如何量測系統的容量?(壓測)
淺談效能測試 整理了關於 Capacity、Reliabilty、Stability 的概念與定義。本文針對如何量測 系統容量 (Capacity),整理怎麼做的方法論,可以當作 Capacity Plan Guideline。
系統容量是透過
量測 (Measure)出來的,結果是數據統計的報表,而測試的結果通常是 pass or fail,故本文的描述不用測試這個動詞。
這篇文章整理的是如何執行的概念,但不包含以下:
- 介紹工具
- 環境如何建置
- 如何設計架構
- 如何優化架構
更新:
- 20230523: 本文全文收錄在 共同著作《軟體測試實務》 第二冊 第一章之中,歡迎大家彭場指導。
- 20260519: 《Mini PC 效能實驗:實測 Throughput / RPS / C10K》 是本文方法論實際執行筆記,
結論:三種量測的策略
先講結論,做容量的量測,常見的三種目的,也就是選擇的思路:
以輸入為基準值 (業務導向):- 業務目標是 200TPS (每秒兩百筆交易),最後找到的結果是整體系統需要多少
資源 (成本) - 以此結果,調教系統架構,找到瓶頸,降低成本。
- 業務目標是 200TPS (每秒兩百筆交易),最後找到的結果是整體系統需要多少
以系統資源做基準值 (理想值 / 基準值):- 用已知的資源做基準,例如一台 c5.xlarge,然後找到輸入的基礎值 Baseline ,像是 TPS / RPS / QPS
- 依照 Baseline 的結果,推算線性結果,評估當需業務需求。
- 本文描述的方法論屬於這個策略。
- 基於本文量測的結果,超過理想值容量,是所謂的
壓測,壓測背後要處理的是可靠度的問題。
應用程式設計基準值 (效能值):- 也就是 SLO,例如直接以 100QPS、以 c5.xlarge 為組合基準,以此開發應用程式
- 目標就是把應用程式調教到這個目標,需要對效能調校有深度著墨,像是記憶體、Multi-Thread、I/O Model … 等有深度理解。
- 效能測試 (Performance) 指的是這個這樣的策略之下的測試
定義
開始說明之前,先定義 容量 (Capacity) 是什麼:
待測目標在一定的基本條件之下,能夠穩定的提供的產出、輸出,這個在固定條件、單位時間內的輸出的值,稱為系統容量 (Capacity)
這邊標記幾個名詞:
待測目標 (target):主要的功能項目、商業邏輯的運算,可說是 algorithm基本條件 (resource):待測目標的載體,軟體要執行的硬體資源,像是多少 CPU、Memory、I/O,甚至是怎樣的系統架構、網路環境產出 (output):待測目標的產出結果,依照應用程式的不同,可以有不同的結果。系統透過取樣 (Sample) CPU、Memory、I/O 等 Metrics 資訊,AP 則透過 Trace & Logging 作為 Raw Data,進而分析結果。通常會用百分位統計 (P90, P80, …) 來表示數據的分佈。輸入 (input):輸入請求與參數的量體,例如每秒多少的請求 (RPS)、交易數量 (TPS)、查詢數量 (QPS) … etc.穩定的:最終追求的可控 (Controllable) 關係,穩定的數學概念 -線性關係,與時間 (t) 有關係
用以下公式表達他們的關係:
target (resource, input) = output
當產出的結果,與基本條件、處於穩定的 線性關係 時,這個基本條件稱為 Baseline (基數),而這個產出結果稱為 Beanchmark。
在很多領域都有一些指標,用來定義效能,例如:某某某廠牌的 SSD Read/Write Throughput 可以達到 1200MiB/s, 1000MiB/s。
- 1200MiB/s 就是讀取效能量測的 Beanchmark
- SSD 的基數則是 透過怎樣的介面,例如 PCIe 介面
推演方法論
容量量測的執行面,本身是有很多方方面面要考慮的,用比較科學的精神,用類 Java Code (其實我也不知道是啥扣 XD) 整理 + 推演:
如何有效的執行系統容量量測?
這整個量測容量的流程,基本上就是一個演算法,也可以說是方法論。
一、準備工作:定義輸入、輸出、待測目標、量測工具
首先就是宣告的變數,也就是一開始定義的名詞。
1 | // -- 必要的前提條件、資訊 |
這部分分成三大部分:
- 第一部分準備資源集合 (resSet)、待測目標 (reqs)
- 資源集合: 指的是實際的載體,像是例子中描述的是一台 c5.large 做 Web Server、一台 c5.large 當 DB Server。
- 待測目標: 輸入的條件是同時送的請求從每秒 10 到 100 個,然後打到 10M 的總量,跑 STORY_SET1 + STORY_SET1 的組合。
- 第二部分是輸出的結果,主要包含:
- 每次運算的結果資料 (resultSet):通常就是用來分析的 Log & Tracing 的 Raw Data,盡可能蒐集,不然事後少了這些資料可以分析,就要再重跑,會非常好成本。
- 實際想要探索的結果 (capacity),也就是預期的結論值,這個值在量測過程,必須不斷的修正。
- 需要有適當的量測工具,包含 Logging & Tracing、Metric 工具等。
- 第三部分是我們要實際量測的應用程式:
- 本文案例就是 Web Application
- 有時候也會有類似 SDK ,但建議搭配適當無干擾的 Web Application 一起量測。
- 理想就是要有 Artifacts、Configuration,讓執行團隊自行部署、與調整參數
用圖來表達概念,如下:
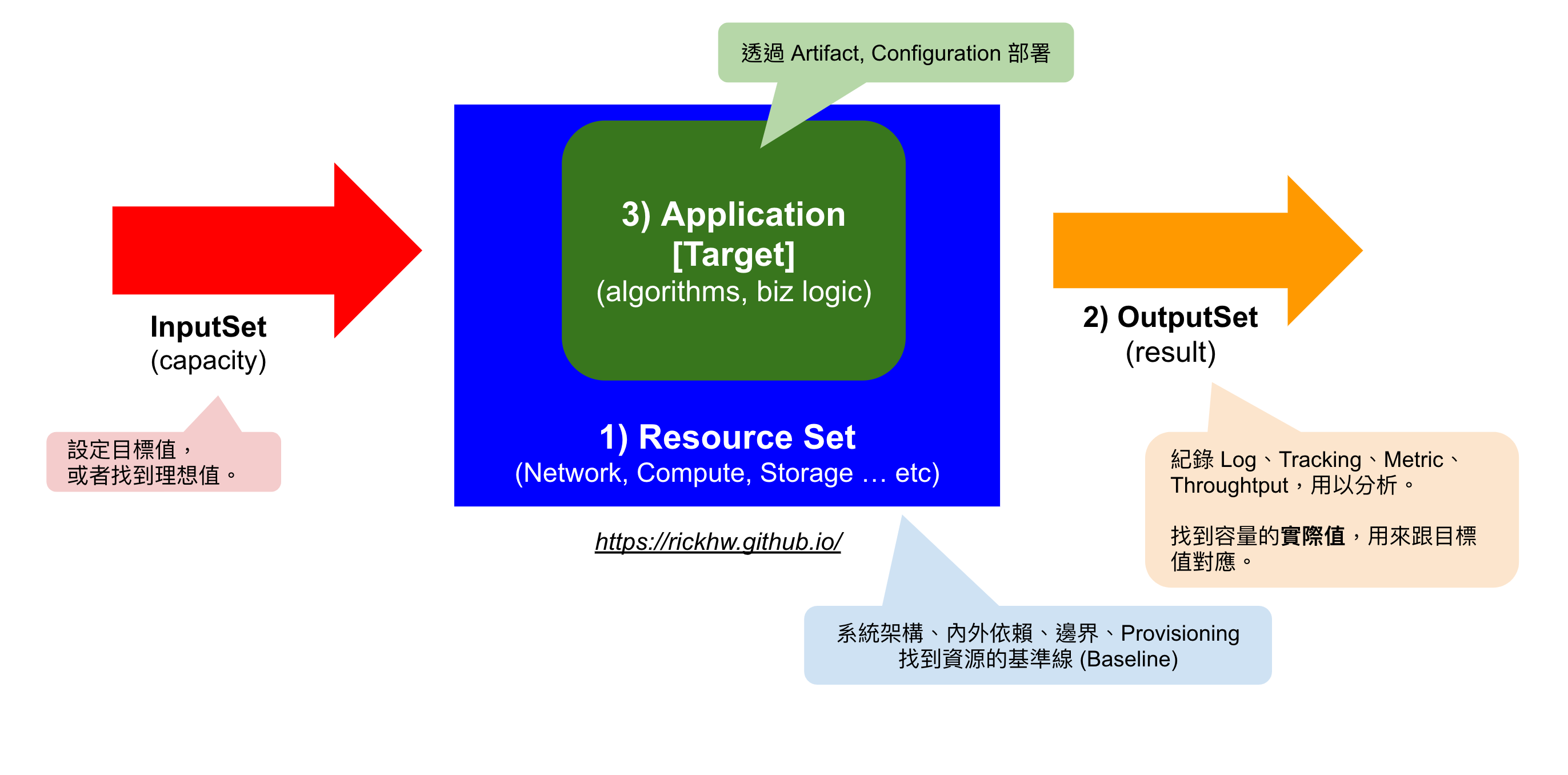
資源集合部分,理想的狀態必續包含以下:
- 系統架構圖做主要的結構:
- 如何表達系統架構,參閱 演講:從緊急事件 談 SRE 應變能力的培養,Slide 的 P64 ~ P97
- 定義系統的邊界,同時把
強依賴、弱依賴疏理清楚,這都會影響量測的結果。 - 配置適當的網路架構:像是有些 AP 會大量做 DNS 查詢,所以 K8s 以前的 KubeDNS 就無法乘載,後來改成 CoreDNS 效能就比較好了。
- 如果系統非常複雜,那麼要試著拆分架構,把邊界定義清楚,然後個別去量測,也就是
divide and conquer (分而治之),千萬不要整坨混在一起做。
- 待測的應用程式 Artifacts:參見 Artifacts Management、聊聊軟體交付的濫觴 談產出物管理
- 配置檔 (Config):分成靜態 (Static)、動態配置 (Dynamic),配置檔通常會明確有依賴性的資訊,像是對外的 API 串接、一些 Callback …
然後完成適當的部署與建制,移除不相關、或不重要的串接,可能帶來的干擾,像是不必要的 Auth 機制、不必要的 DNS 查詢 … 等。但也不能一味地把這些關聯移走,如果真實的狀況是有強依賴的,就必須考量額外的模擬方法,例如模擬 AWS SES 或者 Apple APNS / Google GCM 的 API。所以如何界定好邊界,其實是系統架構一開始就要釐清的,否則容量量測會不容易定義邊界以及依賴。
待測目標除了輸入的條件,最常被忽略的就是:
Client 端的網路吞吐量 (Network Throughput)、以及 Server Side 運算資源的網路頻寬
換言之,待測體要有資源準備,模擬請求端的系統,也是同樣要準備資源的,甚至是一個可觀的架構,才不會造成:
大砲打小鳥,或者小鳥打大砲
這樣就是一個不對等的資源比較,整個量測意義就不大了。
實際上執行容量量測,一開始最難的就是環境的準備,這些都準備好了,確立了,接下來的量測方法才有意義,才不會浪費成本。
二、找到可能的容量 (Capacity) 與資源的基準線 (Baseline)
第一階段:找到 可能的 capacity 大小,用以下的程式表達:
1 | // 輸入 resSet, reqs 當作基數, 得到 resultSet |
這段邏輯的前提就是:
資源不變,找到最適合的的輸入條件。
以這個例子來說,待測體的資源是 Web / DB 都是 c5.large,這個條件不能變,模擬 Client 的 ConcurrentSet 每次測得值都不一樣,從 10 開始,然後依照指定增加、以此類推。如果結果在 70 的時候,系統當掉了 (無法關機、或者 CPU 100% 沒有回應了),那麼再退回去 60 跑,結果就是 60 了。
當然,實際上執行不會只有看 CPU,通常也會從 Client 看 Latency / Error Rate、待測體的 Memory、Disk I/O、Networking Throughtput、甚至是 AP 的 Log 分析等。
這個例子找到的 capacity 是 60,資源的 baseline 是 c5.large。如果這個值最後確認是線性關係,那麼這個值稱為 Benchmark。
這個過程要注意的事項,這些事情也是事前要準備好的:
- 蒐集資源的使用率,每台機器的 CPU, Memory, Disk I/O, Networking Throughtput
- 如果 AP 是 JVM Base,執行前要確認 HeapSize 的設定,執行過程同時蒐集 HeapSize 的使用狀況
- 蒐集 AP 本身的 Log 資訊
- 在每個節點的進入與出去點記錄時間,紀錄 Process Latency。
- 量測每個進入點的資料流、吞吐量 (Throughtput)
上述的量測方法是固定資源,然後找到輸入條件,但如果反過來呢?也就是已經有確立的輸入條件(期望目標),然後量測所需要的資源規格,這也是一種量測方法,例如希望同時線上人數為 1000、同時交易目標 TPS 100。
三、驗證 Capacity 是否為線性關係?
上述階段的結果 (concurrent=60) 其實無法確認是否真的是系統的 Capacity,所以接下來要調整量測方式:
- 條件:
- 用 concurrent 60 的結果當作輸入的固定基礎
- 等比調整 concurrent 與 IResource
- 預期結果
- concurrent 與 IResource 的關係成正比。
1 | // 假設輸入與資源是線性關係 |
這結果要確認幾個:
- 結果沒有炸掉,表示可能是線性的
- 承上,使用的資源狀況是否是等比上升
結果概念如下圖:
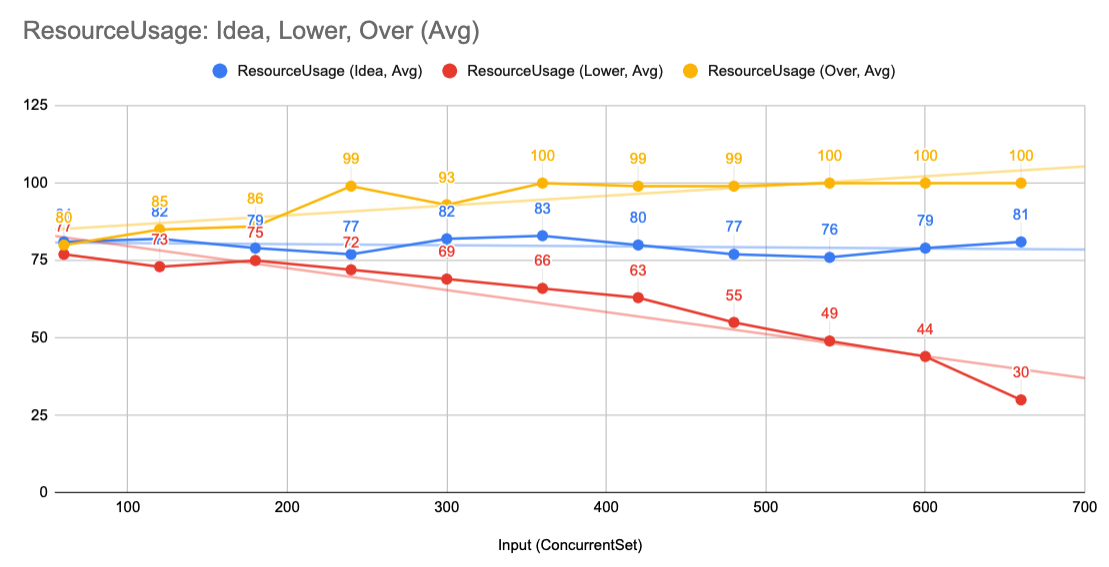
X 軸是輸入,也就是 ConcurrentSet 的倍數關係,Y 軸是資源使用率, 100% 是滿的。
- 藍色是理想
- 黃色是炸掉了
- 紅色是基準值太低
如果結果是藍色的,那麼:
∴ 可以如此宣告此 系統的容量是
capacity,基於的 Baseline 是c5.large
- 系統的容量值為變數
capacity的結果,這個數值可以稱為系統的Benchmark- 此 Resource 的數值:
c5.large- 稱為Baseline
Q and A
Q1: Capactiy 跟 Load Test、Stress Test 有什麼不一樣?
Capacity 跟 Load Test 實際上是一樣的東西,只是用詞差異而已。
Stress Test 是 測試 的一種,指的是輸入極端條件,確認系統的變化與反應。例如 Benchmark 是:
c5.large 的機器可以乘載容量是 RPS 100
然後打 RPS 500 ,持續 10 分鐘,看看系統的狀況。
這樣的測試條件與方法,稱為 Stress Test,他的前提是已經知道 Capacity 的 Benchmark。
- Capacity 是量測,結果是 As c5.large,RPS 1000、TPS 50,呈現的是統計結果。
- Stress Test 是測試,結果是 CAN BE or CANNOT BE,是零或一的問題。
Stress Test 的測試結果兩種:
- 系統崩潰,回不來了
- 系統沒有崩潰,通常需要具備的就是可靠性 (Reliability),他會具備以下架構的特性:
- 有彈性 (Resilience),系統自動修復 (Recoverability)
- 具備容錯機制 (Fault Tolerance)
- 有冗余機制,達到有高可用 (Highly Available)、沒有單點
- 有降級 (Downgrade) 或者熔斷機制 (Broker),自動保護系統
- 系統有限流 (Rate Limit) 保護,不會被沖垮,更多參閱:API Gateway - Rate Limit and Throttling
- 架構有解偶 (Loosely Coupled),所以不會太過於依賴其他服務而影響到服務
Reliability 是 架構議題,架構是目標導向,必須滿足系統的特殊需求。而 *測試屬於驗證導向- 、 量測屬於統計導向。針對可靠性有機會另外撰文整理心得。
Updated 2020/04/22: 相關請參考: 可靠性工程 Reliability Engineering
Q2: 承上,那 壓測 跟你說的容量量測 有啥不一樣?
呃,中文有一些語意其實是怪怪的。壓力測試 對應到英文是 Stress Test,這概念上一個問題已經描述。
實際上大部分的人問的都是系統的 容量,而不是真正的壓力。例如,業務單位常會問:
- 我們的系統可以乘載多少人在線上?
- 我們的系統可以同時處理多少交易?
- 如果有 100 萬人,系統能否乘載?要加多少機器?
這些問題,重新整理之後,你會發現大部分問的實際上都不是壓測 (Not TRUE or FALSE),而是容量 (HOW Many)。
Q3: 如果有相依性,請問怎麼量測?
相依性分成 內部依賴、外部依賴,依照依賴的強弱又分 強依賴 與 弱依賴,可以用以下圖表分析,把這些依賴分類填入:
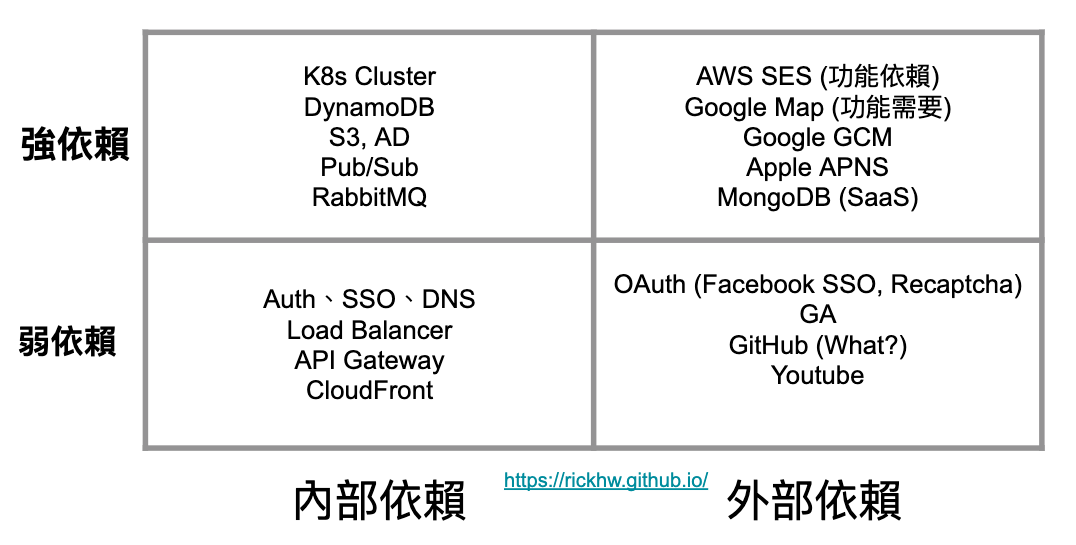
註:這張圖的依賴分法,是依據網路拓墣結構的分法,有些服務實際上是 WAN,但在 AWS 上卻可以透過 VPC Endponits 讓他有 LAN 的效果。
外部依賴的類型:
- Managed Service: 像是 DynamoDB、S3、GCP Pub/Sub 這些東西,很常會是 Vender Locking 的東西。
- 通常有 Rate Limit / Quota,需要額外申請 RPS / Quota
- 會收到 HTTP 429 的 Return Code (RFC 6585)
- 3rd party API: 例如 Google Map API、某家 SMS Provider、Apple APNS / Google GCM …
- 通常沒有 Rate Limit,用多少收多少錢。
- 有機會把對方打掛。
量測過程中,可以透過 Fake / Dummy API 模擬這些外部依賴。這些 API 是可以自己模擬的。
通常系統會希望的結果是:
- 自己對外的
吞吐量 (Throughtput)是穩定的,單位時間的請求是可量測的值,例如 RPS 1000 這樣的數字。- 實作方式就是利用
大使模式 (ambassador)實作外部的 Rate Limit,限制自己對外的吞吐量,例如打 Google API 固定在 RPS 100。有點像車的定速器。 - 大使模式概念 請參閱 分散式系統設計 - 正體中文版 第三章的介紹
- 實作方式就是利用
- 依賴的對象,接受請求的吞吐量也是穩定的。
- 重要的服務,限制進來的流量在一定的承受範圍,例如登入 API 限制在 RPS 200,或者系統以此為 Beanchmark 可以線性 Scale Out (擴容)。
- 通常是利用 API Gateway 管控進來的流量請求。
- 想辦法把強依賴的移到弱依賴
Q4: 如果量測的是外部依賴,那要怎麼做?
先不管怎麼做,先講注意事項。
不管依賴的是什麼對象,把大量流量送到人家的系統,在網路上會被當作惡意攻擊,輕則影響業務,嚴重則有法律刑責問題
因為這些行為,在維運人員的眼中,都是挑釁與攻擊。只要看到這種奇怪的流量,監控系統一定會跳起來(除非沒在監控),然後都會提高警覺。
如果你的依賴是一般小公司的服務,可能會把他的系統打掛;如果你的依賴是 Google API … 呃,把它打掛嗎?他掛掉之前,你公司的網路頻寬塞爆,如果你是從 Cloud 上 (AWS, Azure, GCP) 製造流量,那可能會被這些 Providers 警告,然後錢會被燒光。
到現在我還沒講怎麼做。
這件事情應該是透過溝通取得,通常問幾個問題:
- 你們的服務有沒有限流 (Rate Limit)? 有的話是多少?
- 如果沒有限流,那可以接受的流量是多少?
請對方的工程團隊回答,答不出來我會拿過去與對方的請求歷史資料分析,當作參考,自己心裡才有底。外部依賴比較不是工程問題,而是溝通問題。
除非可以溝通到對方願意讓你打,但要很警慎,通常這種任務,具備一定的工程能力,才有辦法處理,否則都是開資源(砸錢)解決,也就是沒有真的量測過。
Q5: 我們的系統很複雜,要怎麼做前述的量測?
恩,如果你的團隊、你的老闆是講求科學與工程的團隊,那麼 divide and conquer 是最好、最短的路徑,中文叫做 分而治之,要做的就是 一、準備工作 的描述。拆分之後,了解他們的關係(如下圖),找出每個系統的容量,以及最小的個體,這個個體就是 木桶理論 裡的 短版 了,他滿了,整個系統就滿了。
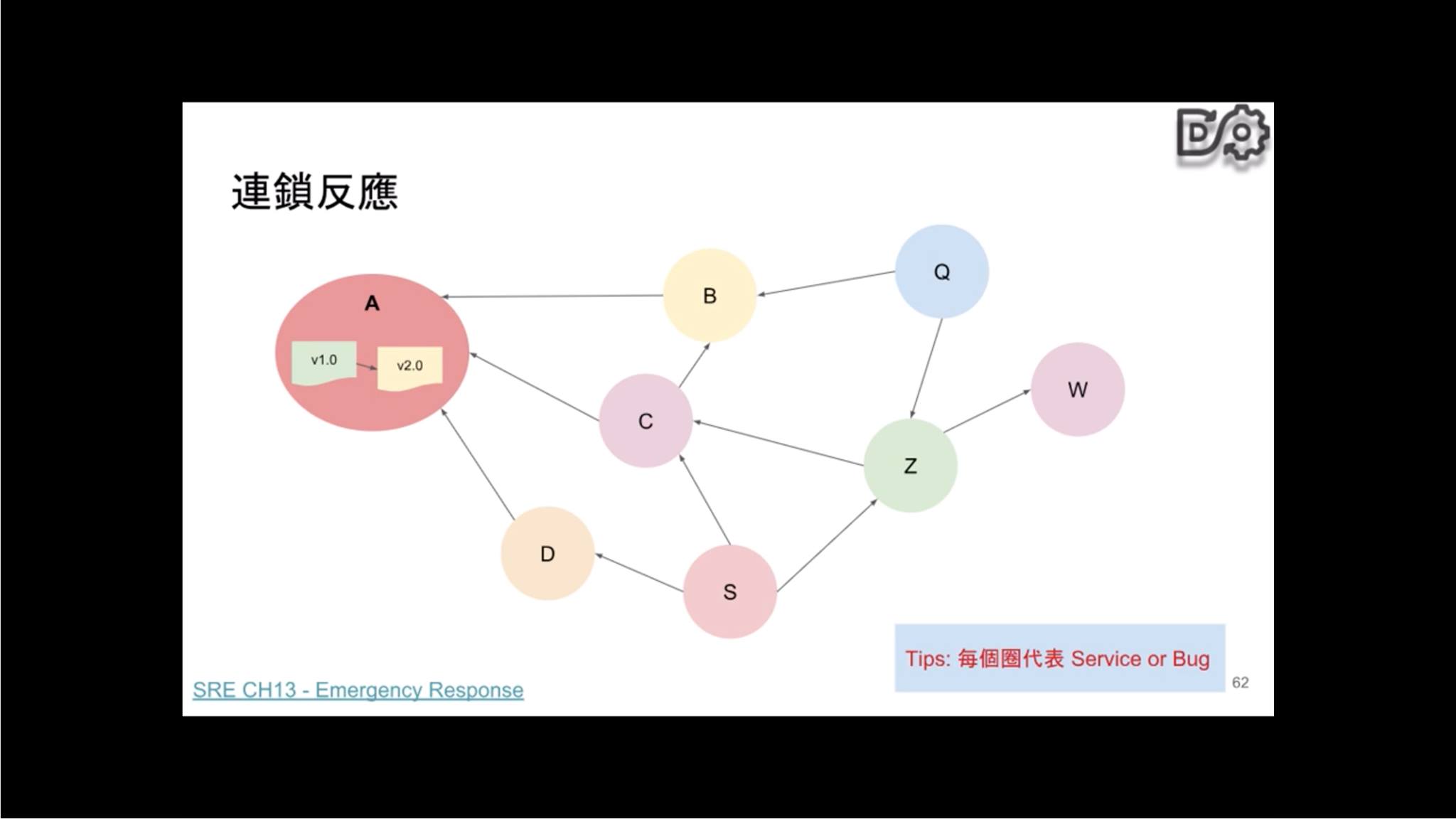
然後一定要花時間、踏實的把這些架構裡的角色弄清楚、依賴搞清楚,相信我,明年的現在,下一個人會問一模一樣的問題。如果有照著做,明年的現在,你會很有自信地說:我的系統可以乘載多少的容量,而且你會變得無比的強大。
Q6: 承上,你在 聊聊分散式系統 有一張微服務架構圖,這張圖的架構要怎麼量測?
這問題只有我才會問,因為圖是我畫的,我最清楚 XD
圖是這張:
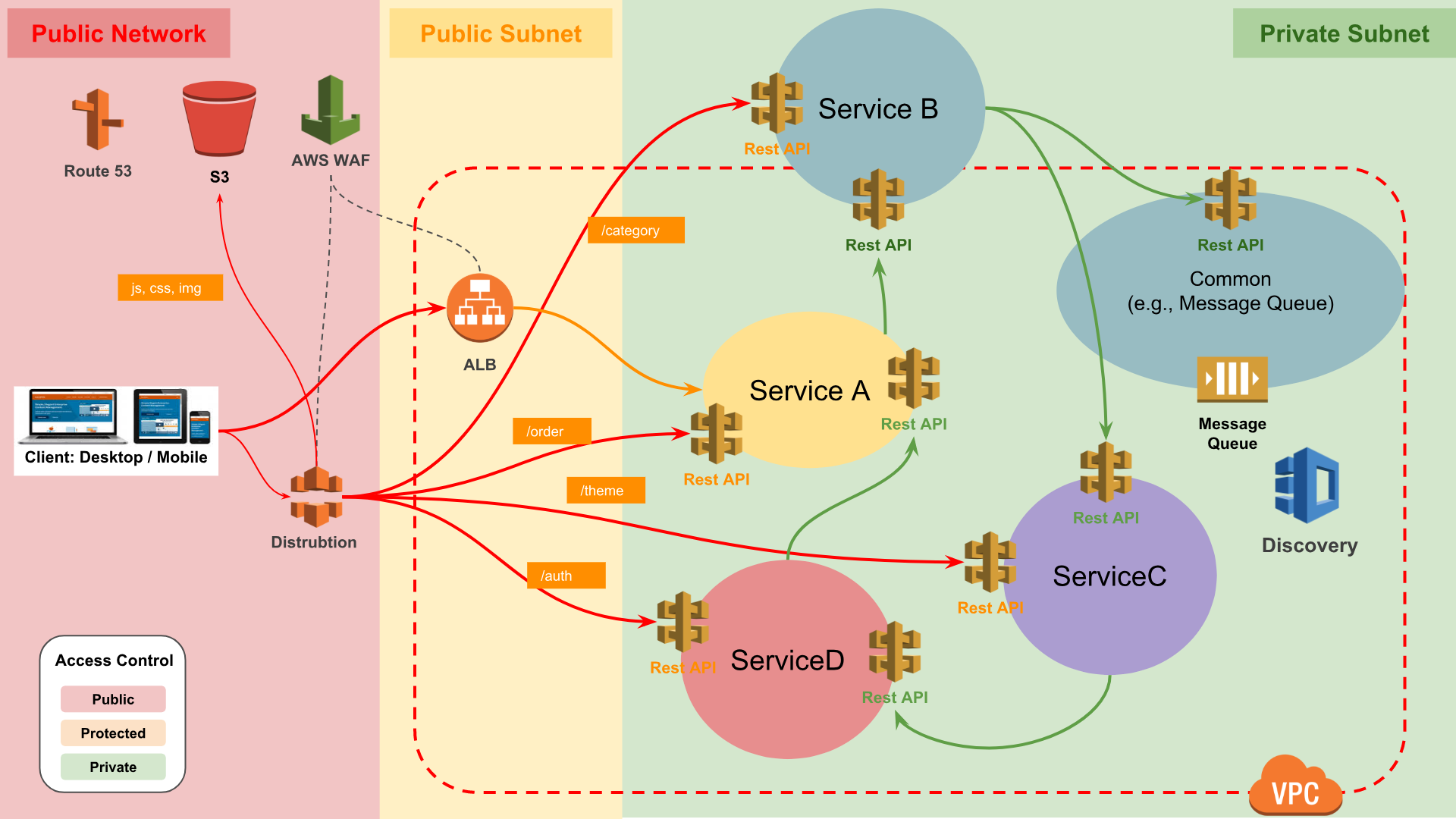
各個 Service 的 Capacity 要怎麼量測?
答案跟上一個一樣:
divide and conquer, 分而治之
我的答案始終如一,各個服務都要知道怎麼量測自己的容量,知道如何拆解自己的依賴、知道哪些是強弱依賴,最後的結論是可以透過數學公式,用推算的就可以算出來。例如圖中的服務量測的容量是:
- Service A: 1000
- Service B: 200
- Service C: 1500
- Service D: 300
那麼再針對這些實際的流量調整必要的資源,例如放大 B 五倍,放大 D 三倍,整體容量就差不多在 1000 上下。然後確認整體的網路頻寬吞吐是足夠的,基本上就可以宣告整體 Capacity 是 1000 了。至於 1000 的單位是什麼?那要看是怎樣的系統了。
請這樣思考:AWS Services 都有很大的規模,他們怎麼去提供彼此的依賴?準備實際的資源?通常不會真的去量測整個大系統,而是每個子系統都很清楚自己的容量 Beanchmark,以此為依據,然後用數學方法計算出服務之間的依賴狀況。
Q7: 如果沒有足夠資源與時間,怎樣快速評估系統容量?
我很常被問這問題,通常會依照經驗快速計算出粗略值。概念也是前面提到的演算法:
- 目前系統的資源做 Baseline,例如目前每天的機器數約 20 ~ 30 台 c5.xlarge 在跑,平均 CPU 在 60%
- 目前系統的 request 範圍在 150k / min ~ 170k /min (ELB) 數據
以此大概就可以快速推算出一個基數:
十台 c5.xlarge 的均值在 70k ~ 80k / min 的容量
當然這是在完全沒有時間量測前提,基於每天系統的狀況反推的。前提是:
你必須清楚每天線上有多少台機器在跑,以及他們的 Workload 是多大。
Q8: 步驟三描述的結果,如果是非線性怎麼辦?
實際上的量測,不會是純線性關係,也就是到了一定臨界值之後,就會變成非線性,概念如下:
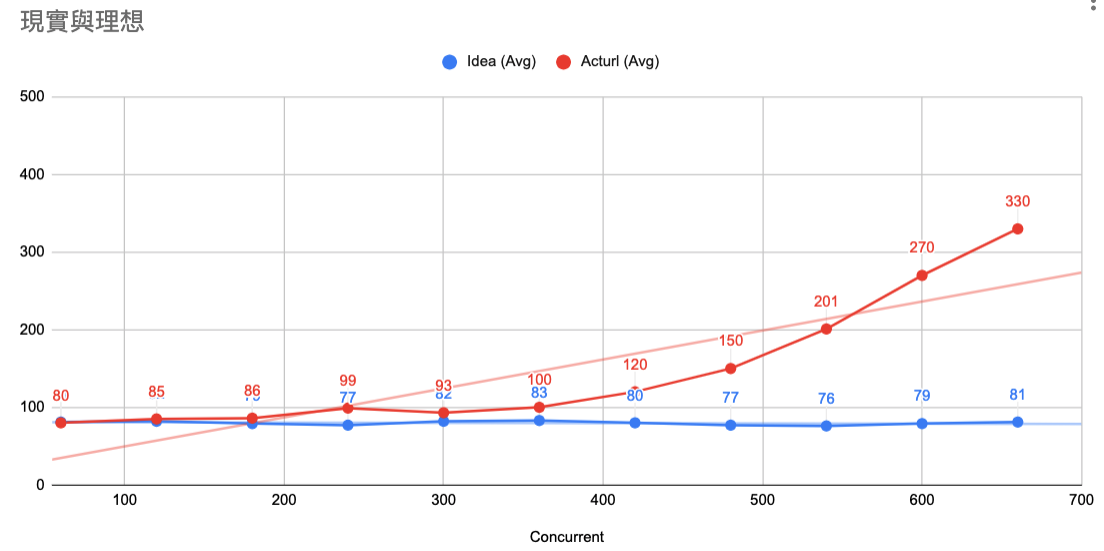
圖中的 Y 軸是 Latency、X 軸是 concurrent
- 藍色是理想值:一直在穩定的量測比例關系。
- 紅色是實際值:到了 concurrent 400 以上,整個狀態就往上飄了,呈現失控的狀態。
非線性的原因可能是肇因於網路拓墣、或者分散式架構。但是這時候要思考的是:
- 系統本身就有物理上的極限,即使是很強的機器,或者規劃很好的分散式架構
- 需求是什麼?這個案例,搞不好需求 RPS 200 就夠了?後面也只是測爽的。
- 但時間允許,請繼續深究,功力會有一甲子累積。
現實跟理想,要取得平衡。
Q9: CI / CD 流程要整合效能測試?
很多文章都會講:
CI / CD 要把壓力測試整合進去,每次都跑。
概念上沒有錯,但實務上要考慮以下:
- 待量測體的規模與量測目的
- 整體的系統架構規模與依賴性
- 量測頻率
- 環境建置與資料還原
- 成本考量
當這些都可以很清楚的定義,而且大家可以接受 (特別是成本),那就可以整合,否則大部分我會建議 每季 至少執行一次容量的量測。
Q10: 你在 淺談效能測試 提到有三種,哪一種比較重要?
先說結論,針對 Web System 的重要性:
- Capacity 2) Reliability 3) Stability
Capacity 是量測系統在基於基礎條件下的承載量,Capacity 下一個要做的是系統的可靠性 Reliability,前面有大概描述有哪些項目,有空再整理專文。
Updated 2020/04/22: 請參考: 可靠性工程 Reliability Engineering
最後一個是 穩定性驗證 (Stability),一般 Web System 比較少做這種驗證。穩定性驗證 (Stability) 與容量測試截然不同,他的結果不是一個數值,而是:
- 自然流量,長時間之下的統計結果
- 過載之後,長時間之下的統計結果
這兩個都在探索會不會有 Memory Leak、Deadlock、Resource Lock、Kernel Panic 等現象,通常 Embedded、設計 DB engine、Compiler 比較會有這種驗證,一般 Web App 不太需要注重。
Q11: 這個題目為啥是放在 SQA 這個分類裡?
我知道很多單位是讓 Ops / Infra / SRE Team 做 壓力測試,但我卻不是這麼認為的,而且那不叫 壓力測試,大部分人講的都是容量量測。
而我把這個題目放在 SQA (Software Quality Assurance) 這個分類,是因為我認為這算是 SQA Team 的職責,理由如下:
- 軟體的品質不僅止於產品功能,還包含非功能性驗證,其中也包含系統容量量測
- Ops / Infra / SRE Team 應該在部署前,就已經知道系統容量的基準值 (Beanchmark),以此作為依據,決定部署策略。
- 如果業務單位有行銷活動,Ops 也會問應該會帶來多少流量,依此強度去配置系統
- 每次部署狀況,都依照此數據決定部署策略,該是 Canary、Blue / Green、A/B
- SQA 提供容量基準值數據,Ops / Infra / SRE 以此作為成本估算依據
- 如果要執行 Reliabilty 相關的工作,就更需要 Capacity 的數據。
- 像是 Chaos Monkey
- Fault Tolerance
- DR
- Highly Available
所以 SQA 的工作應該包含容量量測,而 Reliability 才是 SRE or Architect 的工作。
台灣的很多 QA Team 其實是沒這樣的能力,因為大部分 QA 比較專注在產品功能,對於系統架構通常沒有認識、或者無法獨立建置環境,倚賴 Developers 或者 Ops / SRE / Infra Team 的 CI/CD … 導致 QA 的價值一直被質疑。沒有工程能力,也沒有深度的 Domain Knowhow,最後很容易變成沒門檻的免洗筷。
這是普遍的現象與現狀,但我覺得這是有問題的,相關整理與想法參閱:
Q12: 雖然你一開始說不推薦工具,但還是可以推薦一下嗎?
- 完整的:
- 簡易工具:
- apache ab
- stress-ng
Q13: 我們的系統有用 EC2 Auto Scaling,那要怎麼測量你說的容量?
先不用管有沒有 Auto Scaling,先量測單一 Instance 的容量是多少,有此 Beanchmark 數值,之後的 Auto Scaling 只是讓你用線性方式 擴容。
這跟有沒有用 Auto Scaling 沒關係。
同樣的概念套在 K8s 的 Pod 也適用。
Q14: 瞬間流量,要怎麼量測?像是雙十一那種的。
這問題可以參考 EC2 Auto Scaling 常見問題,底下簡述:
- 瞬間流量要靠的是
限流機制 (Rate Limit)+排隊機制+擴容架構+快取機制處理。 - 當限流可以做到限性控制的時候,瞬間流量進來就是考驗擴容的速度了。
- 快取可以做到肖峰填谷,也就是分層過濾流量,概念如同
AARRR的漏斗。
瞬間流量跟量測容量是不同概念,容量只是解決瞬間量的其中一個環節。
Q15: Database 的測量要怎麼做?
Database 通常會是系統架構的瓶頸之一,但是應用層的應用變化百百種,實務上建議針對最主要的功能 個別 做量測,例如:成立訂單、商品資訊、分類頁、活動頁 … 等。針對這些功能個別使用固定的架構(假設是 Web -> App -> DB 這樣的架構),先找到功能與最佳的資源組合,例如:成立訂單最佳的組合、商品資訊最佳的組合 … 等。這時候會找到一個最大的 Database 資源組合,這就是 Database 的短板了。
另外提一個重要的設計概念:
系統已經可以提供 Capacity Unit,像是 Write Read Throughput / Second,那麼所謂的
量測容量這件事情是可以不用做的,只要拿張紙,算一算就可以知道了。 一個可維運 (Operable)的服務,應該都是可以直接提供 (Provisioned)線性的容量單位 (Capacity Unit),使用者透過計算,就可以估算出容量。類似概念在 AWS 的 DynamoDB、ALB 都有。我最常舉的例子就是 DynamoDB 的設計,相關概念參閱 DynamoDB 學習筆記。
Q16: Cache (Redis) 的量測要怎麼做?
這問題怪怪的,Cache 本身不是一個設計來做長期容量算計的,如果超過 TTL 或者 Size,基本上就會使用內部的淘汰機制 (Eviction Policy) 處理,了解 AP 對於這種情境的處理。
Q17: 基於特定背景,例如固定有 1000 rps 的流量之下,然後在此條件的前提,再做壓力測試算在你說的範疇?
這前提是系統在有固定自然流量的前提,然後特定功能使用量突然增加。舉例電商來說:自然流量是 商品頁瀏覽,突然增加的流量是 結帳頁。
這其實也算是容量的量測,只是有特定的背景條件。可以先把固定流量當作基準值,然後以此作量測。
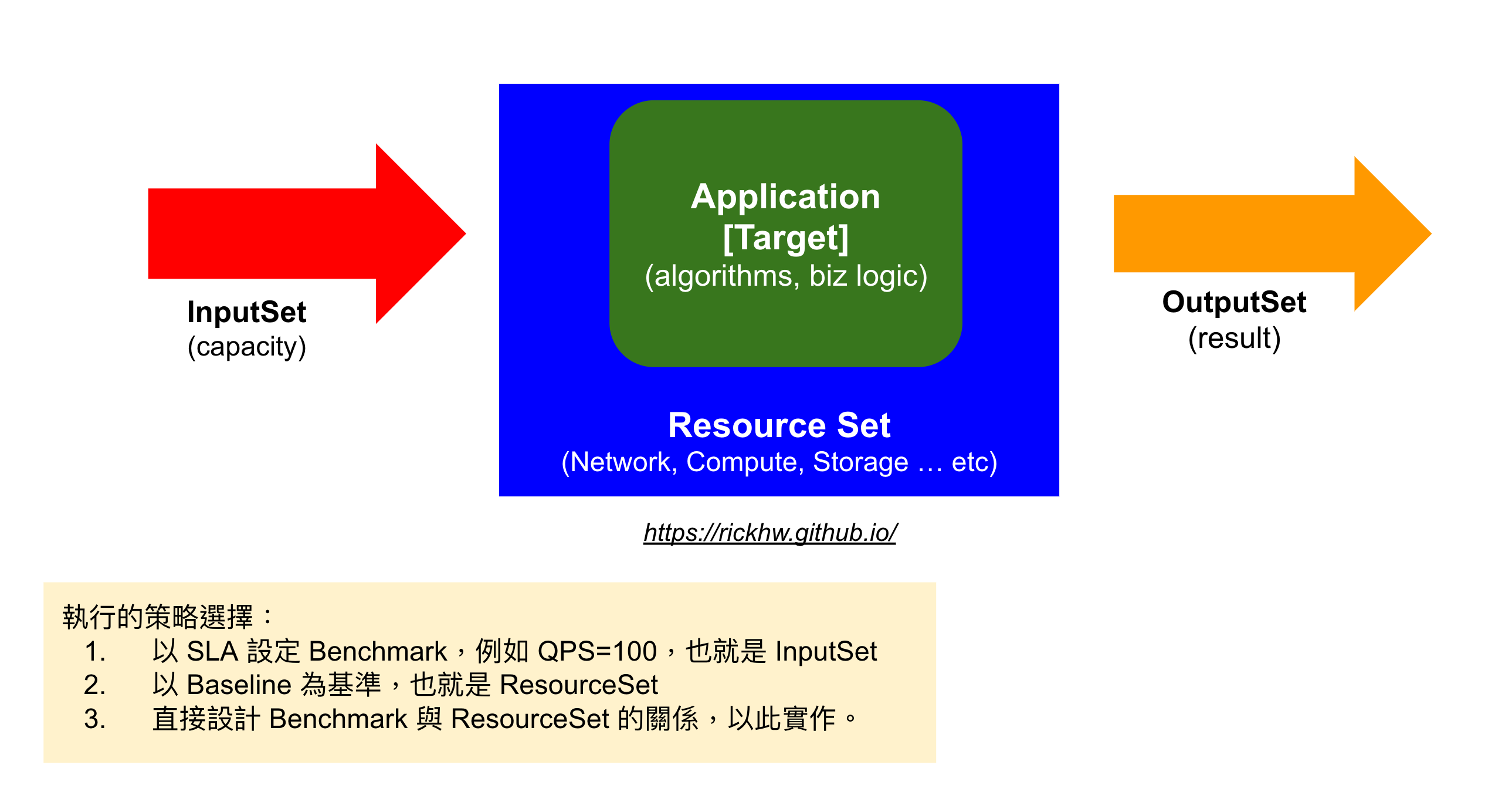
Q96: 系統容量有沒有什麼策略性選擇可以參考,當做切入點?
三種策略性選擇的思路:
以輸入為基準值:例如業務目標是 200QPS,以此找到系統資源的 Beachmark以系統資源做基準值:例如用已知的資源做基準,例如一台 c5.xlarge,然後找到輸入的理想值應用程式設計基準值:也就是 SLO,例如直接以 100QPS、以 c5.xlarge 為組合基準,以此開發應用程式
這三個策略,如果是有考量 SLA 的新服務,建議用第一種當目標,也就是業務導向,找到所需要的資源。
如果是既有的系統,像是一套 Legacy 推播系統,想要知道它的容量,那麼就用第二種方法。
如果是全公司的架構設計團隊,準備設計給其他團隊使用的功能,那麼一開始就要使用第三種方法,直接定義目標 (SLO)。當然定義目標的過程,會在選擇一、二中遊走,最後找到第三個的基準值。整個概念如下圖:
Q97: 如果系統是跑在 K8s 上,這個概念也是一樣?
一樣。請先了解整個 Request 的 Traffic 途徑,包含 Ingress、Service、Pod … 等關係,了解之後先測個別的服務,測完再測整個的。
Q98: 有沒有實際案例可以分享?
推薦我朋友 Earou Huang 在社群的分享:為瞬間巨量做好準備, 20180726
這場分享,基本上就是這整篇整理的實踐紀錄之一。
Q99: 可以總結,量測容量的前提與準備工作?
簡單條列如下:
- 功能驗證要過:基本的業務邏輯要完善,再來談容量量測。不要以為我在講幹話、開玩笑,我真的遇過功能不能用,跟我要求要做容量量測的。
- 釐清系統架構:
- 包含邊界、角色、通訊、內外依賴等定義
- 釐清網路拓墣、網路頻寬、WAN / LAN 邊界、DNS / Auth 相關基礎服務
- 如何表達系統架構概念參閱 演講:從緊急事件 談 SRE 應變能力的培養,Slide 的 P64 ~ P97
- 建置整個系統環境,相關參閱 Resource Provisioning and DevOps、Artifacts Management
- 準備蒐集待測體的 Log、Metric 等機制,相關參閱:淺談系統監控與 CloudWatch 的應用、Monitoring vs Observability
這些都仰賴平常的基本功與紀律,不太容易一蹴可及。
結論
經過上面的方法論,才可以大概 探索 (Discovery) 系統的容量,而這個過程就是在 量測 (Measure)。如果覺得太難懂,那換個方式說好了:
如果你想知道一個人的食量有多大,那麼就請他先去量體重,然後點一堆餅,餵他一直吃,像這樣:

如果他回答:

那就繼續餵他,直到他說吃不下了,趁他還沒吐之前,抓他再去量一次體重,或者回去盤點到底吃了多少餅,這就是他的 Capacity 了。
延伸閱讀 (站內)
軟體測試
DevOps / SRE
- Artifacts Management
- 聊聊軟體交付的濫觴 談產出物管理 - DevOps Taiwan Meetup
- 軟體交付的四大支柱 (Four Pillars of Software Delivery)
- 演講:從緊急事件 談 SRE 應變能力的培養
- DevOps 8 字環的誤區:左環問題
- Resource Provisioning and DevOps
- 淺談系統監控與 CloudWatch 的應用
- Monitoring vs Observability
系統架構
- 聊聊分散式系統
- 可靠性工程 Reliability Engineering
- API Gateway - Rate Limit and Throttling
- 分散式系統設計 - 正體中文版
- Study Notes - EC2 Auto Scaling 常見問題
- DynamoDB 學習筆記
- Mini PC 效能實驗:實測 Throughput / RPS / C10K
參考資料
- 為瞬間巨量做好準備 20180726 - Earou Huang
- MySQL Challenge: 100k Connections
相關事件
- 2020/03/21: Backend 台灣討論,關於搶購的建議
- 2020/02/06: 4小時爆賣95萬片!口罩實名制上路官網爆量,健保署緊急調高頻寬並釋出開放資料
- 2020/02/06: 館長 300 萬的新網站,究竟出了什麼問題?
- 2020/01/23: 小年夜/館長與大家同樂 花費300萬新網站 讓館長好無言
更新紀錄
- 2019/09/20: 初版
- 2019/10/02: 加入多個新問題,重新排序。
Comments
About
著作
演講
- 演講錄影 @ Youtube
- 探索職涯、複利人生 - AWS Career Exploration Day 2023
- 個人著作 SRE 書友見面會
- 軟體測試實務 - 新書發表會
- 探索職涯、成就未來 - AWS Career Exploration Day 2022
- 從理想、到現實的距離,開啟品味軟體測試之路
- 91APP 在 AWS 上的 SRE 實踐之路
- 在矩陣型組織裡,如何有效管理 AWS 的成本結構與系統架構
- 災難演練 @ AWS 實戰分享
- 導讀持續交付 2.0 - 談當代軟體交付之虛實融合
- 聊聊軟體交付的濫觴 談產出物管理
- 從緊急事件 談 SRE 應變能力的培養
- 邁向 API 經濟 - API Gateway 導入之旅
- Monitoring Tools 大亂鬥 - AWS CloudWatch
- Ops as Code using Serverless
- 淺談系統監控與 CloudWatch 的應用
AWS Certifications


