軟體的熵,與我們真正在對抗的東西
Coding 表面上是在寫程式,本質上是在處理軟體工程的問題。而軟體工程的問題有一個容易被忽略的性質:
它隨時間累積,而且是複利式的熵增。
東西用得越久,會越往壞的方向走,變腐敗、變脆弱、變得難以動它。
差別只在於,是五天就壞光光,還是五年才壞光光。
先把兩個關鍵詞講清楚。
熵增與複利
熵增 簡單說就是「東西會自己變亂」。一張桌子、一個房間,你什麼都不做,它只會越來越亂;你從來不需要「努力」去把房間弄亂,但要讓它變整齊,卻一定得花力氣。沒人維護的系統也是這樣,放著不管,它不會原地不動,它會自己往亂的方向滑下去。
複利,則是「變化會疊在變化上面」,這次的產出,會是下次的基礎。我常用一個例子:
每天進步 1% 一年後進步 37 倍;反過來,每天退步 1%,一年後趨近於零。
軟體的好與壞都是這樣滾動的:
好的地基讓下一步更好走,壞的地基讓下一步更難走,差距只會越拉越開。
而所謂持續維運,不管掛的是 SRE 還是 Agile Team 的名字,目的其實都只有一個:讓熵增減速,把產品的壽命拉長。
由此看,軟體只服務兩件事。一是滿足商業需求,把價值交付出去;二是維持產品長久營運的管理工作。這兩件事,其實對應著生意的兩端:
增加功能,是為了把客戶帶進來;維護系統,是為了把客戶留下來。
帶進來,靠的是不斷交付新價值;留下來,靠的是系統夠穩、夠可靠、出錯夠少。不管是人寫 code 還是 vibe coding,做的都是這兩件。做得好,熵增慢,產品活得久、也更有韌性;做得差,熵增快,錯誤、故障、可靠性下滑接踵而來,客戶也就一個一個流失。
但我想把這個框架往下挖三層,因為挖完之後,它會更準,也更能解釋我們每天的處境。
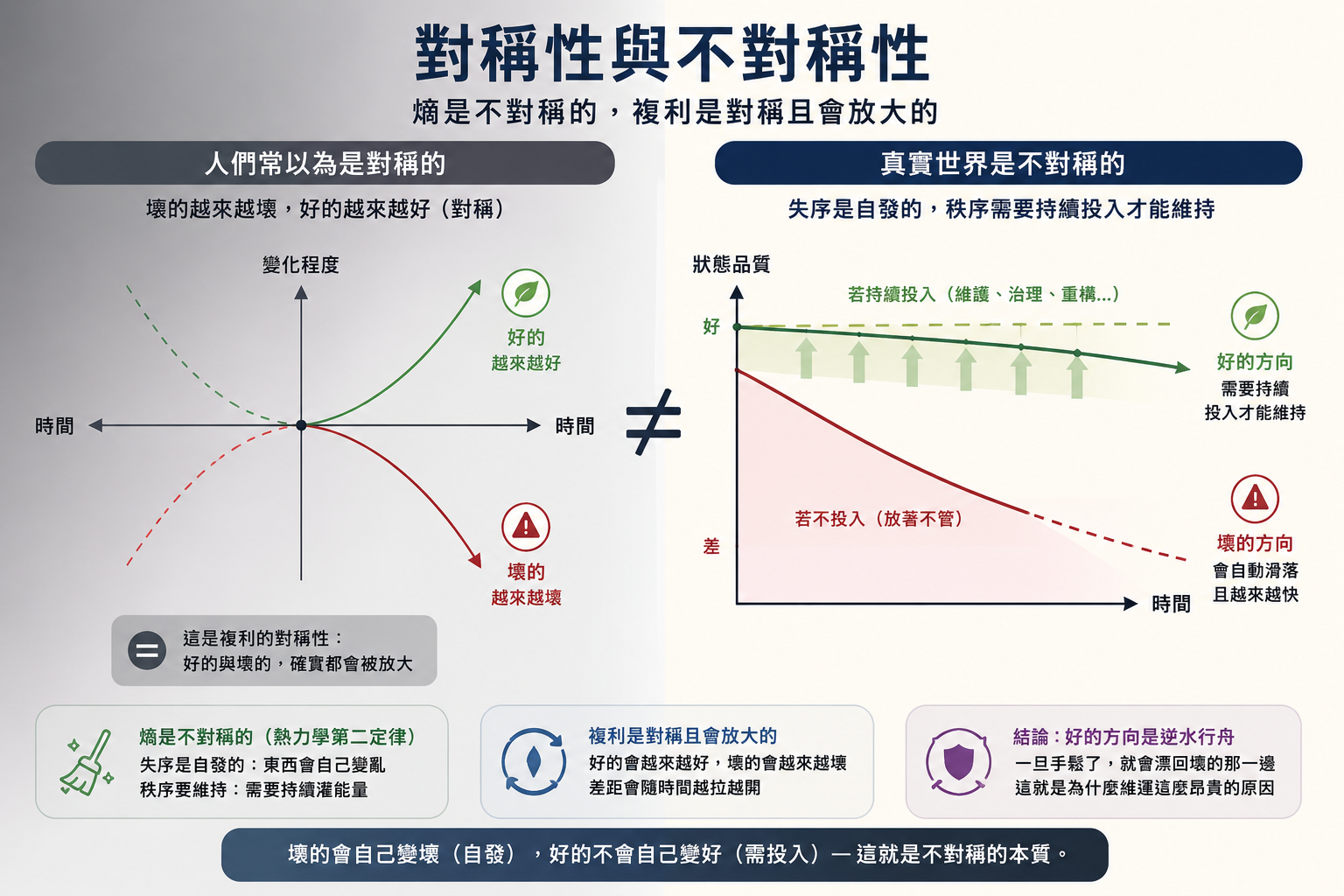
第一層:熵是不對稱的
複利這個比喻很容易讓人以為衰敗是 對稱的:
原本是問題就越來越嚴重,原本是好的就越來越好。
但這恰好是熱力學第二定律不允許的對稱。第二定律的全部重點,就在它的 不對稱性 :
失序是
自發的,秩序卻要持續灌能量進去才維持得住。
回到那張會自己變亂的桌子。桌子會自己亂,但永遠不會自己變整齊,這就是我說的 不對稱性。
所以「壞的越來越壞」和「好的越來越好」並不是同一種現象。壞的那一邊,有一部分是自動發生的 (環境在變、依賴在腐、耦合在長),再疊上一層人為的惡性循環:
爛地基讓人不想投資,而投資的成本又更高。
好的那一邊則沒有任何「自動」的成分。好的程式碼不會自己變好,它是因為好地基讓投資變便宜、回報變高,於是人「選擇」持續投入,才形成良性循環。
換句話說,這裡其實藏了兩個比喻:熵是自發、單向的;複利是雙向、會放大的。複利那一層是對的,良性與惡性循環都會被放大;但熵那一層提醒我們:
好的方向永遠是逆水行舟。一旦手鬆了,它就會漂回壞的那一邊。
這個不對稱本身,就是維運為什麼這麼昂貴的根本理由。
下圖是我把這段想法,丟給 ChatGPT 整理的概念:
第二層:腐敗來自內在與外在的落差
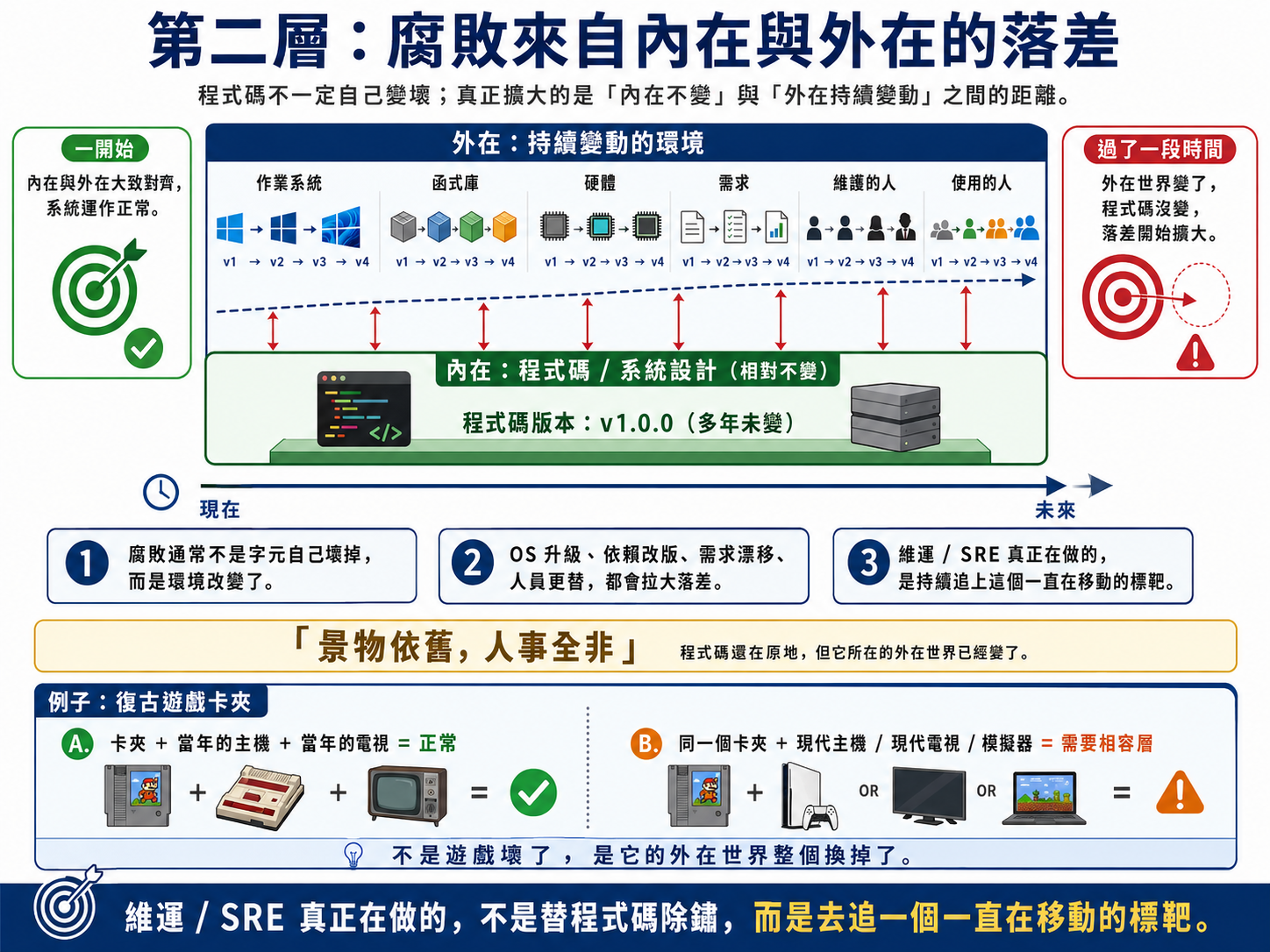
這裡要追問一個看似矛盾的問題:
一份 code 原封不動放著,字元一個都沒改,它為什麼會「壞」?
關鍵在於,要把系統拆成兩半來看。
一半是 內在,也就是程式碼本身;另一半是 外在,是它賴以運行的 環境:作業系統、函式庫、硬體、需求,以及維護它的那群人、使用他的那群人。腐敗幾乎從來不是內在自己變壞,因為內在根本沒變。腐敗是內在的「不變」,撞上了外在的「一直在變」,兩者之間的落差越裂越大。
OS 升級了、依賴改版了、需求漂移了、團隊換了一輪人,而你的程式碼還停在原地。它不是生鏽,它是跟世界脫節。這概念就像在外地打拼的遊子回鄉的感概:
景物依舊,人事全飛。
舉個生活一點的例子。三十年前的遊戲卡夾,插進當年的主機,今天還是跑得好好的,因為內在 (卡夾) 和外在 (主機、電視) 一起被凍結了,落差不大。可是同的遊戲卡夾,你想插進現在的遊戲主機,用現在的電視、或用模擬器跑,麻煩立刻冒出來:不是遊戲壞了,是它的外在世界整個換掉了。
只有那種放在真實世界、被迫跟著外在一起變的系統,才受「複雜度持續上升」這條律支配;而被封進一個凍結環境裡的系統,並不會。
這個角度的價值在於,它改寫了「維運」的定義:
維運 / SRE 真正在做的,不是替程式碼除鏽,而是去追一個一直在移動的標靶。
底下由 ChatGPT 產生本段摘要:
第三層:當生產變便宜,價值會被逼到哪裡?
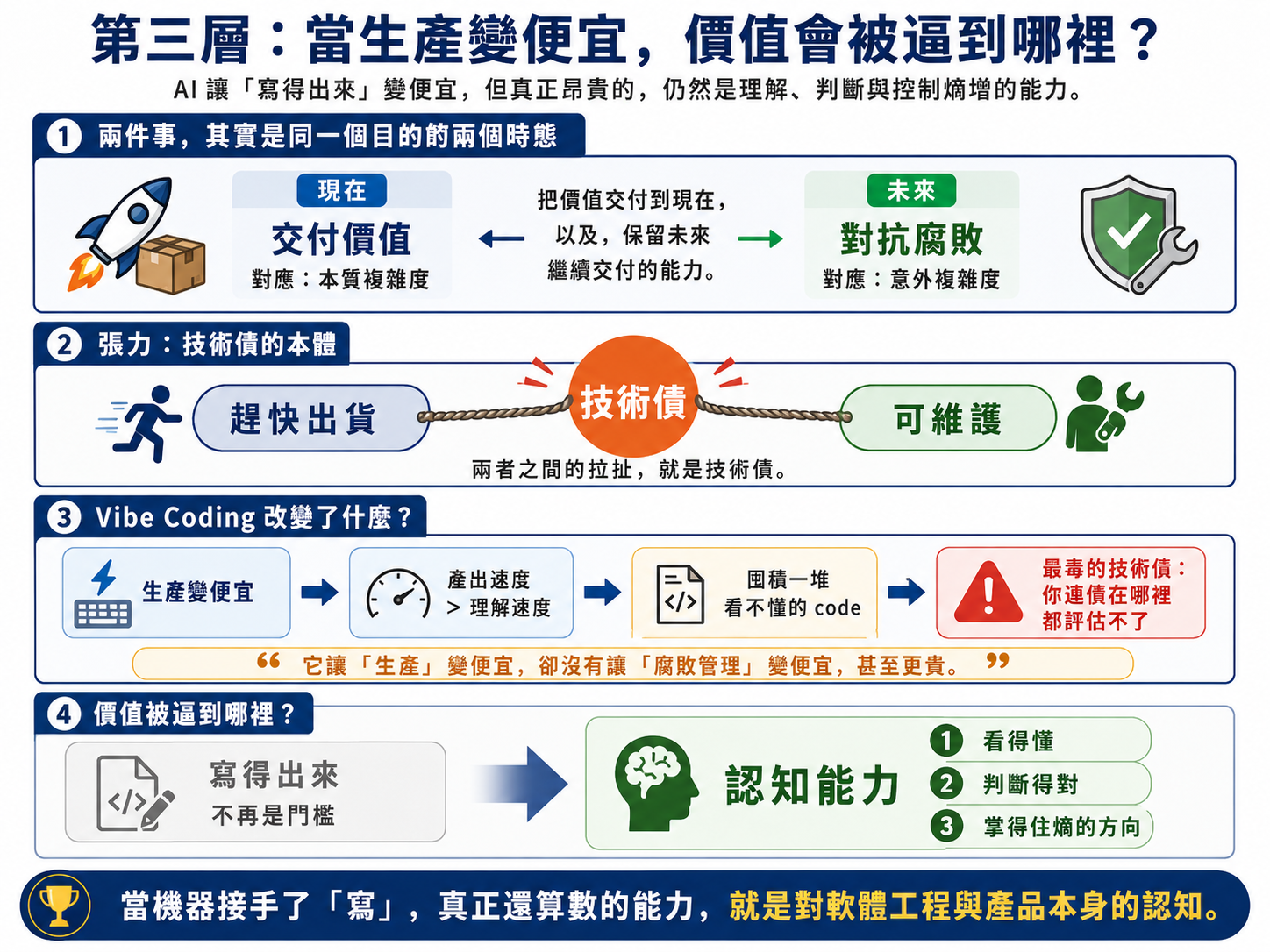
回到那兩件事:
- 第一件:
交付價值,對應的是本質複雜度 - 第二件:
對抗腐敗,對應的是意外複雜度
我甚至會更想把它們講成「同一個目的的兩個時態」:
把價值交付到現在,以及,保留未來繼續交付的能力。
這樣講能直接看見兩者的張力:
「趕快出貨」與「可維護」之間的拉扯,正是
技術債的本體。
理解了這層,vibe coding 真正改變了什麼就清楚了:
它讓「生產」這件事變便宜,卻一點都沒讓「腐敗管理」變便宜,甚至更貴。
因為你現在會用超過自己理解速度的速度,囤積一堆看不懂的 code,而「看不懂」本身,就是最毒的一種技術債:
你連債在哪裡都評估不了。
所以 AI 不是讓工程認知變得不重要,恰恰相反,它把價值整個逼到了 認知 這一端。
寫得出來,不再是門檻;看得懂、判斷得對、掌得住熵的方向、懂的品味,才是。
不管是人寫 code,還是 vibe coding,最終都回到同一件事:對軟體工程與產品本身的認知能力。差別只是,當機器接手了「寫」這個動作,這份認知就不再是其中一項能力,而是唯一還算數的那一項。
底下由 ChatGPT 產生本段摘要:
結語:先看懂本質,才騎得動這頭巨獸
不管你寫了十年 code,還是剛在學校翻開第一本 CS 課本,這段話對你是同一句。
AI 不改變規則,它只放大規則。
回到 複利:
AI 是乘數,不是加數。
判斷清楚,它放大你的好;腦袋一團糊,它連你的亂一起放大,而且更快。以前是五天壞光、五年壞光,現在是五小時壞光。加速的從來不只是生產,還有腐敗。
對已經在線上的工程師:
別把 AI 當成可以外包掉「理解」的地方。
你越懂熵、越懂內在與外在的落差、越懂技術債怎麼長出來,指令就越準,眼睛就越利。
AI 放大你的本質,它不會替你長出本質;如果你本身什麼都沒有,複利的結果會是什麼都沒有。
對正在學的人,別以為 AI 會寫了,底層就能跳過。
你跳過的每一塊基本功,最後都會變成你看不懂、也評估不了的技術債。而它,會用複利討回來。
「寫得出來」已經不值錢了。值錢的是「看得懂、判斷得對、懂品味」,而這一端,沒有任何捷徑能抄。
我寫這段文字的時候,不是只是說說,而是已經身體力行一段時間。這個 Blog 上很多文章,其實都是同一件事的不同切面:往下挖,挖到本質為止。我自幹了 作業系統,包含實作 Timer、Task and Scheduler、Context Switch、Networking 一個一個拆開重寫,就是想搞懂:
當你以為程式「只是在跑」的時候,底下那層
外在到底發生了什麼。
我 用 Mini PC 實測 Throughput / RPS / C10K,是因為我不想再聽信任何沒被自己量過的效能數字。我純手工寫了一個 Java 2D RPG Game、把 有限狀態機 (FSM)、API First 開發策略、SaaS 關鍵設計 - Multi-Tenancy 拆到骨子裡,都是同一個固執:
不靠抽象層替我理解,我要自己看到底層怎麼動。
而有趣的是,這裡面有好幾篇,是我最近「騎著巨獸」學會的。我把 AI 當老師、當顯微鏡、當陪練,結果比過去任何時候都更深入底層。這正是我整篇想說的:
AI 不是讓你離本質更遠的藉口,它可以是你逼近本質的最快路徑。差別只在於,你是用它跳過理解,還是用它加速理解。
AI 是一頭巨獸,力量大得嚇人。但巨獸不挑乘客,牠只忠實地往你指的方向狂奔。看得懂地形的人,騎著牠跑得又遠又穩;看不懂的人,只是被牠載著,更快地衝下懸崖。
而最危險的,是第三種人:
以為自己在駕馭,其實只是抓著韁繩往下墜。
別當第三種人 …
先看得懂,才騎得動。
Comments
About
著作
演講
- 演講錄影 @ Youtube
- 探索職涯、複利人生 - AWS Career Exploration Day 2023
- 個人著作 SRE 書友見面會
- 軟體測試實務 - 新書發表會
- 探索職涯、成就未來 - AWS Career Exploration Day 2022
- 從理想、到現實的距離,開啟品味軟體測試之路
- 91APP 在 AWS 上的 SRE 實踐之路
- 在矩陣型組織裡,如何有效管理 AWS 的成本結構與系統架構
- 災難演練 @ AWS 實戰分享
- 導讀持續交付 2.0 - 談當代軟體交付之虛實融合
- 聊聊軟體交付的濫觴 談產出物管理
- 從緊急事件 談 SRE 應變能力的培養
- 邁向 API 經濟 - API Gateway 導入之旅
- Monitoring Tools 大亂鬥 - AWS CloudWatch
- Ops as Code using Serverless
- 淺談系統監控與 CloudWatch 的應用
AWS Certifications


