Mini PC 效能實驗:實測 Throughput / RPS / C10K
在 《如何量測系統的容量?》 一文有提到量測的方法與概念,開頭提到思路有三種,其中 「第二個思路:以系統資源做基準值,找到理想值 / 基準值」 是該文章主要提供的論述。類似概念我在工作上也很常使用,去年 (2025) 在高雄師範大學分享的 《從應用程式 Inside-Out 出發的 Web 可靠性設計》 概念,其實本質也是類似。
去年 (2015) 記憶體還沒漲價前,我買了幾台 Mini PC,規格大概是記憶體 64GB、SSD 2TB、Ethernet 1Gbps 的規格。這主要是我的 HomeLab 的 Lab Machine,用來做各種實驗,取代原本在 NAS 上跑 VM、《學習 K8s (kubeadm 手動安裝)》,這用法曾在 《資料備份還原 - 第一原則 資料分層》 提到的。
買了 Mini PC 除了跑現在流行的龍蝦、或者開發我個人工具,「效能」與「資源」之間的平衡,一直是我很有興趣的題目。自從搞定 《從應用程式 Inside-Out 出發的 Web 可靠性設計》 裡提到類似 《AWS DynamoDB》 RCU / WCU 的 Capacity Unit 設計與實作,我對於如何「榨乾」眼前的硬體資源,取得效能極致與最佳化,一直是很感興趣的。像是 “Let’s Handle 1 Million Requests per Second, It’s Scarier Than You Think!“ 這樣的題目,這是 《如何量測系統的容量?》 提到的 「第一個思路:業務導向」,從業務目標尋找需要多少資源。
我想要知道幾件事情:
- 1Gbps 網路的理論值與實際值的差異
- 基於 1Gbps 頻寬,REST API 的 Payload Size 1KiB / 10KiB / 100KiB,可以打到多少 RPS?以及 CPU 與使用率。
- 承上,內觀的來看,Payload Size 與 RPS / Concurrency / Connection / Latency 之間關係?
- 基於 1Gbps 以及 MiniPC 的硬體規格,c10k 實測的狀況,能再上去?極限會是多少?瓶頸在哪?
整個量測的執行第一次透過 Codex 運行、第二次我手動執行,結果主要透過 ChatGPT 整理,Gemini Pro 為輔。
實驗最後預期會得到一張表,成為 Backend Server Stack 效能上限值,這張表可以作為大部分 Backend Server 量測容量的基準線 (Baseline),或者理想值。
註一:為了不要讓文章看起來 AI 味,原則上不使用 AI 文字。但是這種實驗數據的整理,其實 AI 生圖反而很適合。權衡之下,我在實驗結果章節,用 ChatGPT / NotebookLM 整理幾張圖總結。
註二:Concurrency翻譯使用並行非併發
背景條件
這兩台 Mini PC 規格如下:
ASUS NUC: Ultra 7 255H (8c16t) / 64G / 2TB SSD / 1Gbps / NTD: 28KXULU XR1: AMD Ryzen 7 5825u (8c16t) / 64G / 2TB SSD / 1Gbps / NTD: 20K


實驗環境 (HomeLab):
- 兩台 Mini PC 透過 UniFi Giga Switch 連線,過程中沒有其他干擾因素
- 兩台 Mini PC 的控制連線 (Macbook Pro) 走 WiFi 進去,Client / Server 實測連線則走 Ethernet
- 兩台 Mini PC 作業系統都是 Ubuntu 24.04,同時並沒有特別調整過相關參數 (ex: ulimit, fd)
背景資訊: C10K / IO Model
C10K 是「一台伺服器能不能同時維持一萬個連線」的經典問題。這裡的連線通常指 TCP connection,不一定代表每個連線都在高速傳資料,而是大量 client 同時連上 server、保持連線、偶爾送出請求。
早期 Web Server 常用 一個連線對應一個 thread/process 的模型。當連線數變多時,OS 需要管理大量 thread、context switch、記憶體 stack、file descriptor,CPU 還沒真正處理業務邏輯,就先被 排程 與 I/O 等待拖垮。
C10K 的核心挑戰不是「頻寬不夠」,而是 如何有效管理大量空閒或低流量連線。後來 Linux epoll、BSD kqueue、事件驅動架構,以及 Nginx、Netty、Node.js、Go runtime 等技術成熟後,C10K 已經不是特別困難的問題。
現在業界更常討論的是 C100K、C1M,或在大量連線下同時處理 TLS、低延遲、Rate Limit、觀測性 與 資源隔離 (Isolation)。簡單說,C10K 現代高並行應用的基本入門。現代 Backend Stack (API Server / RDB / Cache / Queue) 處理的概念,就有點類似 I/O Models 的目的:讓 CPU 利用率更高的方法。 《從應用程式 Inside-Out 出發的 Web 可靠性設計》 分享的設計概念,則是透過 Capacity Unit 的概念,讓 CPU 利用率更高。
推論方法
實驗的推論方法是這樣的:
基於已知的
固定因子 (Fixed Factors),定義理想值 (Theoretical Ideal),透過實測過程,找尋變動因子 (Identify Variables),透過實驗矩陣 (Experimental Matrix)找出數學模型 (Mathematical Models),決定變動因子那些屬於可控變因 (Controllable Factors),最後找到三者之間的關係、或者最佳化配置 (Optimization),或者效能邊界 (Performance Boundaries)。
我覺得 變動因子 不等於 可控因子。實際上實驗過程,在 實驗矩陣 的執行過程與結果,探索出變動因子。但變動因子是否成為實驗目的的可控因子,則需要在過程中,透過實驗矩陣的產出與輸入,找到其 數學模型,最後變動因子才會變成可控。
上述句子有點不太容易懂,我請 NotebookLM 幫我整理成比較容易懂的版本:
實驗的主要目的是在既有的硬體與網路環境下(固定因子),先為系統設定一個效能的『理想目標』。隨後透過實測,藉由改變封包大小與連線數等條件(可控因子),觀察系統何時會達到極限,進而釐清各種設定與最終效能之間的連動關係,找出最符合經濟效益的最佳化配置。
可能還是看不懂 XDD
底下是實驗過程找到的固定與變動因子整理。
固定因子 (Fixed Factors)
為了確保效能瓶頸的分析不受外部或應用層次的無謂干擾,設定了以下固定因子:
- 硬體設備與作業系統:
- Server Side: AMD Ryzen 7 5825U (16 CPUs)、62 GiB RAM 的 Mini PC (gtinfra02)。
- Client Side: Intel Core i7-1360P (16 CPUs)、62 GiB RAM 的 Mini PC (gtinfra03)。
- 兩台機器皆安裝 Ubuntu 24.04.4 LTS (kernel 6.17.0-29-generic)。
- 網路基礎設施:
- 兩台機器的實體有線網路 (Ethernet) 透過 UniFi Giga Switch 連結,頻寬為 1Gbps。
- 測試過程,流量嚴格綁定在實體的 Ethernet IP
- 實測過程的遠端管理與操作,則透過 Wi-Fi 連線,避開實體網路連線,降低干擾。
- Server 應用程式架構:
- 使用最小化的 Golang
net/httpServer 進行實作。 - Server 的行為固定為回傳預先建立在記憶體中的固定大小 (byte arrays),並給定固定的 Content-Length。
- 使用最小化的 Golang
- 排除的應用層變數:
- 為了單純測試網路與 HTTP Stack 的極限,明確排除了任何可能消耗 CPU 的業務邏輯,不進實作以下部分,以利找到理想值,包含:資料庫查詢、logging、資料壓縮、JSON 序列化、Payload 隨機生成,也排除了 TLS/HTTPS 的影響。
- 註:之後的 Lab 基於這次時間的數據,另外實測 API Server + RDB + Cache + Queue 完整 Stack 的實測,找到理想 RPS。
- 通訊協定行為:
- HTTP 測試階段皆預設依賴 HTTP/1.1 的 Keep-Alive 連線重用機制,以精準測試長連線下的系統狀態。
可控變因 (Controllable Variables)
為了找出系統在不同條件下的極限與瓶頸,實驗中操作了以下可控變因,也作為最後結果的參考依據:
- 負載大小 (Payload Size): 測試時將 API 回傳的 Payload Size 動態調整為 1KB、4KB、10KB 與 100KB 四個級別,用以觀察資料大小對 RPS (每秒請求數) 與網路吞吐量之間的關係。
- 並行連線數 (Concurrency):
- 將同時發起請求的連線數量從低到高進行調整 (包含 16, 64, 128, 256, 512, 1024),以觀察增加並行數對整體吞吐量以及排隊延遲 (p99 Latency) 的影響。
- 在 C10K 階段進一步將連線數推升至 1,000、5,000、10,000 甚至是 20,000 條。
- 請求行為模式 (Request Mode): 在大量連線 C10K 測試中,改變 Client 端的請求頻率,分為三種模式:
Idle: 建立連線後不發送請求,單純維持 keep-aliveLow-rate: 每條連線每隔 5 秒或 10 秒才發送一次低頻請求Active: 所有連線盡全力發送請求
- 系統資源限制 (OS Limits): 在探測極端高並行時,將作業系統的 File Descriptor (fd) 限制 (
ulimit -n) 從預設值大幅提升至 200,000,藉此排除 OS 限制干擾,讓測試能觸及真實的應用程式或網路瓶頸。 - 壓測工具種類:
- 根據測試階段的目的更換發壓工具,例如 Stage 0 裸網路測試使用
iperf3; - Stage 1 與 Stage 2 基礎 HTTP 測試切換為
wrk與oha(為了取得詳細延遲分佈); - 而在 C10K 階段則導入客製化開發的 Go C10K Client,以精細控制連線數與發壓頻率。
- 根據測試階段的目的更換發壓工具,例如 Stage 0 裸網路測試使用
- 測試持續時間 (Duration): 依據測試性質調整時間長度。
- 一般基準測試多設定為 10秒預熱、60秒正式壓測、10秒冷卻;
- 而 C10K Idle 或 Low-rate 測試則將維持時間拉長至 300 秒,以觀察長時間下記憶體與 CPU 狀態的穩定性。
預期結果
在執行這個實驗之前,我心裡對於結果的想像以及推論。整個實驗的項目共有四個,底下整理完整的內容。
Stage 0: 網路基準測試
主要目的是驗證底層實體網路能力,排除後續 HTTP 測試的干擾。
吞吐量 (Throughput) 極限:無論是單連線 (Single TCP)、反向傳輸 (Reverse TCP),還是多連線 (4 streams),預期都能穩定達到 900~940 Mbps,這也是 1Gbps 網路扣除表頭成本後的實際可用上限 (Usable throughput)。網路穩定度:預期封包重傳數 (Retransmits)為 0 或極低。- 若出現大量重傳,則推論為線材、Switch 或網卡驅動存在硬體層級的缺陷。
註:有朋友說,我使用的 扁的 CAT6 線,和 UniFi 設備之間可能會有問題。在工作上沒遇過,自己的設備用了幾年下來也沒有遇到問題。可能有,我不知道而已。
Stage 1: 最小化 HTTP 基準測試
引入 HTTP 協定與 Server/Client 壓測,推論不同負載大小 (Payload Size) 對系統瓶頸的初步影響。
小負載 (1KB Payload):- 預期一:900 ~ 940Mbps 頻寬約 112.5 ~ 117.5MB,換算下來 RPS 約落在
112,500 ~ 117,500(RPS ~= 11 萬),才會把 1Gbps 頻寬吃完 - 預期二:因為 Payload 小,處理數量多,因此系統會先撞到 CPU 運算能力或 HTTP Stack 處理成本 的瓶頸,也就是說屬於 CPU-Bound。整個瓶頸可能會在 CPU,而非網路頻寬。
- 預期一:900 ~ 940Mbps 頻寬約 112.5 ~ 117.5MB,換算下來 RPS 約落在
大負載 (100KB Payload):- 預期一:RPS 落在 1125 ~ 1175 就能達到傳輸極限
- 預期二:效能會直接卡在 網路瓶頸 (Network-bound) ,並與 iperf3 基準齊平的情境。
並行數 (Concurrency) 影響:- 初步推論在低並行下吞吐量可能不足但延遲穩定;
- 高並行可能提升吞吐量,但長尾延遲 (p95/p99 latency) 預期會開始惡化。
連線數 (Connection) 影響:- 建立連線數的多寡,會影響 RPS 與 Latency。
- 預期一:連線數越多,Latency 越大,RPS 也會越高
- 預期二:連線數越少,Latency 越小,RPS 也會越小
Stage 2: HTTP 矩陣測試
延續 Stage 1 的驗證,展開 實驗矩陣 Experimental Matrix:
Payload 大小 (1KB - 100KB)xConcurrency 並行數 (c16 - c1024)
找到效能邊界與關係。
1KB Payload:預期 RPS 最高,消耗的 Server CPU 資源最大,且需要較高的並行數才能將頻寬打滿,同時高並行會導致 p95/p99 延遲惡化。4KB Payload:預期比 1KB 容易打滿頻寬,且 CPU 消耗會隨之降低。10KB / 100KB Payload:- 預期在低到中等並行數 (如 c16) 即可輕鬆觸及物理網路極限 (Network-bound)。
- 超過這個平衡點後,盲目推高並行數將無助於提升吞吐量,只會引發嚴重的排隊效應 (Queueing),讓延遲數據變得極差。
Stage 3: C10K 連線測試
將 c10k 一萬條連線拆分為三種情境,推論系統在極端連線數下的資源消耗與崩潰點。
C10K-Idle (閒置連線):- 預期可以在兩台 Mini PC 間順利建立 10,000 條 Keep-alive 連線,CPU 消耗很小、每條連線佔用 20KB 記憶體,記憶體總共消耗約 209MB
- 主要風險與瓶頸將推論為作業系統的 File Descriptor (fd) 與 Process 兩者的限制。
- Client and Server 沒有調整 ulimit 時,會收到作業系統報錯
os error 24
- Client and Server 沒有調整 ulimit 時,會收到作業系統報錯
C10K-Low-rate (低頻請求):- 低頻請求:維持 10,000 條連線,並且每條連線每 10 秒發送一次請求(總計約 1,000 QPS)。
- 測試成功率為 100%,p99 延遲極低,僅 1.00 ms,Server CPU 微幅上升,記憶體微幅上升
- 思考:這現象類似於 IoT 設備的 Heart Beat 定期回報。
C10K-Active (活躍滿載):- 活躍滿載:讓 10,000 條連線同時發送請求。
- 10KB Payload:預期 RPS 約在 11K (同 Stage 1 推論),但 p99 延遲會增加,CPU 消耗也會增加
- 100KB Payload:預期 RPS 1K (同 Stage 1 推論),但 p99 延遲會標高到數秒以上,但 CPU 消耗比 10KB 的低,因為都在做 Network I/O
。 - 推論:在活躍滿載的狀況,會出現
排隊效應 (Queueing),效能瓶頸已經不是連線數 (c10k)、或者頻寬以及吞吐量,而是如何有效處理任務,這會帶出現在分散式系統的架構議題:限流 (Rate Limit) 架構。這個概念就是我在 從應用程式 Inside-Out 出發的 Web 可靠性設計 演講中提到的設計方法。
突破 C10K (Beyond C10K, 如 20k/50k):- 預期如果往兩萬甚至五萬連線邁進,最先卡住的將不再是 Go Server 的應用程式限制,而是 Client 端作業系統的限制,例如 單一 IP 的臨時通訊埠 (Ephemeral ports) 範圍耗盡,或是 TIME_WAIT 狀態未釋放導致的資源枯竭。
實驗紀錄
錄影
底下錄影是我手動執行過程的錄影,影片約 30 分,只是我自己做個紀錄。
- Stage1: http-baseline (20260520_3)
- Stage2: http-matrix (20260520_3)
- Stage3: c10k (20260519_2, v1)): 錄影中有些講錯,紀錄而已,不需要較真。
程式碼與紀錄
執行過程的 codex 寫的 source code,裡面有完整手動執行的步驟與環境設定。
實測結果
Stage 0: 網路基準測試
這個部分要確認的是硬體實際能處理的上限,驗證規格寫的數字。
1Gbps = 125MB/s
理論頻寬為 125MB/s,也就是吞吐量 (Throughput) 的理想值。
實測的結果:
測試結果顯示,不論是
單連線或4 Stream 並行、雙向 TCP吞吐量皆穩定達到941 Mbits/sec,Retransmits 為 0。這證明了低成本的實體網路環境極為穩定。
Stage 1: 最小化 HTTP 基準測試
這個部分測試 HTTP 傳輸的部分,直覺上會問 1Gbps 這樣的 RPS (Request Per Second) 會是多少?影響 RPS 背後的因素有幾個:
商業邏輯運算: 通常就是去 DB / Cache / Queue 拿資料、拿出來之後做各種計算合併商業邏輯、最後寫回去 DB/Cache/Queue,然後組成一個結果返回給使用者。回傳資料大小: 完成 1) 之後,要返回去資料大小就像是網路購物後,出貨包裹的大小,貨車或者航運能裝的數量是固定的。一次能運送的數量 (RPS) 包裹大小 (Payload Size) 就很關鍵。
第一個是大部分的人會著眼的重點,而第二個會被普遍的人忽略。這次的實驗反而不考慮 1) 的部分,只著眼在 2) 的結果,摘要如下:
| Payload Size | RPS | CPU Utilzation (16core) | Latency |
|---|---|---|---|
| 1KB | 101,000 | 382% | 450us ~ 1.2ms |
| 10KB | 11,000 | 7% | 800us ~ 2.5ms |
| 100KB | 1,000 | 13% | 3ms ~ 12ms |
上述結果,都有完全使用到頻寬,吞吐量是 Stage 0 實測的結果。
下面兩張圖則是 Gemini Pro 整理的摘要。
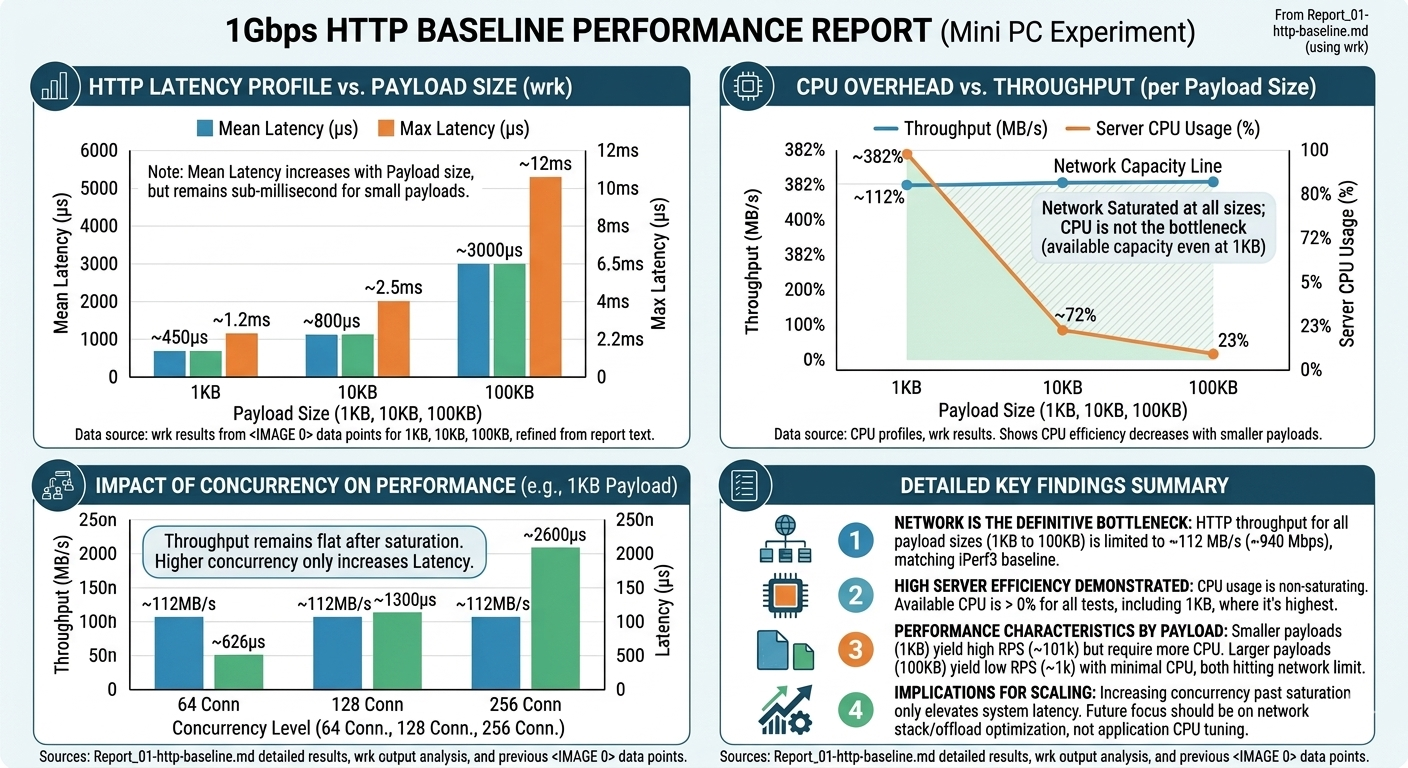
Stage 2: HTTP 矩陣測試
這個測試主要找到 Concurrency 與各種 Payload Size 的關係,同時也間接發現系統的極限,像是 File Description (FD) 與 Tcp 連線上限。
以結果來看,Payload Size 小,要拉高 RPS 做法是 Client 把 Concurrency 拉高,概念就是倉庫裡有很多小的貨物 (Payload Size),想要搬得快,就是派多人 (Concurrency) 同時處理,處理的速度 (RPS) 自然就快。但是 Server Side 的 CPU 會很忙就是了。
反之 Payload Size 大,Concurrency 拉高則沒有用,反而會因為競爭造成 Latency 變高。反而要保留時間讓 Server 好好把事做完。這在 《從應用程式 Inside-Out 出發的 Web 可靠性設計》 裡也得到實證,至於怎麼保證讓 Server 好好做事,就是關鍵設計了。
下圖是 ChatGPT 整理的摘要。
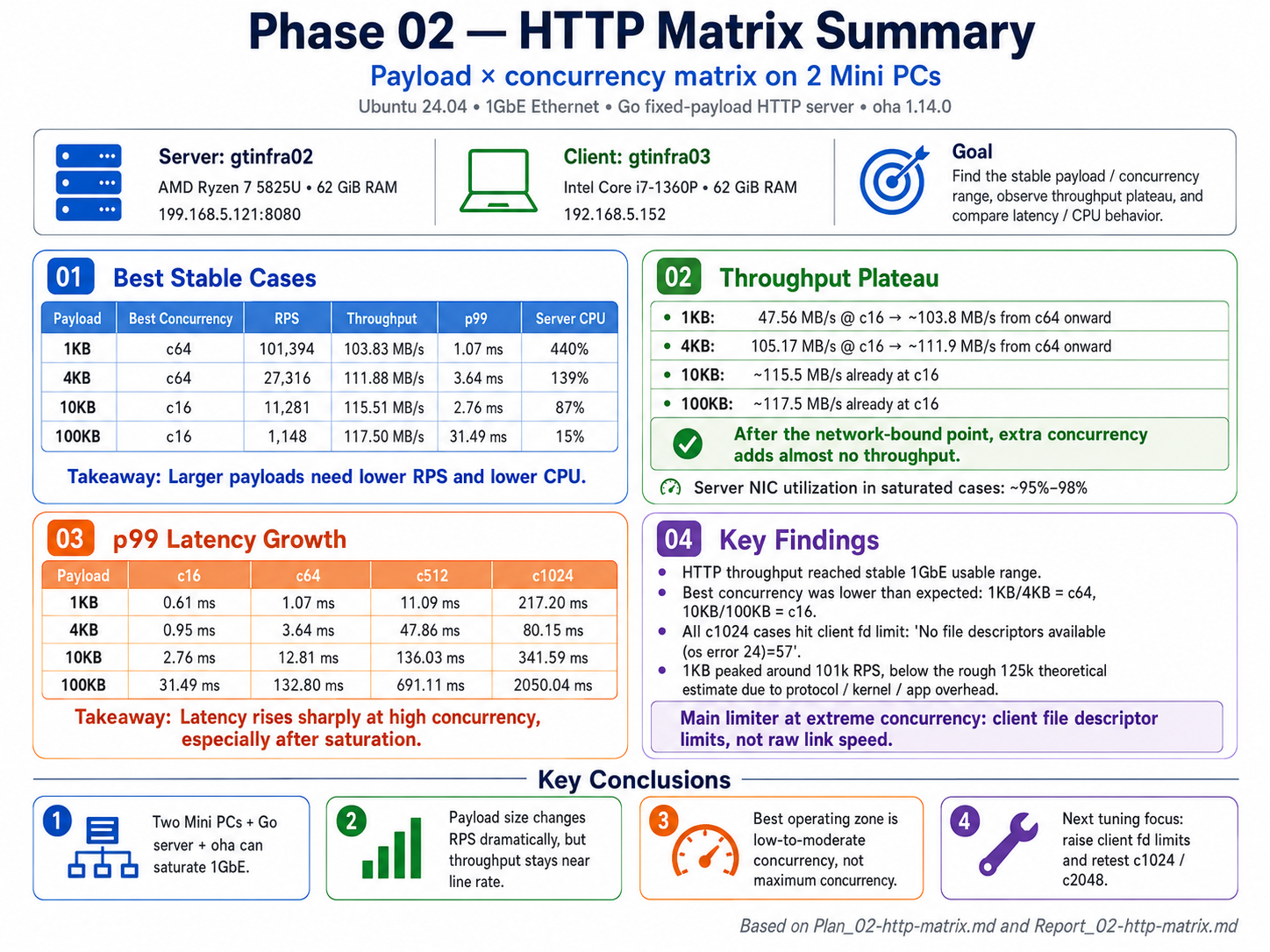
Stage 3: C10K 連線測試
C10K 結論簡單說,這兩台 Mini PC 對接狀況下,可以輕鬆做到 C10K,包含建立連線、以及連線後實際的請求。
其中建立連線,不送出請求狀況下,實測是可以到 C28k 就踩到 TCP 連線的限制,要再上去則可以透過其他方式 (ex: Server Side Multiple Port) 可以做到,剩下的問題就是維持連線需要的記憶體而已。
這個實驗可以繼續延伸側 C100K、C1M … 等,如果只是 idle connection / keep alive,實際上是不難,從實驗角度來講,就是在驗證 TCP 連線原理的理解與活用程度。但實務上來講,連線多,不等於可以同時處理業務邏輯 (搶票、搶購),所以往下要討論大多是 Backend 架構上的非同步、排隊、I/O Model 的架構設計了。撇除 商業邏輯,類似問題我想到的是 nginx 的實作,關鍵就在於 I/O Model 的部分,而不是在於建立多少 Connection。
下圖是由 ChatGPT 整理的摘要:
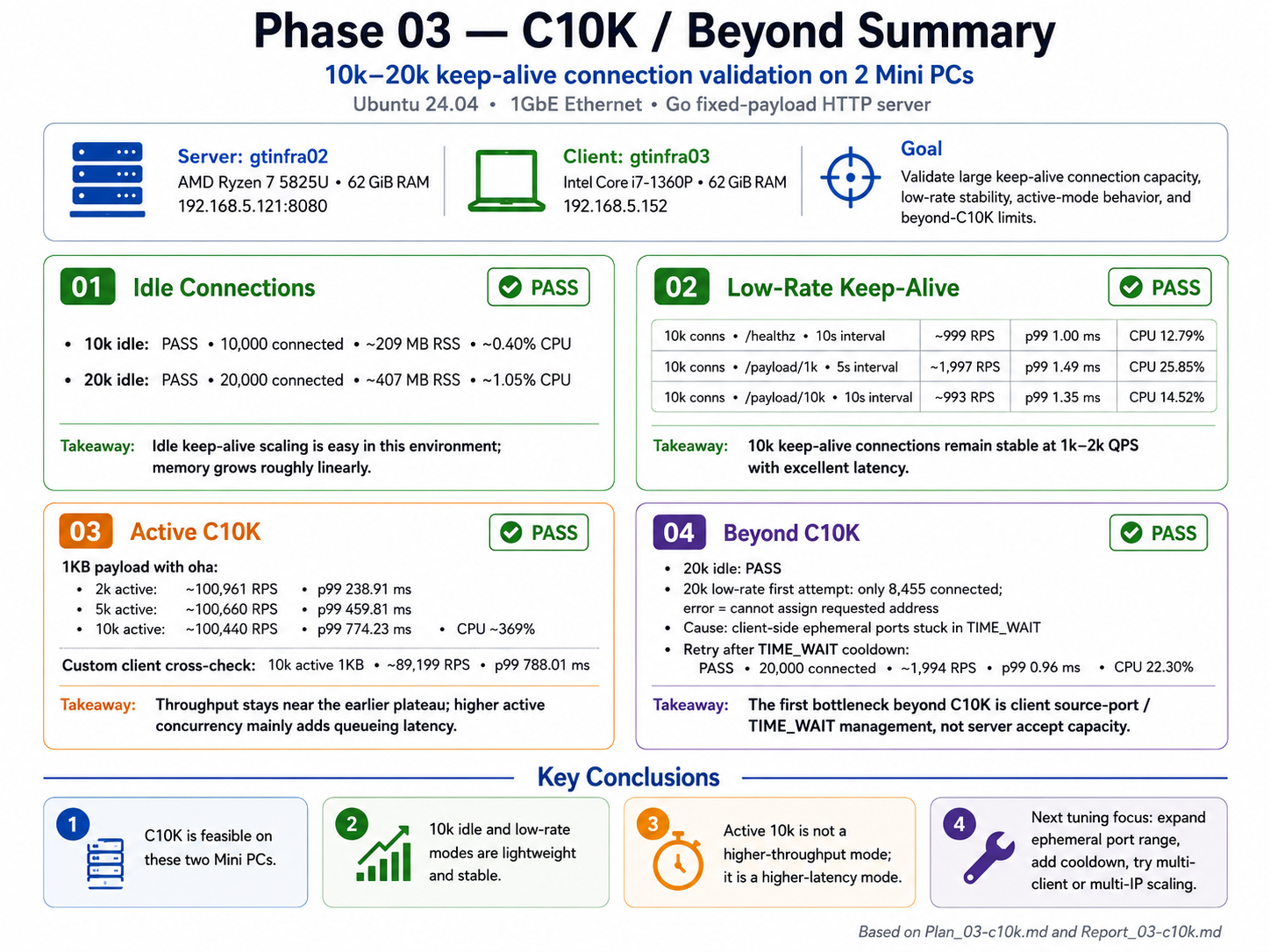
總結
數學模性
結論其實可以用 Throughput、RPS、Payload Size、Connection、Latency 之間的關係表示成一組很直覺的公式。核心可以寫成:
Throughput (T) = RPS (R) × PayloadSize (S)
當吞吐量是固定的,那麼 RPS 跟 Payload Size 成反比。
Payload 越小,RPS 越大。
Payload 越大,RPS 越小。
Connection 與 Latency 的關係,則可以用 Little’s Law (利特爾法則) 表示:
Concurrency (C) = Throughput (T) × Latency (L)
其中 Throughput 可以用上一個公式換算成 RPS / Payload Size。
所以當 Throughput 固定,Concurrency 增加,Latency 就會上升,對應到實測的數據是符合的:
c16 → latency 約 1.41ms
c32 → latency 約 2.83ms
c64 → latency 約 5.74ms
c128 → latency 約 11.48ms
c256 → latency 約 23.46ms
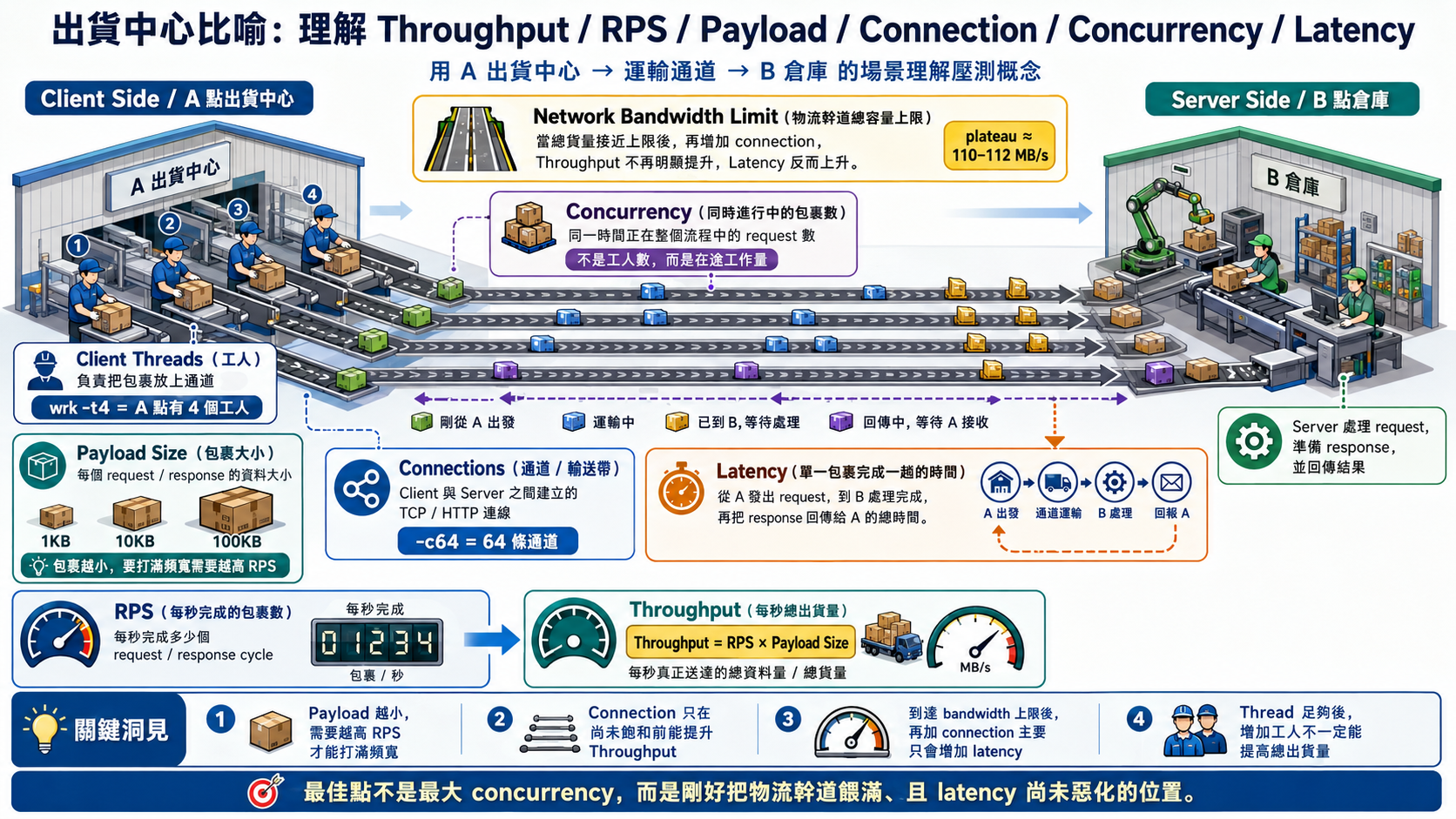
出貨中心
整個實驗出現幾個名詞:Thread / Connection / Concurrency / RPS / Latency / Throughput / Payload Size,我想像一個例子來解釋他們之間關係如下:
想像有一個出貨中心 A,要把包裹送到倉庫 B。
- Payload Size 是每個
包裹大小, - RPS 是
每秒完成出貨的包裹數。 - Throughput 是每秒真正送到 B 的
總貨量,因此:- Throughput = RPS × Payload Size
- Connection 是 A 到 B 之間可同時使用的
輸送帶 / 運輸通道。 - Concurrency 是
同一時間正在流程中的包裹數,包含正在輸送帶上、正在等待 B 處理、或正在等待回報結果的包裹。 - Latency 是單一包裹從 A 出發、送到 B、B 處理完成並回報給 A 的
總時間。 - Thread 則像 A 點負責把包裹放上輸送帶的
工人數。
我把結論翻譯成搬貨版:
包裹越小,要打滿整條物流幹道,就必須每秒丟出更多包裹。
包裹越大,即使每秒包裹數比較少,也能很快打滿物流幹道。
Connection 代表輸送帶:
輸送帶太少時,工人送貨速度會被輸送帶數量限制。
增加輸送帶可以提高每秒出貨量。但當物流幹道的總出口容量已經滿了,
再增加輸送帶不會讓總出貨量變高,
只會讓更多包裹卡在路上,導致每個包裹等待更久。
Thread 部分:
如果工人已經足夠把輸送帶餵滿,
再增加工人也不會增加總出貨量。
真正的瓶頸已經變成物流幹道的總容量,
不是工人數。
下表整理整個概念的解釋:
| 分層 | 技術概念 | 搬貨比喻 |
|---|---|---|
| Client Side | wrk thread (-t) |
A 點工人數 |
| Client ↔ Server | connection (-c) |
A 到 B 的輸送通道 |
| Client ↔ Server | concurrency |
同時正在流程中的包裹數 |
| Payload | payload size |
每個包裹大小 |
| End-to-end | RPS |
每秒完成出貨的包裹數 |
| End-to-end | latency |
單一包裹完成 A→B→A 的時間 |
| End-to-end / Network | throughput |
每秒完成運送的總貨量 |
| Network | bandwidth limit |
物流幹道總容量上限 |
下圖則是把比喻的想法讓 ChatGPT 畫一張概念圖,完整解釋相關名詞以及整個過程:
NotebookLM 整理
底下 PDF 是由 NotebookLM 整理的簡報,或許更容易理解吧!
小結
這個實驗,我在思考的第一性原理,以及背後目的:
- 這兩台機器的成本約 新台幣 50,000 元 (28k + 20k),撇除硬體可靠性問題,他們能否真的當 Server 使用?
- 28K 那台 Mini PC 現在已經漲到 68K 了 …
- 實際的流量跟業務價值有個對價關係,業務價值則跟收入有個關係
價值 5 萬塊錢的基本算力,在最單純的條件之下,不包含網路成本、網路設備成本、人力成本,大概可以處理多少 價值。
當然實際上在業務場景,這樣的考慮實際上是不夠的。但是用同心圓的思路,工程要考慮的事情,就是讓現有資源做到資源利用率的最佳化 (Optimization),這才是真正的價值!
如果是完整的 Backend Stack (API Server + RDB + Cache + Queue),那麼極限值其實已經知道了。
窮和尚與富和尚
文章開頭提到的 「第二個思路:以系統資源做基準值,找到理想值 / 基準值」,就是我常說 窮和尚與富和尚取經 的故事:
四川的邊遠地區有兩個和尚,一個窮,一個富。
有一天,窮和尚對富和尚說:「我想到佛教聖地南海取經,你說行不行?」
富和尚問:「來回好幾千里地,你靠什麼去呢?」
窮和尚說:「我只要有一個喝水的瓶子,一個吃飯的泥盆就行了。」
富和尚聽了哈哈大笑,說:「幾年以前,我就下決心要租條船到南海去取經,但是,憑我的條件,到現在還沒能辦到。你靠一隻破瓶子、一個泥瓦盆就要到南海去?真是白日做夢!」
一年以後,富和尚還在為祖賃船隻籌錢,窮和尚卻已經從南海取經回來了。
用最少資源,做到最大的價值!
延伸問題
礙於篇幅與長度,底下問題先保留,簡單整理問題的想法,之後有空再整理成獨立篇章。
- Q1: 只用這兩台 Mini PC 可否突破 C10K?例如 C1M,如果可以,為什麼?要怎麼做?
- A: 技術上可以,但維持連線的成本以及效益要思考。
- 更實務的想法是
如何最有效的處理請求(排隊、非同步),而不是單純看 Concurrency (Client)、Connection (Client / Server)、RPS 這些表面的指標。這整個核心概念就是 《從應用程式 Inside-Out 出發的 Web 可靠性設計》 分享時的核心概念。
- Q2: 為什麼不用 cURL 當 client 測試 C10K?
- A: cURL 的 HTTP request 一次就是一條 TCP 連線,是間歇性的連線,跟 C10K 持續性的 Concurrency 意思不一樣。
- Q3: TCP 的連線數受限於 65535 的上限,在單機如何突破這個數字?
- 簡單說:Server Side 開兩個 Port 就可以突破,接下來問題會是需要多少記憶體維持這些連線。)
- 實測 Connection 數量開到 50,000 (ulimit 開 200,000) 就會出現這樣訊息:
connecting target=192.168.5.121:8080 connections=50000 mode=idle endpoint=/healthz connected=28232 connect_errors=21768,其中 28232 代表連線成功,21768 連線失敗,代表已經踩到上限。TCP 每一條連線是由 4 bytes 組成唯一識別:<src_ip:ephemeral_port>:<dest_ip:dest_port> - Q3 的結論其實已經回答了 Q1 的問題
- Q4: 這個實驗其實跟 Disk I/O,以及 IOPS 概念其實很像
K8s 內部頻寬
我在 《學習 K8s (kubeadm 手動安裝)》 時,曾經做過一個吞吐量的實驗,結果有保留 (如下圖),但沒有整理過程。
這個測試的是 兩個 pod 裡面透過 iperf 測試吞吐量,情境有兩種:
- pod in the same VM
- pod in different VMs
- 第三個變因:不同的 KVM, proxmox vs QNAP VM Station
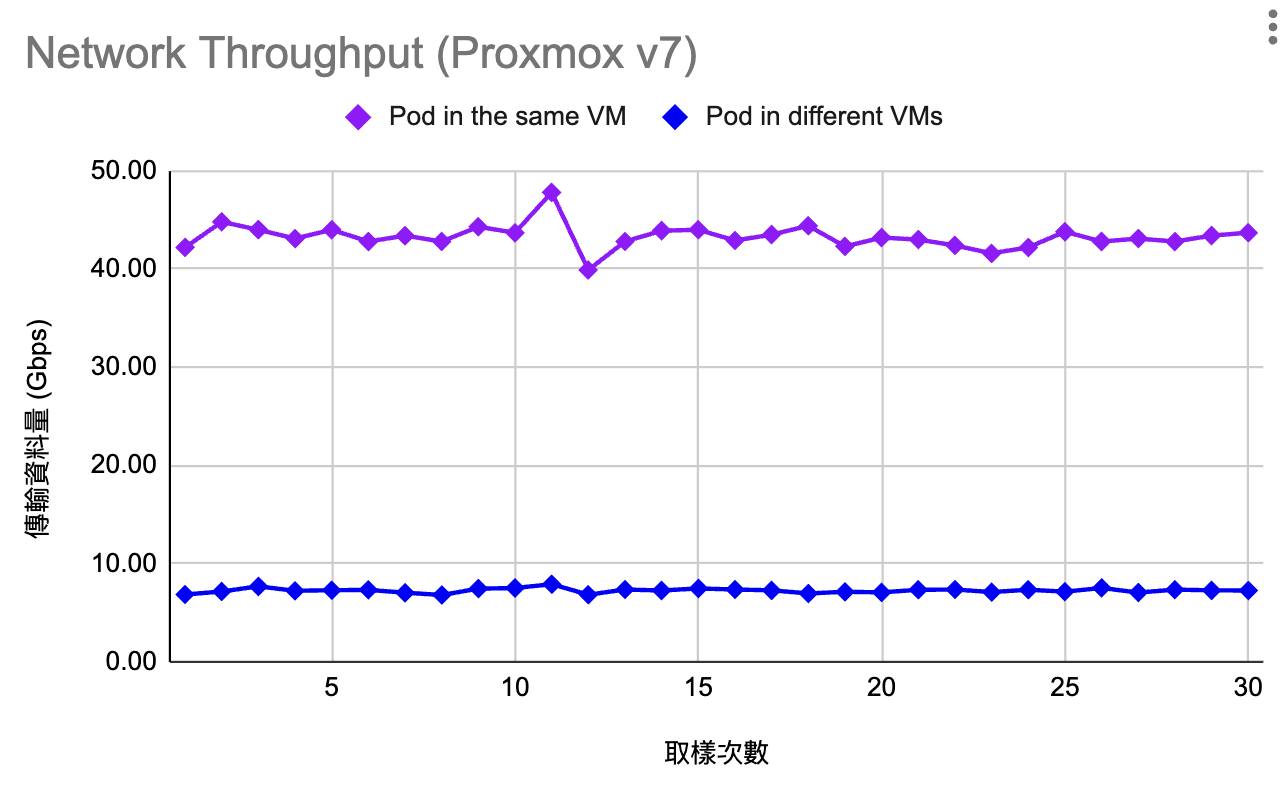
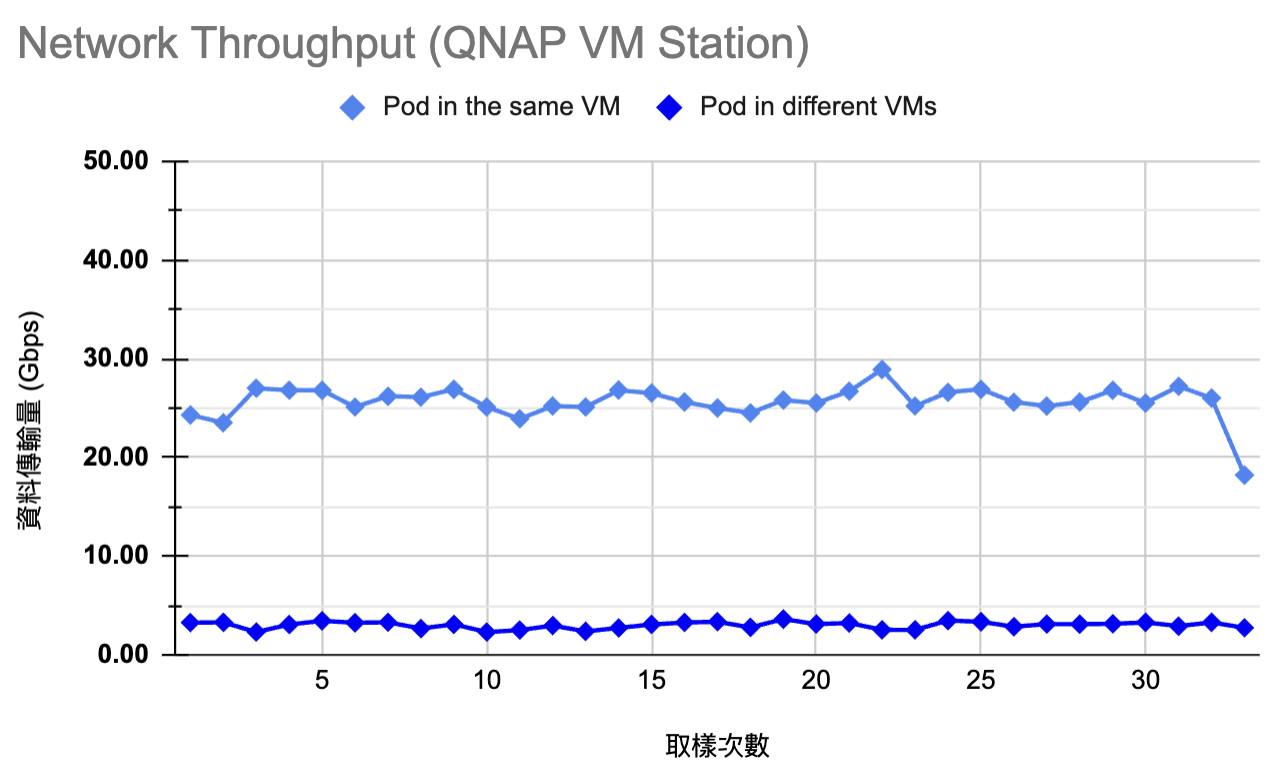
這個結果很有趣。
在做這個實驗時有想到,但從結果論來看,我想到的是另一個問題:
為什麼虛擬網卡的吞吐量可以那麼高?
這就回到我在 《自幹作業系統》 裡有實作的部分 - 網路,回去看當時寫的 Source Code 發現,這或許跟記憶體頻寬有關係,因為在資料傳輸過程中,底層在做的其實在 Kernel 複製資料動作。
延伸閱讀
站內相關文章
- 如何量測系統的容量?(壓測)
- 共同著作《軟體測試實務 I、II》
- File Descriptor and Open File
- 資料備份還原 - 第一原則 資料分層
- K8s 學習筆記 - kubeadm 手動安裝
- Study Notes - DynamoDB 學習筆記
- 自幹作業系統 - Networking Fundamentals
- 自幹作業系統 - Simple OS
- Study Notes - I/O Models
工具
- Benchmark Tools
- 統計:
參考資料
Comments
About
著作
演講
- 演講錄影 @ Youtube
- 探索職涯、複利人生 - AWS Career Exploration Day 2023
- 個人著作 SRE 書友見面會
- 軟體測試實務 - 新書發表會
- 探索職涯、成就未來 - AWS Career Exploration Day 2022
- 從理想、到現實的距離,開啟品味軟體測試之路
- 91APP 在 AWS 上的 SRE 實踐之路
- 在矩陣型組織裡,如何有效管理 AWS 的成本結構與系統架構
- 災難演練 @ AWS 實戰分享
- 導讀持續交付 2.0 - 談當代軟體交付之虛實融合
- 聊聊軟體交付的濫觴 談產出物管理
- 從緊急事件 談 SRE 應變能力的培養
- 邁向 API 經濟 - API Gateway 導入之旅
- Monitoring Tools 大亂鬥 - AWS CloudWatch
- Ops as Code using Serverless
- 淺談系統監控與 CloudWatch 的應用
AWS Certifications


