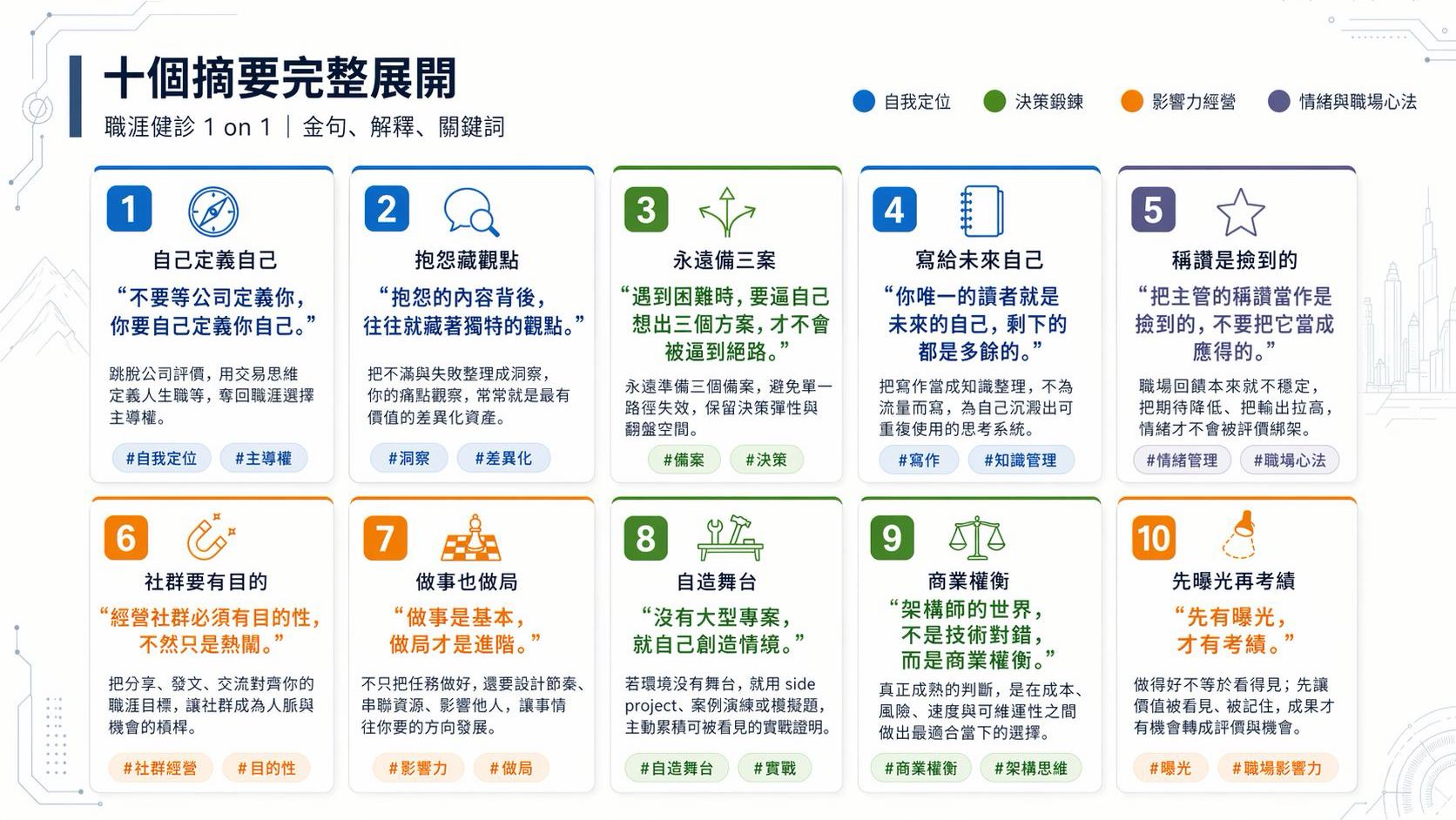
這篇是整個 Blog 的全站索引,如果您是第一次來這裡,可以先看看這篇索引,大概知道 Blog 的全貌:
- [理念] 思考本質、實踐、抽象、想像力、教育
- [目錄] 經營管理: 整理管理經驗談、管理哲學、經營、領導、用人之道、學習方法、專案管理
- [目錄] 軟體工程實踐: 包含軟體架構、開發、測試、維運等 … 實踐的心得。
- [目錄] 分散式系統,包含分散式系統理論、Cloud Native - Kubernetes、AWS。
- [參考] 參考書、資訊技術與工程專有名詞、計算機科學專有名詞、經營管理專有名詞
- [系列文] 公車隨筆、寫作與閱讀系列文、溝通、會議效率
- [關於] 學習法則、經營之道、一些領悟、分類哲學
- [站內記事]: 文章更新紀錄, 點閱率統計
不管是程式、文章、資料、還是房間,我都會定期重新整理 / 重構,核心概念來自於 分類的哲學