EKS 學習筆記 - 網路規劃與管理篇
整理 EKS 的 Networking 相關的問題,主要有規劃、管理 … 等觀測,如下:
- VPC Consideration: 規劃的考量
- VPC-CNI Utilization: VPC IP 的使用狀況
- Cluster AutoScaler: Worker Node 的 AutoScale
規劃
VPC Consideration
使用 EKS 之前,必須先考慮 VPC 的規劃,相關 VPC 規劃概念可以參考底下兩篇整理:
本文分成以下兩個情境:個人測試、有串接 VPN 的企業
如果是個人測試、或者公司沒有串接 VPN,建議至少有以下配置:
- Public Subnets: 放 Master Nodes 或 Worker Nodes
- Private Subnets: 放 Worker Nodes,如果都使用 Public Subnet 就不需要了。
如果是在有串接 VPN 的企業內部,建議都放在 Private Subnets,Ingress 也是放在 Private Subnet ,然後透過 ALB / CLB 開放給外部。
EKS 會直接使用 VPC CNI,換言之每個 POD 都會配給 VPC 的 IP,如果會大量的開 POD,那麼就要注意 Subnet IP 的的使用狀況。依照這篇 Elastic Network Interfaces 的整理,不同 EC2 Instance Type 可以使用的 ENI 有其數量限制,而可以使用的 IPv4 Address 又有限制。舉例來說:
- t2.large: 最多 3 ENIs, 每張 12 個 IP,所以最多只能開 36 個 PODs
- c5.large: 最多 3 ENIs, 每張 10 個 IP,所以最多只能開 30 個 PODs
- c5.xlarge: 最多 4 ENIs, 每張 15 個 IP,所以最多只能開 60 個 PODs
- m5.large: 最多 3 ENIs, 每張 10 個 IP,所以最多只能開 30 個 PODs
- m5.xlarge: 最多 4 ENIs, 每張 15 個 IP,所以最多只能開 60 個 PODs
- …
所以要考慮的幾個點:
- 可用的 IP 數量 與 Subnets CIDR 規劃
- Worker Node 使用 IP 數會非常驚人,所以一定要留意 IP 的數量。
- 如果不夠用,可以單獨規劃 VPC 或者使用 VPC Expending 功能擴展 CIDR。
- Master Node 是否允許外部存取?或者說透過外部存取?
- 如果是作 Lab 可以都允許 Public Access
- Worker Node 是否允許外部存取?
- 通常依 Ingress 設計決定。
- 是否需要隔離 namespace 管控?或者做 Firewall (Security Group)?
- 如果是 Multiteleant 架構就會需要考慮
- 隔離性一直以來是 VPC 規劃的重點,同樣的概念,在 K8s 也是。
維運
VPC-CNI Utilization:如何監控 ENI 與 IP Address 使用狀況
參考 CNI Metrics Helper。主要確認 IAM 權限、然後 apply 即可。
- ENI 使用狀況
- Cluster 最多有多少個 ENI 可以使用
- 已經配置多少 ENI
- IPs 使用狀況
- 總共有多少可用 IPs
- ENI 已經配置多少個 pod
- 目前已經有多少個 IPs 配給 pods 了
- 有多少 ipamD errors
底下實驗:
- Worker Nodes 是兩台 c5.xlarge,依據文件的描述 Elastic Network Interfaces 的計算出 c5.xlarge:
- 最多 4 ENIs
- 每張 15 個 IP,最多 60 個 IP,只能開 60 個 PODs
- 兩台最多
- Max ENIs: 4 * 2 = 8
- Max IPs: 60 * 2 = 120
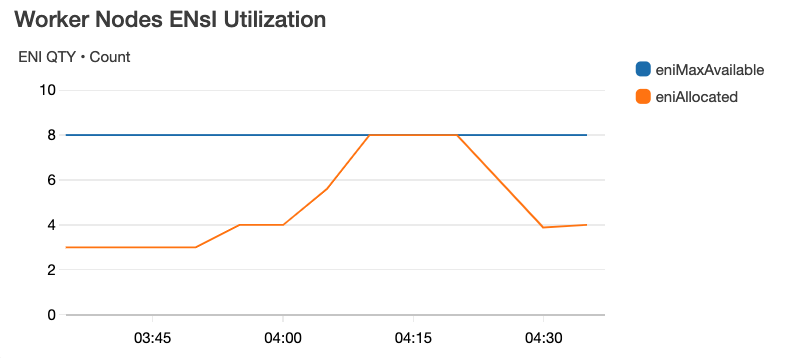
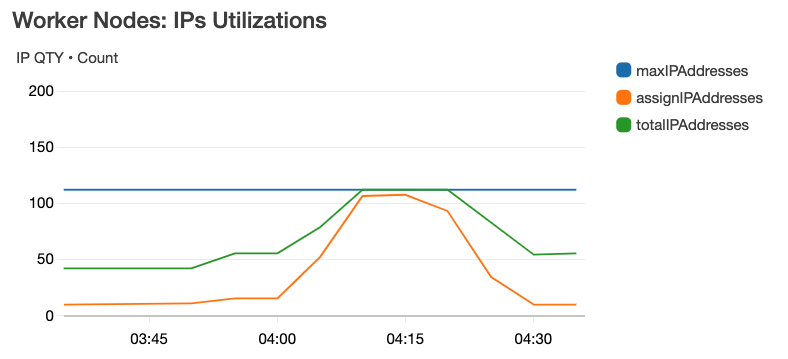
驗證上述屬實,c5.xlarge 的 ENI & IPs 數字文件所描述,如下圖:


實際算過,每台 c5.xlarge 如文件所描述是:4 ENIs, 60 IPs
我嘗試跑一個簡單的 AP, 讓 pod 長到 100 個
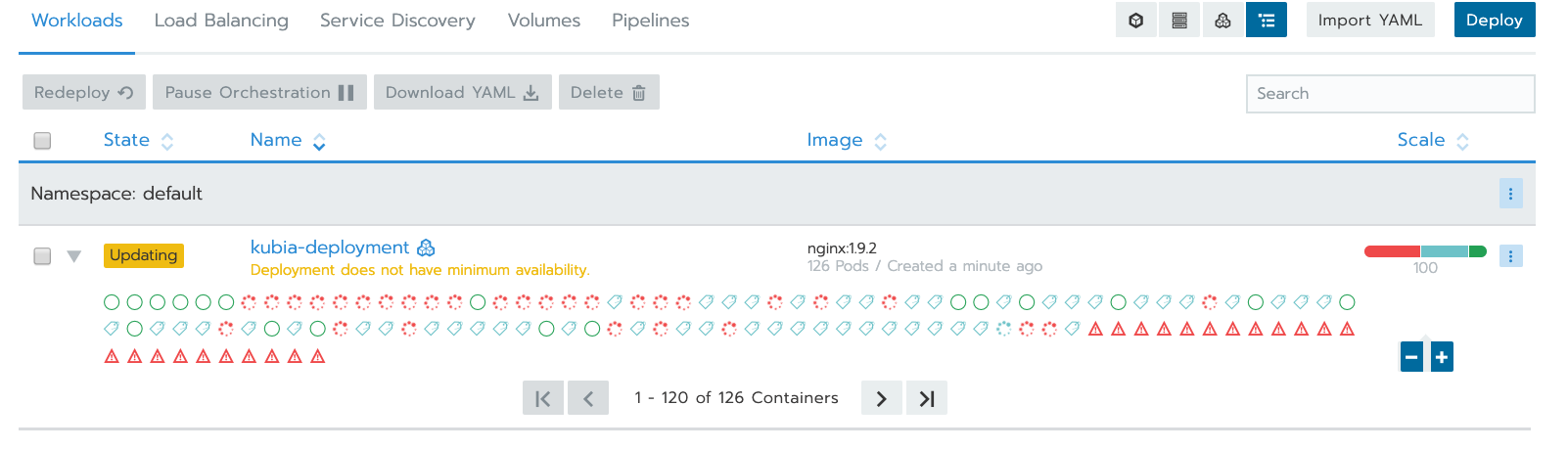
扣除 kube-* 在使用的、第一張 eth0 使用的,實際上每台能使用的有 112 個 IPs,得到以下的圖:
Cluster AutoScaler
承上,如果 pod 的資源不夠了,例如 IP 不夠用,如何觸發 Worker Nodes 的 ASG?上一個問題中,有兩台 Worker Nodes,當長到 100 pod 時,其中有一些 pods 因為沒有 IP 可以使用,如下圖,這時候如觸發 ASG 自動 Scale Out?
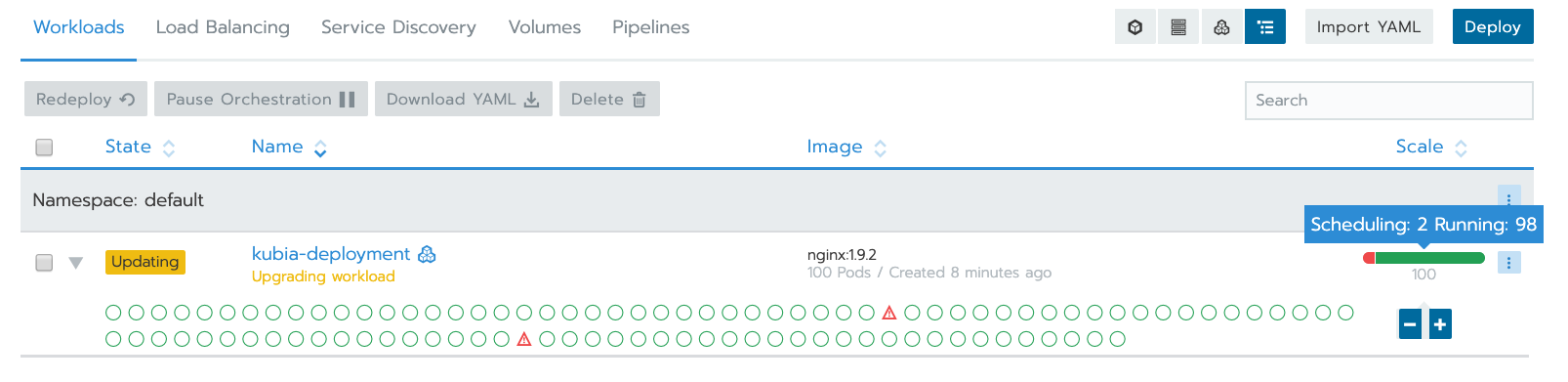
K8s 的解法:Cluster Autoscaler。步驟大概如下:
- 設定 Worker Node 的權限,主要是讓他可以對 ASG 操作,另外記得打開 ASG CloudWatch Metrics。
1 | { |
- 依序執行以下:
1 | ## 部署 cluster-autoscaler |
- 綁定 autoscaler 與 ASG 的關聯,執行
kubectl -n kube-system edit deployment.apps/cluster-autoscaler,找到以下做修改,其中<YOUR CLUSTER NAME>換成 EKS Cluster Name
1 | spec: |
- 查詢 log:
kubectl -n kube-system logs -f deployment.apps/cluster-autoscaler
到此完成設定。
Scale Out
接下來試著把 pod 的數量長到很極端,這裡的範例是:
- worker node: c5.xlarge x 1
- pod: 10
把 pod 的數量調整成 100,觀察 deployment.apps/cluster-autoscaler 的狀況,會發現類似底下訊息:
1 | I1019 05:18:40.633616 1 static_autoscaler.go:138] Starting main loop |
這時候觀察 ASG 的 Metrics,如下分別是 Worker Nodes 的 Instance Count、ENIs QTY、IP QTY
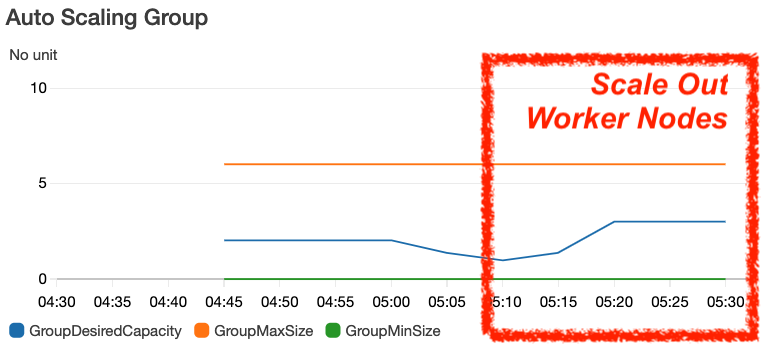
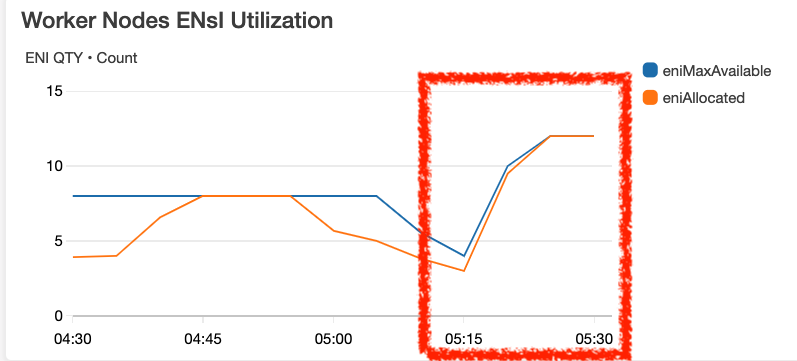
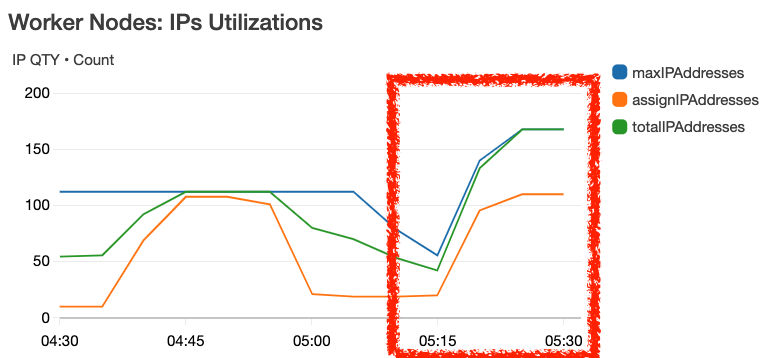
Scale In
長出去的機器,當然要自動收回來,把 pod 的數量調降回 10 個,不過無法正常運作,遇到以下問題:
Failed to regenerate ASG cache: cannot autodiscover ASGs: RequestError: send request failed
cluster-autoscaler 的 log:
1 | I1019 05:58:09.678245 1 static_autoscaler.go:138] Starting main loop |
到 pod 裡檢查,發現無法反查 DNS
1 | ~$ k exec -it cluster-autoscaler-db8ccb5d5-fc65n -n kube-system sh |
問題待解。
延伸閱讀
K8s 相關
- Experience minikube
- Experience EKS Anywhere
- K8s 學習筆記 - kubeadm 手動安裝
- K8s 學習筆記 - 工具篇
- K8s 學習筆記 - 維護與常見問題
- EKS 學習筆記 - 基礎安裝篇
- EKS 學習筆記 - 網路規劃與管理篇
VPC & EC2
- Study Notes - Virtual Private Cloud (VPC)
- Building a VPN Between GCP and AWS
- Study Notes - EC2 Auto Scaling 基礎介紹
- Plan and Design Multiple VPCs in Different Regions
參考資料
- AWS re:Invent 2018:
- Elastic Network Interfaces
- kubectl 命令技巧大全
Comments
About
著作
演講
- 演講錄影 @ Youtube
- 探索職涯、複利人生 - AWS Career Exploration Day 2023
- 個人著作 SRE 書友見面會
- 軟體測試實務 - 新書發表會
- 探索職涯、成就未來 - AWS Career Exploration Day 2022
- 從理想、到現實的距離,開啟品味軟體測試之路
- 91APP 在 AWS 上的 SRE 實踐之路
- 在矩陣型組織裡,如何有效管理 AWS 的成本結構與系統架構
- 災難演練 @ AWS 實戰分享
- 導讀持續交付 2.0 - 談當代軟體交付之虛實融合
- 聊聊軟體交付的濫觴 談產出物管理
- 從緊急事件 談 SRE 應變能力的培養
- 邁向 API 經濟 - API Gateway 導入之旅
- Monitoring Tools 大亂鬥 - AWS CloudWatch
- Ops as Code using Serverless
- 淺談系統監控與 CloudWatch 的應用
AWS Certifications


