。大部份的圖檔都是文件裡擷取出來。
整理 Linux 效能工具 top 的一些資訊,範例是在 ubuntu 16.04, AWS EC2 c5.large 上的資訊。