自幹作業系統 - Task and Scheduler
自幹作業系統 系列的第三篇整理 初探 Timer 原理 探索筆記,本來是想帶到怎麼實作 sleep(),不過 sleep 其實只是一個小小的應用而已,真正的核心是 task.c 以及裡面的 schedule() (排程演算法) 這兩個概念,本文就以這兩個為主整理相關的學習筆記。
- Task 資料結構: 了解主要結構以及背景知識
- Task State Machine: 透過狀態機了解 Task 的狀態移轉
- Scheduler 的實作與設計: 用推演的方式整理排程演算法整個流程
避免篇幅過多,其中 Task 資料結構理會提到 Paging 和 Stack 之後再整理。
自幹作業系統 系列:
註:內容僅是自學的一些筆記,如果有發現資訊不正確,或者描述錯誤,請不令給予指教,感謝。
Task 資料結構
在 task.h 裡定義了一個 task_t 結構,這個結構包含以下特性:
- 環狀鏈結串列 (Circular Linked List): 主要是為了實踐
輪詢 (Round-Robin)機制,主要的屬性是struct task *next記錄著下一個 task 位置 - 進程控制區塊 (Process Control Block, PCB): 主要記錄的是 Process 的屬性,像是 PID, Parent ID (ppid), name, 累計的 ticks, 分頁位置 … 等
- 任務控制區塊 (Task Control Block, TCB): 包含 CPU 狀態 (esp), task 狀態, 以及等待的 Sub-Process PID.
esp: ESP 全名是 Extended Stack Pointer (堆疊指標暫存器) ,主要是記錄當前堆疊的 最高位址 或者說 最舊位址 。在排程器中,保存與替換esp是Context Switch的關鍵因素。除了 esp 之外,state: task 現在狀態, 用來控制排程行為。
底下是完整的資料結構:
1 | /** |
在 Simple OS 中,或者在 Linux 核心,可以把 TCB (Task Control Block) 與 PCB (Process Control Block) 兩個角色的結構當作同一個東西。但如果是 FreeRTOS 這種極輕量系統,PCB 是關於「資源的擁有權」,TCB 是關於「CPU 的執行權」。
Task State Machine
為了讓我自己可以更有效率了解整個實作,我用 【聊聊 API First 開發策略】 裡提到的 API 設計方法論 - 有限狀態機 的方法,整理如下圖:
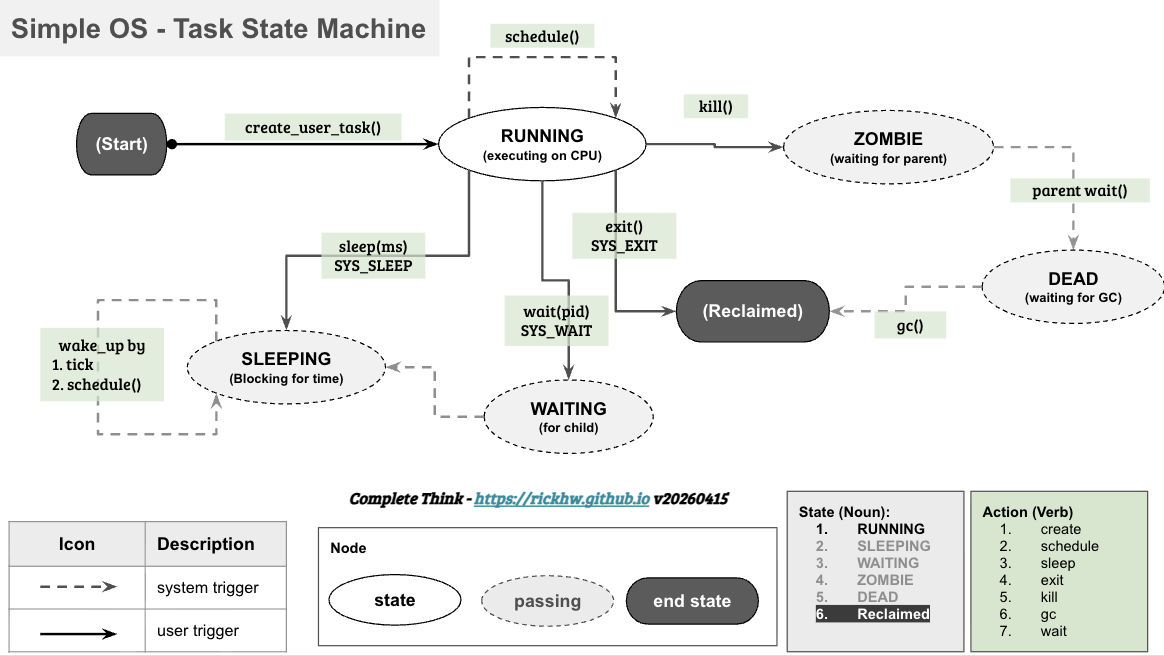
狀態包含以下:
RUNNING: 表示 Process 正在使用 CPUSLEEPING: 表示 Process 收到 sleep 指令、或者從等待中變成在睡覺WAITING: 表示 Process 正在等待下一個狀態ZOMBIE: 表示 Process 已結束,但父行程尚未 wait() 回收它DEAD: 表示 Process 已經結束了,準備被 GC 回收資源。還找得到資訊。Reclaimed: Process 已經被回收,已經找不到資訊。
而針對 task 處理的動作,定義在 task.h 則有以下:
- init_multitasking()
- create_user_task()
- exit_task()
- sys_kill()
- sys_sleep()
- sys_wait()
- sys_fork()
Scheduler
初始 [kernel_main] Task
整個 Simple OS 啟動的第一個行程叫做 [kernel_main, PID=0],這個 Process 標誌著從 Kernel Space 切換到 User Space 的橋接,透過交棒給 [shell, PID=1] Process 完成整個程序,把作業系統的主控權交給使用者。
註:目前 Simple OS 實作的版本還在單人多工狀態,大概類似於 DOS 吧 XDD
在原始碼中 main.c 主要的步驟如下:
1 | /// 略 ... |
整理狀態改變如下圖:
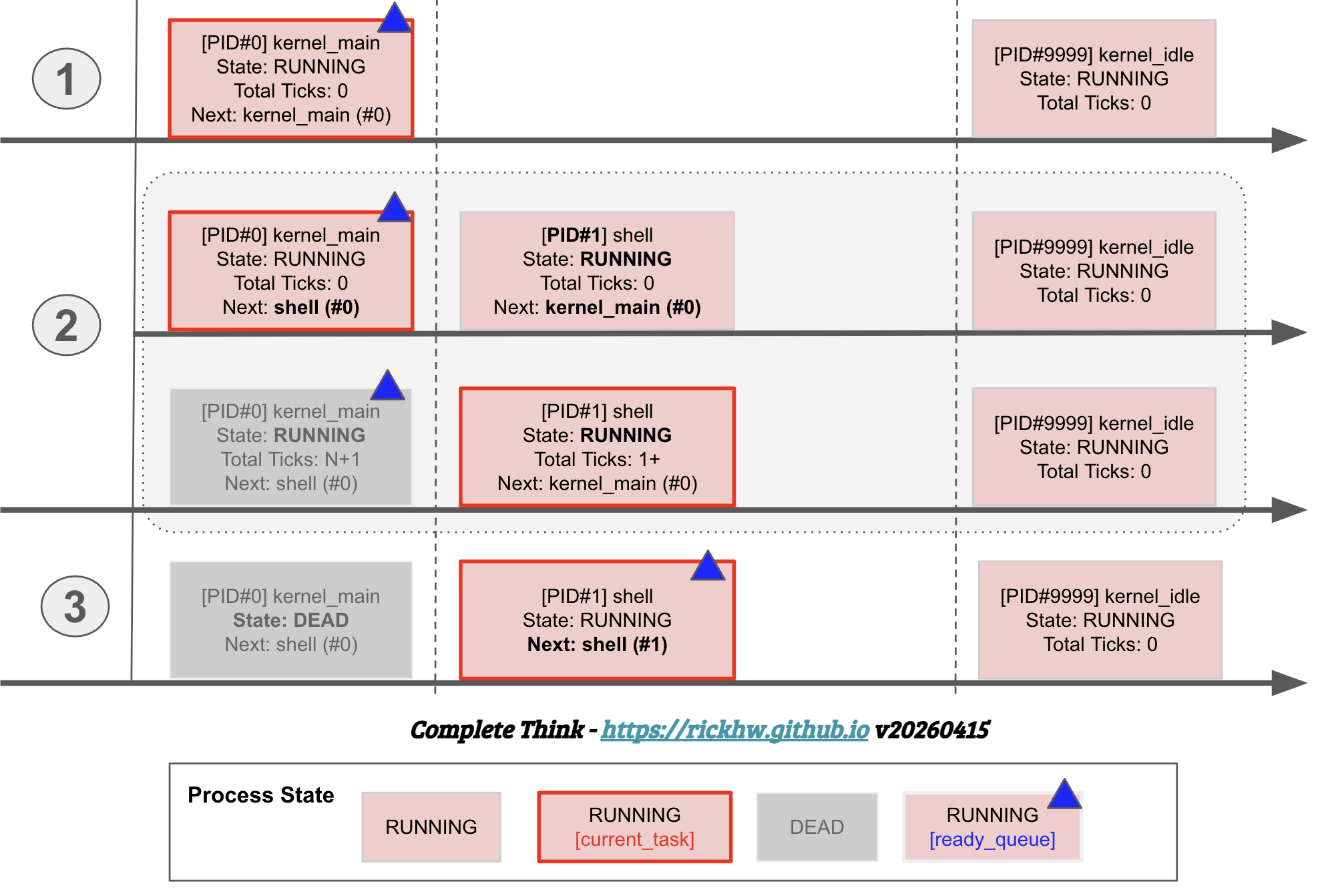
- (1)
init_multitasking(): 建立[kernel_main]process, PID=0、建立[idle_task]process, PID=9999, current_task 指向 PID=0核心任務 (Kernel Task):Kernel 啟動時第一個 Process (PID=0)。SimpleOS 裡的實作是完成 Shell 喚醒與交棒後,Kernel Task 就會自殺sys_exit(),然後被 GC 回收。閒置任務 (Idle Task):當系統無事可做時執行。當 Shell 也在等待輸入(WAITING)或睡眠(SLEEPING),且環狀串列中沒有其他任務在跑時,排程器會跳過死掉的 kernel_main,並因為找不到 RUNNING 的任務而切換到 idle_task 執行hlt(Halt, CPU 進入休眠直到下一個中斷)。
- (2)
create_user_task():- 2.1) 建立
[shell]process, PID=1, 這時候 current_task 還是指向 kernel_main - 2.2) current_task 指向
[shell]process,然後[kernel_main]狀態還是 RUNNING
- 2.1) 建立
- (3)
exit_task(): 執行 exit_task(),[kernel_main]狀態變成DEAD,等待下次 scheduler 執行時,會 GC 回收。
Preemptive Round-Robin Scheduling
排程演算法是作業系統裡非常核心的部分,Simple OS 實作最簡單、且容易理解的 Round-Robin (輪詢) 方法。下圖用三個正在執行的 Process,嘗試解釋 task.c#schedule() 如何透過 環狀鏈結串列 (Circular Linked List) 實現 公平 的時間分配。
- 步驟 1,2,3 代表 timer 每次計算的 tick,詳細參閱 初探 Timer 原理.
紅框 (current_task):是動態移動的,代表目前 CPU 暫存器裡正在跑的任務現場。
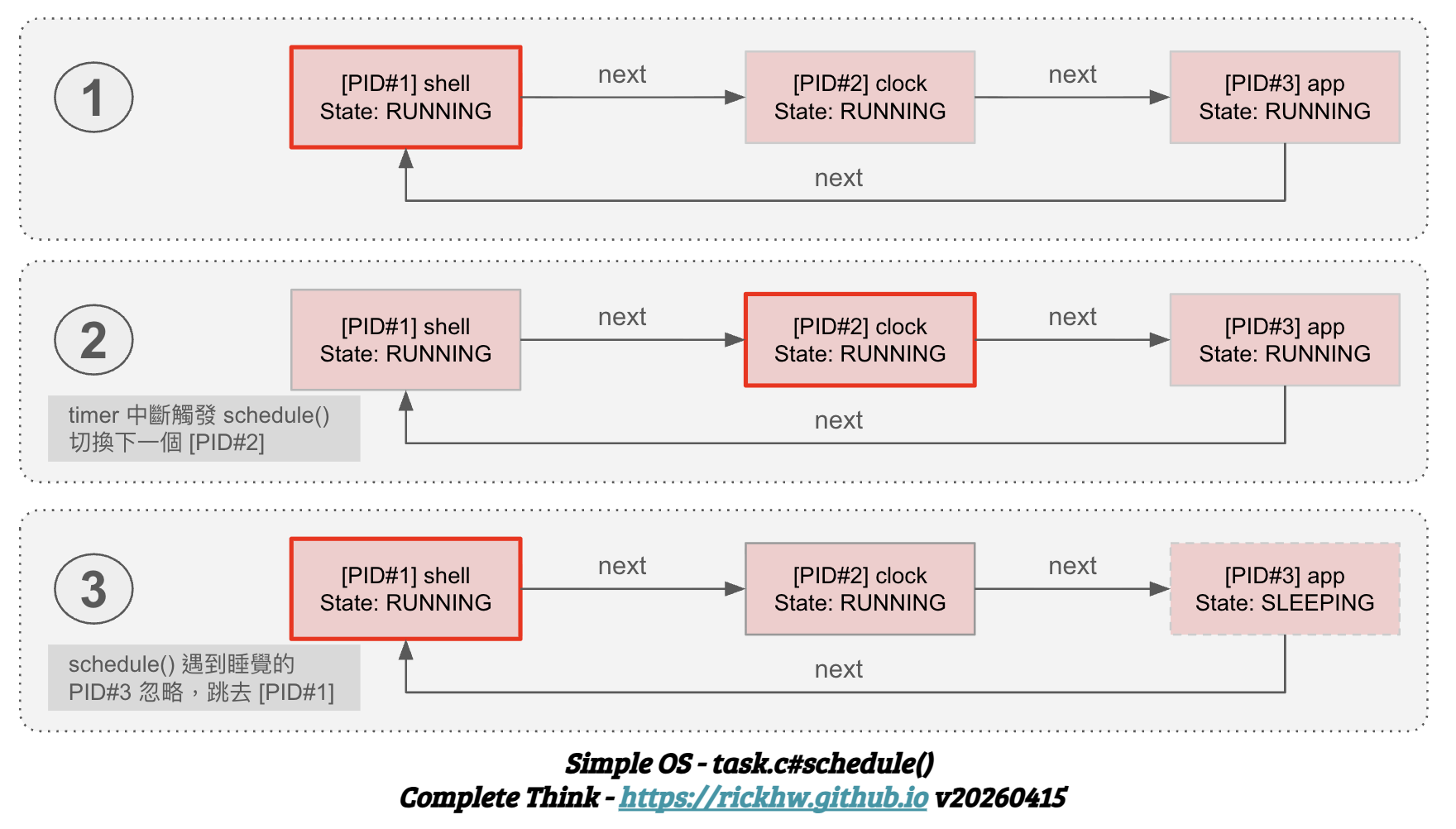
摘要上圖表示的重點:
環狀鏈結串列 (Circular Linked List):- 在圖中可以看到 PID#1 -> PID#2 -> PID#3 -> PID#1 三個 Process 的結構形成一個閉環。
schedule()每次執行的核心動作就是:next_run = current_task->next;。這就像是撥動轉盤,讓 CPU 的使用權傳給下一位。
公平執行 (Fairness):- 如 時刻 (1) 到 時刻 (2) 的變化。只要任務狀態是
RUNNING,排程器就會按順序分發時間片。 - 這確保了沒有任何一個任務會霸佔 CPU,這就是 搶佔式多工 (Preemptive Multitasking) 的精髓。
- 如 時刻 (1) 到 時刻 (2) 的變化。只要任務狀態是
狀態過濾 (State Filtering):- 當
schedule()指向到 PID#3 時,會執行程式碼中的while (next_run->state != TASK_RUNNING)檢查。 - 因為 PID#3 狀態是
SLEEPING(灰色虛線框),排程器會立刻再次執行next_run = next_run->next,直接跳過睡眠中的任務,把 CPU 交給下一個準備好的任務(PID#1)。
- 當
這套演算法雖然簡單,在 Simple OS 中卻是重要的核心架構,它保證了即便應用程式 sleep 在睡覺,shell 依然能靈敏地回應使用者的輸入。
問題
Q1: 當 Timer 的頻率為 100Hz,下跑 100 個任務,OS 會不會卡頓?
作業系統不會因為任務變多而邏輯崩潰,但會變得很「卡頓」。
1) 時間片的數學題:
init_timer(100) 意即 1s / 100=10ms,系統每 10ms 就會發出一次中斷,Round-Robin (RR) 演算法的輪詢過程,這 10ms 就是一個 時間片 (Time Slice) 。
- 如果有 10 個任務:每個任務每 100ms 就能輪到一次(10ms x 10 = 100ms)。人類感官會覺得還算流暢。
- 如果有 100 個任務:每個任務每 1 秒鐘才能輪到一次(10ms x 100 = 1000ms)。這意味著你點一下滑鼠,那個 App 要等 1 秒鐘才有機會被 CPU 執行 10ms。
2) 管理開銷 (Overhead):
真正的危機在於 Context Switch(上下文切換)的代價。每次 schedule() 執行時,CPU 都要:
- 保存舊任務的暫存器到堆疊;
- 呼叫
switch_task; - 切換分頁表(刷新 TLB,這很昂貴);
- 恢復新任務的暫存器。
假設上下文切換需要 0.1ms:
- 10 個任務:每 10ms 花 0.1ms 管理,損耗 1%。
- 100 個任務:管理成本依然是每 10ms 花 0.1ms,但累積起來的 延遲(Latency) 會讓使用者覺得系統當機了。
系統不會倒,但會發生 「Thrashing(抖動)」。當 CPU 跑管理程式(排程、GC)的時間比例過高,真正跑 User App 的進度就會趨近於零。
Q2: task.c#ready_queue 的用途是什麼?
task.c 裡 ready_queue 扮演的是**「錨點」與「主環入口」**的角色。
1. 作為環狀鏈結串列的「根」:
雖然 current_task 會在環裡面跑來跑去,但我們需要一個全域指標永遠指著這個環的某個固定點。
- 用途:當你要執行
task_get_process_list(如ps指令)或是task_gc時,你需要一個起點來遍歷整個環。如果沒有ready_queue,一旦current_task發生錯誤或遺失,整個進程鏈結都會在記憶體中「失蹤」。
2. 解決「Idle 迷航」問題:
- 情境:當所有任務都在
SLEEPING或WAITING時,current_task會指到 Idle Task。 - 問題:Idle Task 是獨立於環外的「降落傘」。如果沒有
ready_queue幫你記住主環在哪裡,當下一次中斷發生在 Idle 狀態時,排程器會因為idle_task->next沒有指向主環而無法喚醒任何人。
ready_queue就像是那個環的「存檔點」,確保排程器隨時可以跳回主要任務群進行掃描。
3. 管理任務的新增與刪除
- 新增:當
fork一個新任務,會把它插在ready_queue的後面。 - 刪除:當任務
DEAD時,task_gc會從ready_queue開始找,確保即便當前跑的是idle_task,也能正確清理主環裡的垃圾。
current_task 決定了 「現在是誰」,而 ready_queue 定義了 「我們總共有誰」。
目前 RR 演算法是「遍歷整個環」來找下一個。隨著任務變多,schedule() 的速度會越來越慢 O(N)。在現代 Linux 核心中,會將 ready_queue 改造成 Completely Fair Scheduler (CFS,完全公平排程演算法)來達到 log(N) 的效率。
註:CFS 實作為
紅黑樹 (Red-Black Tree),相關可以參閱 Linux 核心設計: Scheduler(2): 概述 CFS Scheduler 深入介紹。
排程演算法與專案管理
作業系統的 排程演算法(Scheduling Algorithms) 目的是面對多個行程 (Process) 時,如何有效的分配有限的 CPU 資源,分配 這件事情背後考慮的有: 最佳的系統效能、公平性 以及 反應速度 這三個切入點,不同的演算法,有不同的特性以及適用場景,底下整理常見的演算法的特性與優缺點:
先來先服務 (First-Come, First-Served, FCFS): 按照行程抵達的順序執行,不可搶佔 (Non-preemptive)、不可插隊。優點是簡單、且實作容易。缺點則是會產生護送效應 (Convoy Effect),大工作可能卡住後方所有小工作。最短工作優先 (Shortest-Job-First, SJF): 優先執行預估執行時間(CPU Burst)最短的工作。理論上平均等待時間最短,但是實務上難以預知程式實際執行的長度,且長工作容易產生飢餓現象 (Starvation),也就是有些 任務永遠沒機會執行。循環分時 (Round Robin): 每個行程分配固定的時間片 (Time Quantum),用完後換下一個。具備公平性,適合互動式系統。時間片設定太短會增加Context Switch負擔,因為需要反覆啟動以及回收記憶體、磁碟等資源,造成太大的 Overhead;時間片太長則退化成 FCFS。多層回饋隊列 (Multilevel Feedback Queue Scheduling, MLFQ): 將行程按優先權分類,並根據行為自動調整優先權(如:I/O Bound 的調高優先序,耗 CPU 者降級)。優點兼顧反應速度與系統吞吐量。缺點則是實作邏輯最為複雜。
在現實世界的作業系統中,排程器通常會根據不同的應用場景進行優化:
Linux 核心排程器 (CFS/EEVDF)CFS (Completely Fair Scheduler):Linux 目前主流排程器,強調任務間的「完全公平性」,利用紅黑樹結構來管理行程,讓每個工作都能獲得適當的執行比例。EEVDF (Earliest Eligible Virtual Deadline First):最新演化方向,旨在處理即時性要求(Latency-sensitive)更高的工作負載。更多參閱 Linux 核心設計: Scheduler(5): EEVDF Scheduler/1
雲端服務與容器化 (Cloud & Docker):在公有雲的虛擬機 (像是 EC2),排程器會感知 CPU Burst,在突發流量時臨時提供額外資源,避免因嚴格限制 (Throttled) 導致應用程式延遲。或者反過來,利用感知 CPU 的使用狀況,做到資源調度彈性的產品,像是 AWS t 系列的 EC2 就是這種產品。多核處理器與負載平衡:- 現代作業系統 (如 Windows, macOS) 會考慮
Processor Affinity,盡量讓同一個行程在同一個核心執行以利用 Cache,並動態平衡各核心的負載。
- 現代作業系統 (如 Windows, macOS) 會考慮
即時系統 (Real-Time OS, RTOS):硬即時 (Hard Real-Time):要求任務必須在 Deadline 前絕對完成,常見於導航系統或醫療設備。軟即時 (Soft Real-Time):優先執行關鍵任務,但不保證絕對死線。例如 Linux 中的 SCHED_FIFO 或 SCHED_RR 策略。
大概了解這些演算法的特性與實務上的應用,其實某種程度這些跟專案管理有著類似的想法。
有在使用專案管理系統 (JIRA, Redmine, Azure DevOps) 可能都曾經有以下狀況:
- 有些任務萬年沒機會做,像是架構改善、或者重構、測試自動化 … 跟 SJF 會出現的 Starvation 一樣。
- 所有的任務幾乎都是 MLFQ 模式,也就是根據優先序調整,但是優先序的權重,老闆每天都在調整。所以整個專案的狀況,很複雜
- 有些組織內部任務分工的性質就是 RR,像是客服、SRE、資安 … 等
- 排年度計劃時,放在 Q2/Q3 的,就會像是 FCFS,先搶到時間點,先做了。這些通常也都會是大的工作事項。
小結
作業系統的 Task and Scheduler 一直是我很有興趣的部分,因為我自己曾經從無到有探索、實作類似概念的東西,後來才知道原來這在作業系統裡本來就有。這一切可以追溯到我職涯很有成就感的作品之一: Designing Test Architecture and Framework。
當年這個架構就是在設計一個 動態資源分配器,然後把 自動化測試程式 部署到對應的運算資源,開始執行測試,這整個過程的的架構與框架。把每個自動化測試案例當作 Task,根據現在機器的資源狀況,動態分配到對應的機器上開始運行測試,最後結果全部匯總。整個過程的起點,就是像作業系統的 Task and Scheduler 在跑,有點像是 K8s 如何分配 Pod 在哪個 Node 上跑的過程。
2022 年,我在幫 朋友的書 寫 推薦序 時,書中針對 GitLab 寫下以下四件核心概念:
- 任務 (Task)
- 流程控制 (Flow Control)
- 事件驅動 (Event Driven)
- 分散式運算 (Distributed Computing) ,因此會帶來 分散式架構 議題
前面 1)、2) 就是在描述 作業系統的 Task and Scheduler 的概念,只是應用在軟體工程的 Pipeline。其他像是 電商的非同步任務系統 或者各種工作流系統 更是如此。
到這裡,不難感覺到, 自幹作業系統 一開始我一直反覆強調:資源分配與調度 。
AI?
這次不寫 AI 相關心得,用 Graphify 分析 SimpleOS Source Code 畫一張 Cover Image ~~ XD

延伸閱讀
自幹作業系統 系列
- Source Code
- Demo/錄影
- 專有名詞對照表
- 自幹作業系統 - Simple OS
- 自幹作業系統 - Networking Fundamentals
- 自幹作業系統 - 初探 Timer 原理
- 自幹作業系統 - Task and Scheduler
- 自幹作業系統 - Context Switch
站內文章
參考資料
- Linux 核心設計: 不只是執行單元的 process
- Linux 核心設計: Scheduler(2): 概述 CFS Scheduler
- Linux 核心設計: Scheduler(5): EEVDF Scheduler/1
Comments
About
著作
演講
- 演講錄影 @ Youtube
- 探索職涯、複利人生 - AWS Career Exploration Day 2023
- 個人著作 SRE 書友見面會
- 軟體測試實務 - 新書發表會
- 探索職涯、成就未來 - AWS Career Exploration Day 2022
- 從理想、到現實的距離,開啟品味軟體測試之路
- 91APP 在 AWS 上的 SRE 實踐之路
- 在矩陣型組織裡,如何有效管理 AWS 的成本結構與系統架構
- 災難演練 @ AWS 實戰分享
- 導讀持續交付 2.0 - 談當代軟體交付之虛實融合
- 聊聊軟體交付的濫觴 談產出物管理
- 從緊急事件 談 SRE 應變能力的培養
- 邁向 API 經濟 - API Gateway 導入之旅
- Monitoring Tools 大亂鬥 - AWS CloudWatch
- Ops as Code using Serverless
- 淺談系統監控與 CloudWatch 的應用
AWS Certifications


