Whitepaper - Using AWS for Disaster Recovery
以下這張照片是 Jan, 2015 在 AWS Virginia Data Center 火災的照片:

圖片來源: Amazon data center on fire in Virginia - CNN
其實災難,不管是個人還是在企業,隨時隨地都有可能發生。當企業成長到一定的規模,災難還原計畫,就越來越重要。但是做災難還原準備工作,本身在公司裡面不是所謂的 產出 任務,他屬於 備援 計畫,而且災難復原在傳統的 IT 架構裡,所需要的預算、人力、資源、時間是相當龐大的,大部份的老闆,對於這件事情是不會支持,或者也不太願意投資的。最多做所謂的 異地備援 就算是很不錯的了。
以下整理 Whitepaper - Using AWS for Disaster Recovery (Oct, 2014) 內容。大部份的圖檔都是文件裡擷取出來。
Introduction
Disaster Recovery (中文翻譯 災難還原, 簡稱 DR) 主要是災難發生前的準備到,災難發生後還原系統的過程。
RTO and RPO
RTO (Recovery Time Objective): 能夠完成系統還原的最大時間RPO (Recovery Point Objective): 能夠還原的資料時間點
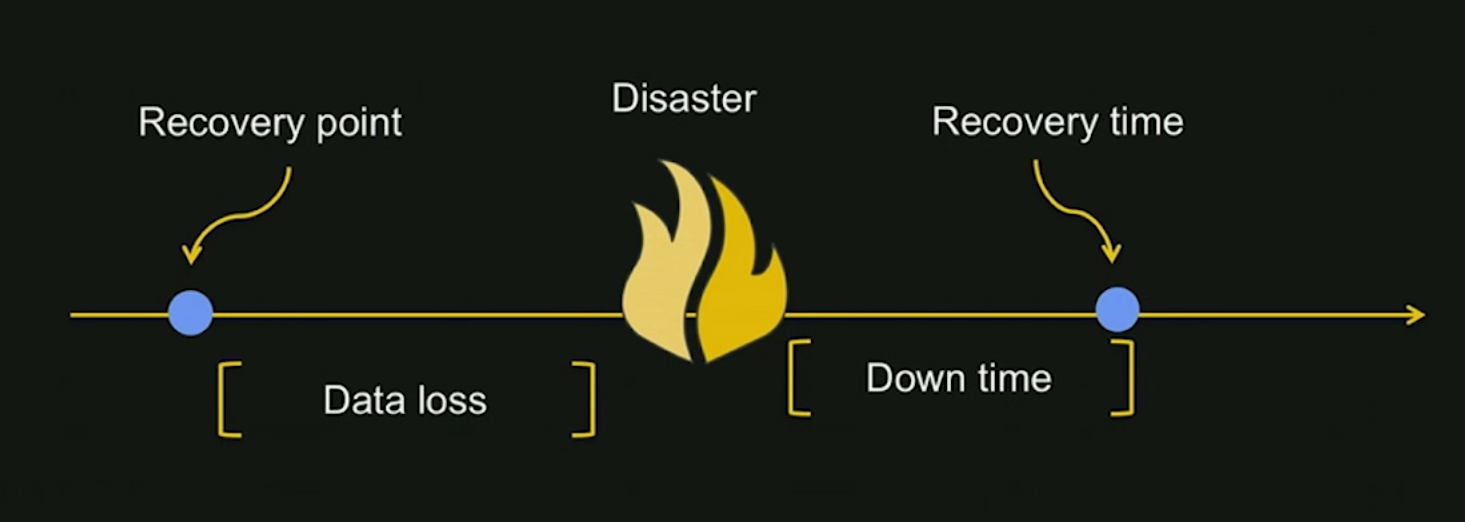
圖片來源:AWS Summit Series 2016 | Chicago - Deploying a Disaster Recovery Site on AWS
Strategies
執行 DR 本身是一件耗成本、需要動用大量資源的任務。如何選擇正確的策略是非常重要的,下圖是四種常見的策略:
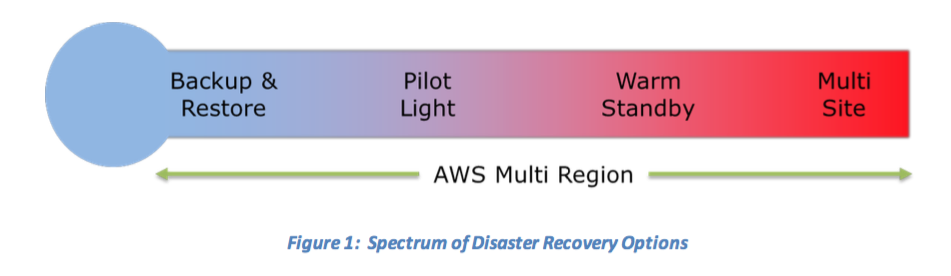
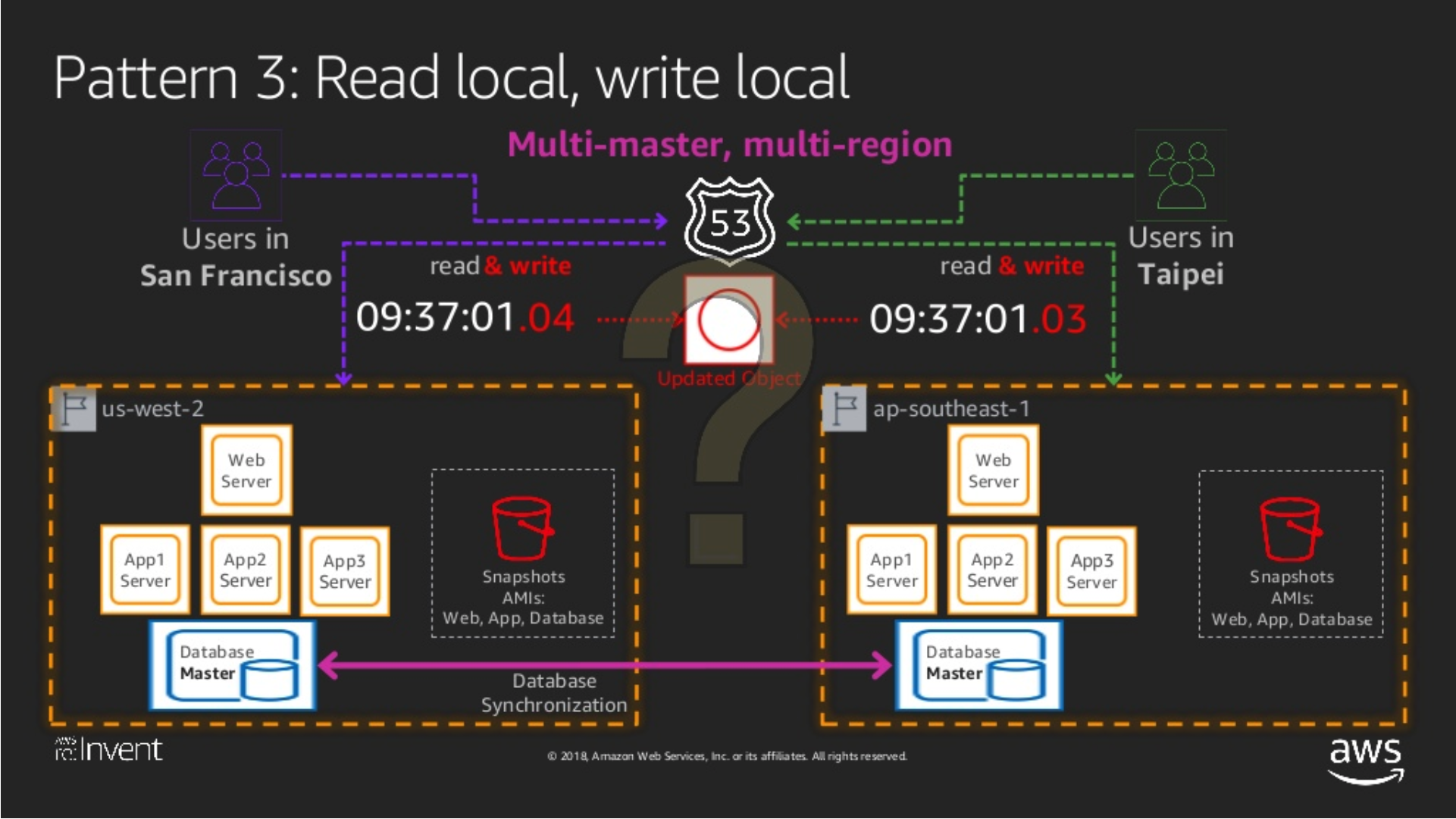
底下的圖,摘錄自:AWS re:Invent 2018: Architecture Patterns for Multi-Region Active-Active Applications
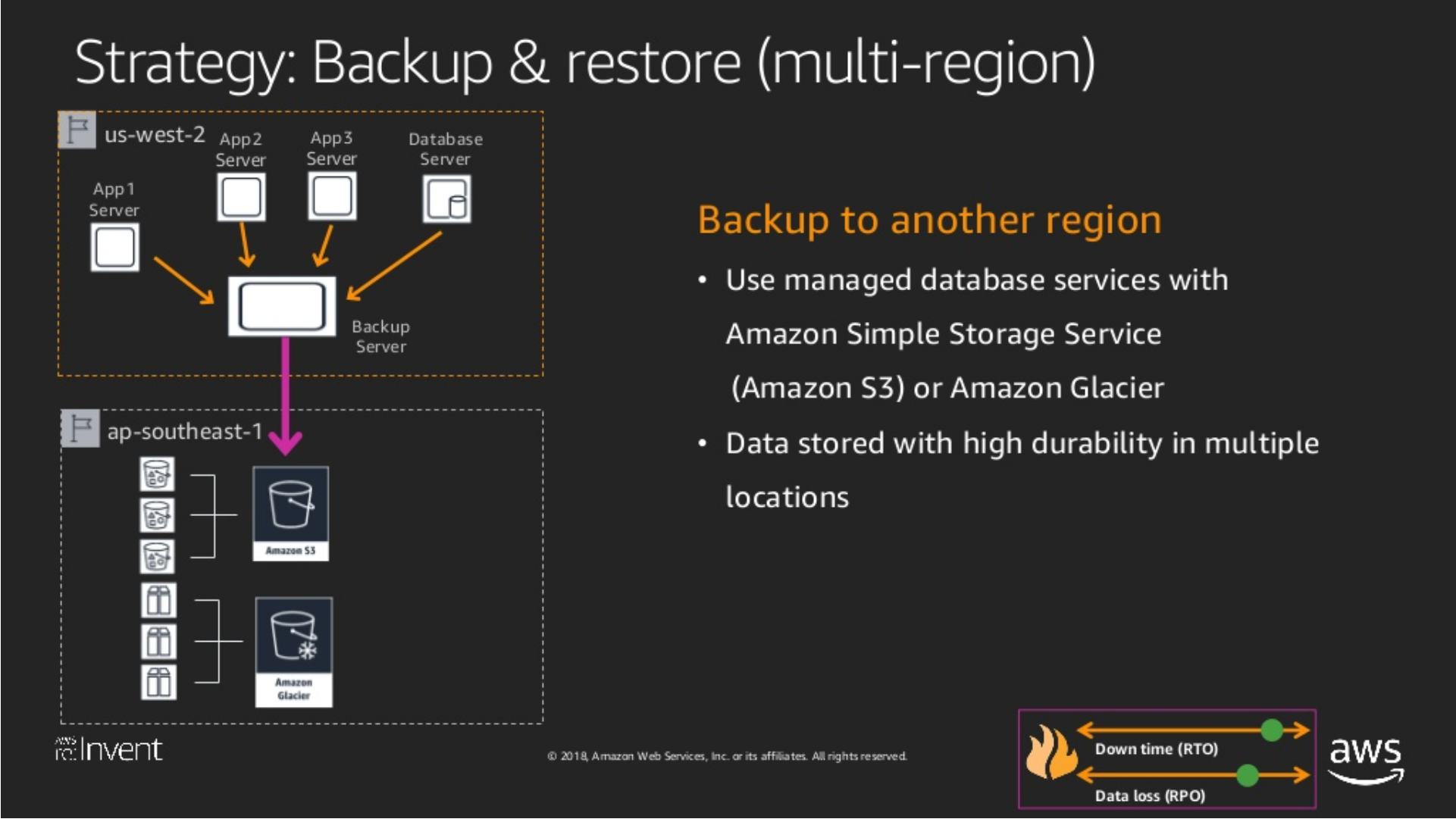
Backup and Restore
下圖表示的是最基本的,即時沒有要做 DR 也應該要做的。一般要備份的有以下幾種:
DB: 不管是透過批次、還是 Replication 機制。MySQL 使用 Replication、SQL Server 使用 Always OnData: 使用者資料,通常會儲存在 S3,然後透過 Cross-Replcation 備份。
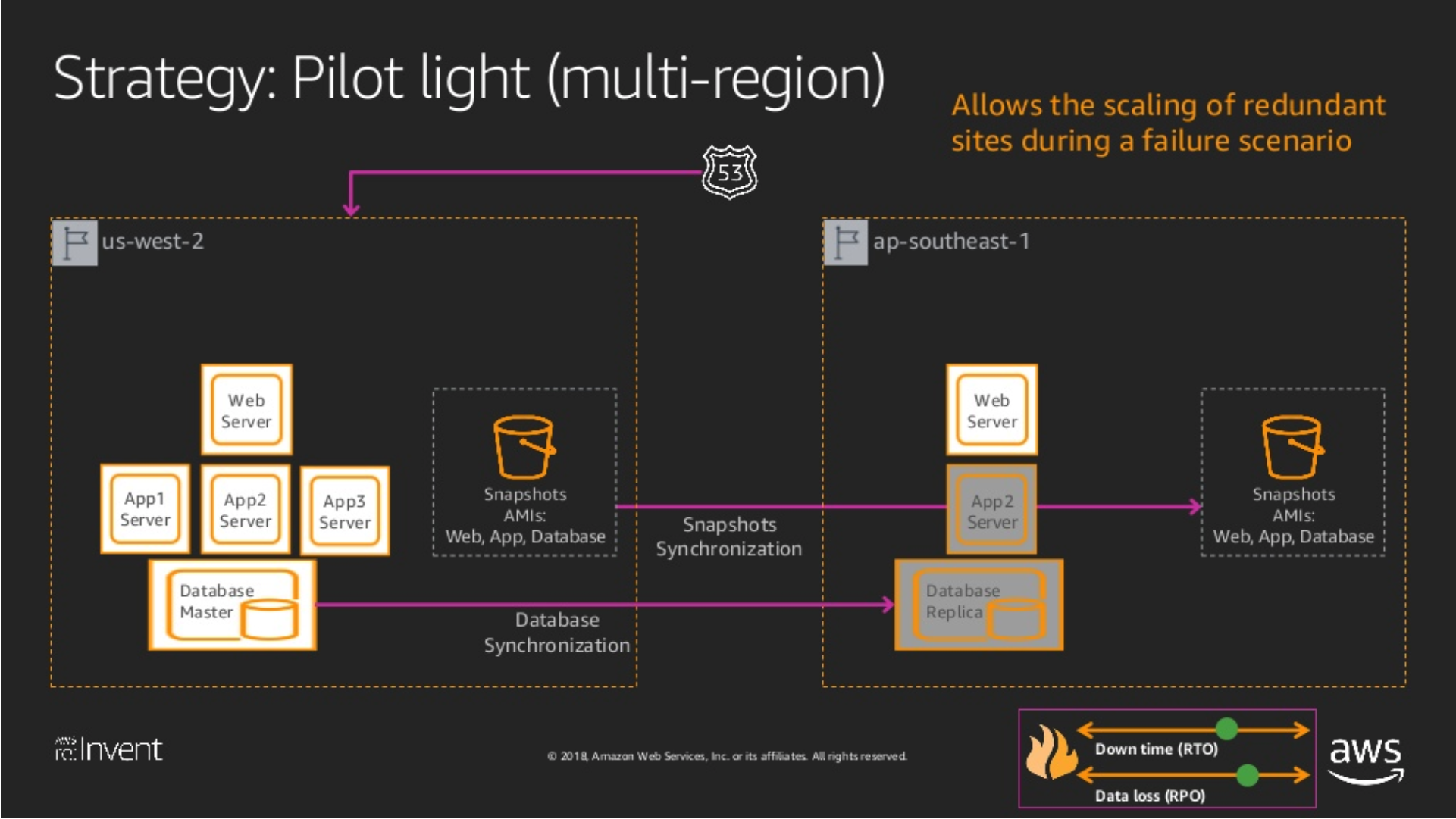
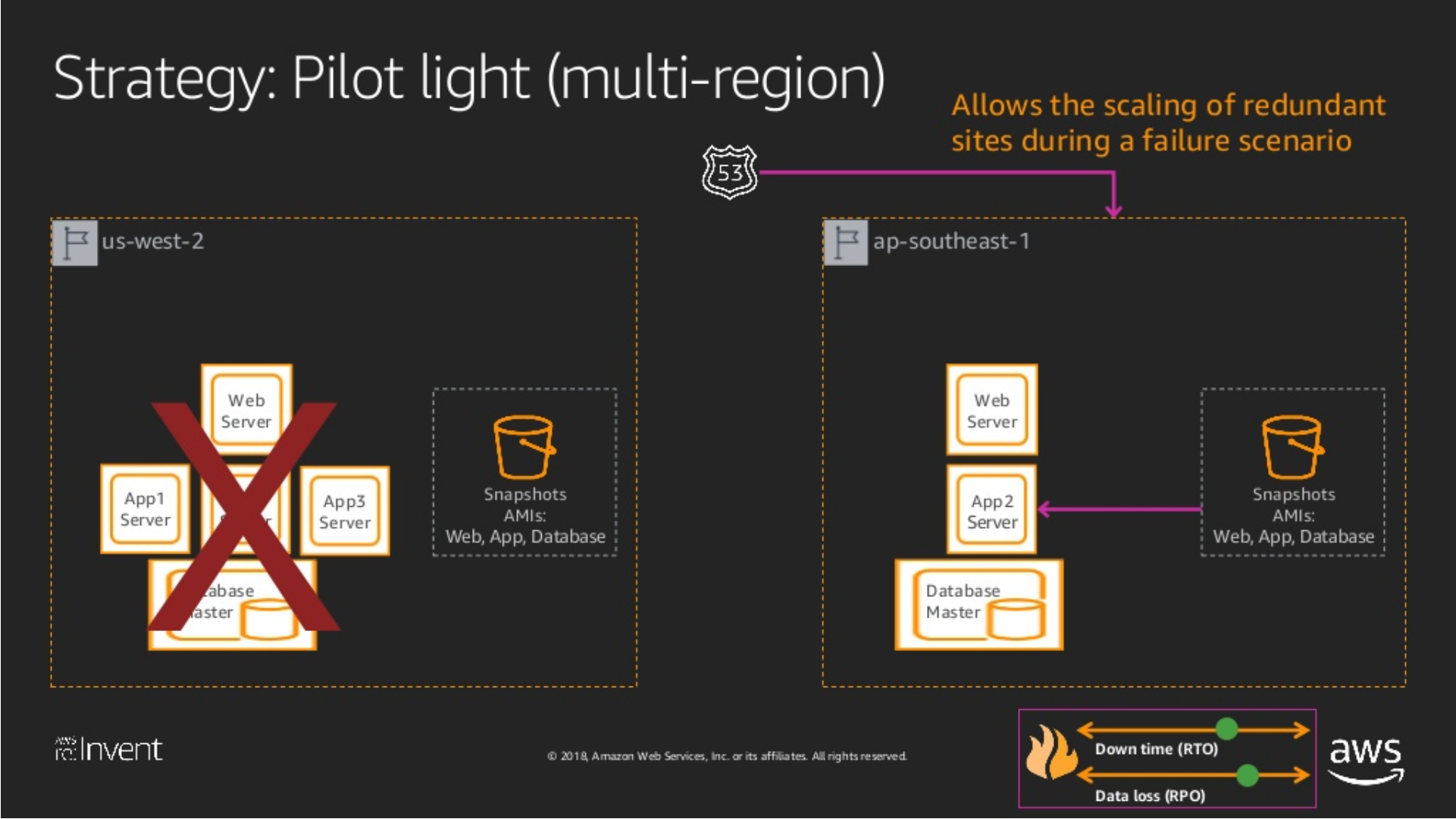
Pilot Light
Pilot Light 除了第一個備份之外,另外也把 AP 的 Artifact / Configuration 部署過去了,包含以下:
Artifacts: 應用程式的映像檔 (Image)、Package (maven, npm, nuget, docker)、虛擬機映像檔 (AMI) … 等Configuration: 應用程式的配置檔
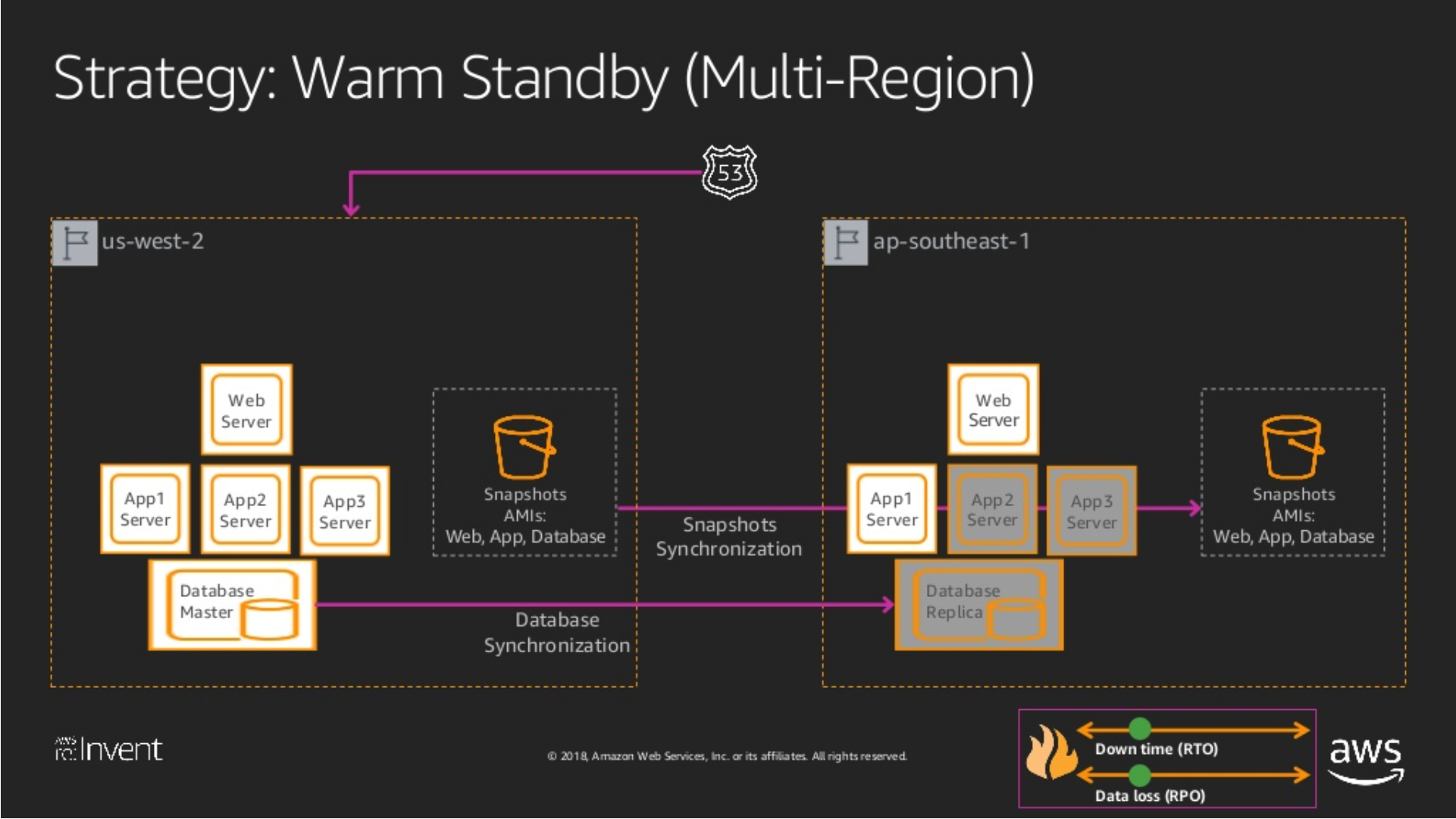
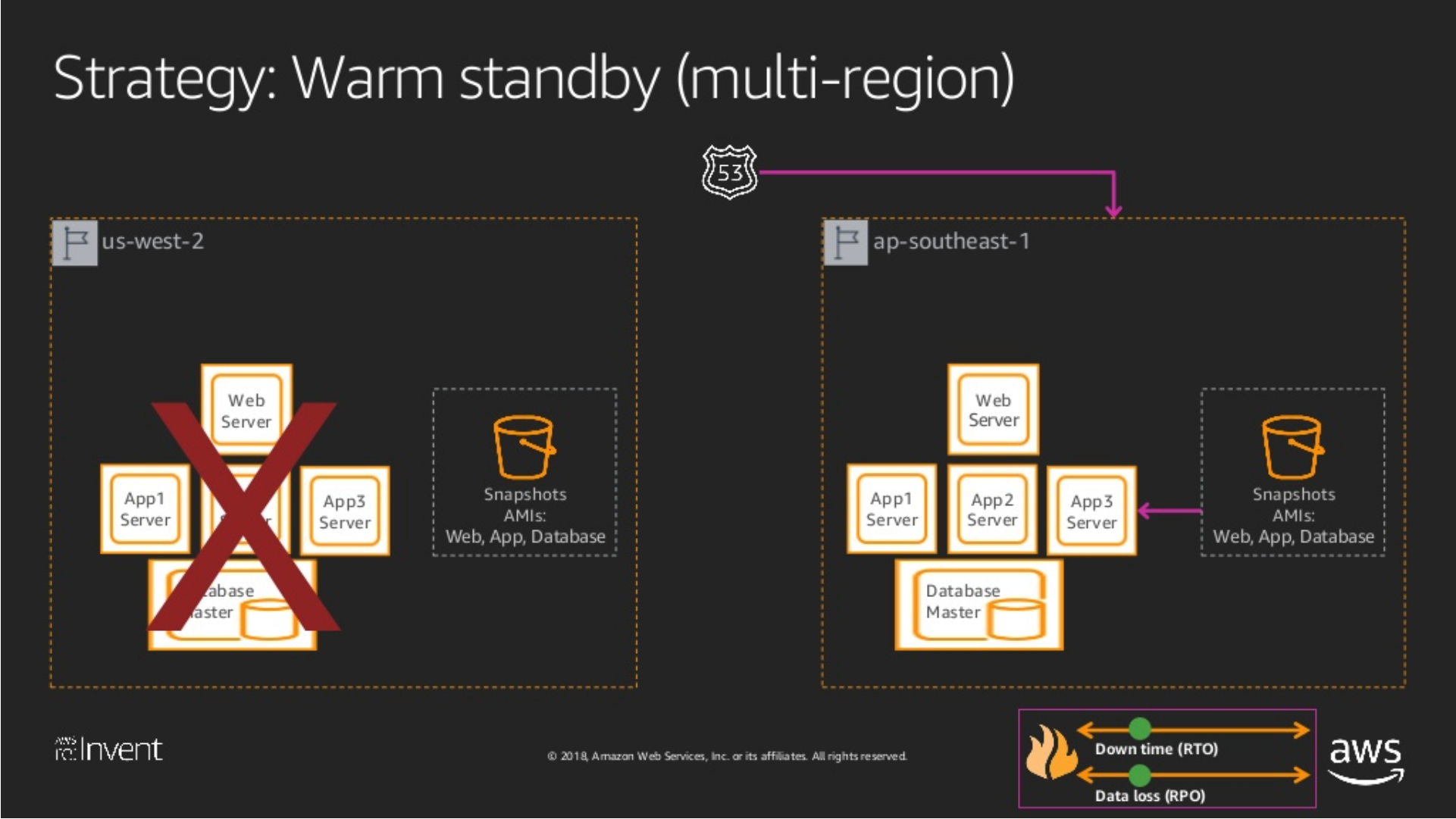
Warm Standby
Warm Standby 要一個整個 Stack 的做小集合都可以跑了,換言之他只是比較小的 Production Set,所以除了前述的藥丸被,另外要完備的就是:
Infra Config: 其他基礎設施的設定,像是 Networking, Managed Services … etc.
這些都完備了,其實代表的就是隨時可以把新的版本,部署到這個 DR Site。
Multi-Sites
完整的 Production Set,除了前述的準備,可能連 AutoScaling 之類的也都已經完成。
Cost and Strategies
這四種策略不難懂,但是他其實跟 成本 有息息相關,我畫了一張圖表達 策略的選擇 與 成本結構 的關係:
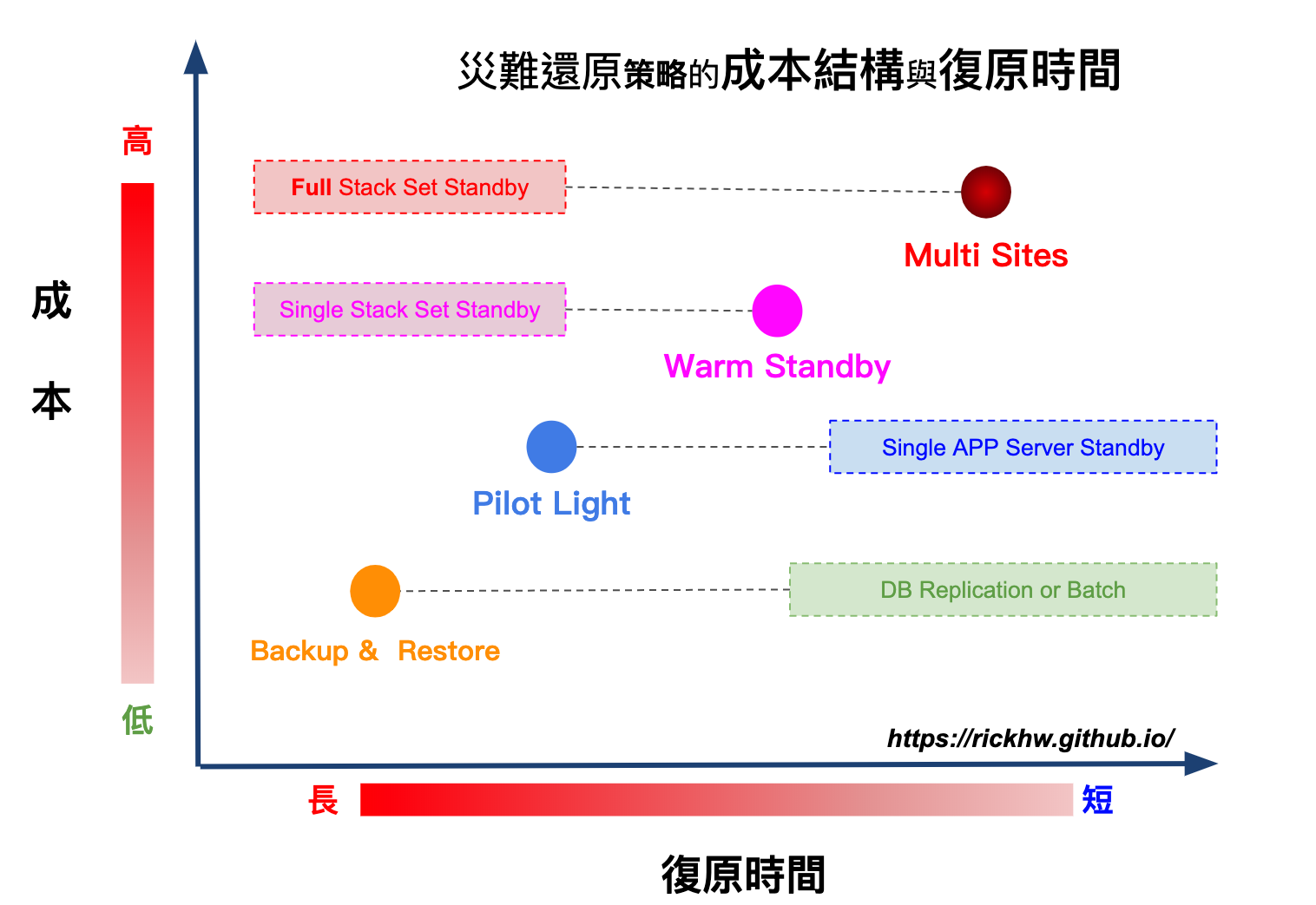
如果是自建機房,那麼成本以及執行的項目,會更加可觀。而使用雲端機房,則最多的就是管理成本,另外很容易被忽視的就是:資料傳輸的成本。
FAQ
- DR 和 HA 一樣?
Q: HA 指的是用冗余 (redundant) 增加可用性,DR 指的是在不同資料中心還原服務能力。
- 怎樣的情境需要啟動 DR Plan?
Q: 哥吉拉登入日本東京,AWS 東京機房毀了。
- BCP 和 DRP 有什麼不一樣?
Q: BCP (Business Continuity Planning) 包含幾個面向:
- 高可用 (High Availability): 高可用的解決方法就是增加服務的
冗余 (redundant)- 持續維運 (Continuous Operations):設備故障時,要能夠確保業務能夠持續運作的能力。
- 災難復原 (Disaster Recovery): 只發生異常的時候,在不同資料中心還原服務能力。
所以 DR 只是 BCP 的其中一個項目而已。
- Service Catalog 跟 DR 的關係?
Q: 參見:Service Catalog
- 開發業務團隊跟 DR 的關係?他們要知道些什麼?
Q: 大概要知道 Resource Provisioning and DevOps、Artifacts Management、怎樣的 CI/CD 才夠 Quality?、Config Management、Pipeline … 大概就是 軟體交付的四大支柱 (Four Pillars of Software Delivery) 提到的東西都要知道。換言之,平常測試階段,如果這四個東西都沒有的話,DR 會很難做。如果有多種業務市場,那麼 Service Catalog 也要考慮。
- 災難演練的目的是?
Q: 除了確認系統可以正常恢復,另外也可以藉此演練培養團隊的應變能力,從中發現團隊不足的地方。像是 輕鬆聊:系統測試 (SVT) 的三兩事 提到的概念。
後記
這篇草稿原本在 2016 年就寫了,但是一直沒有發佈。今年 (2019) 很多知名的 IT Provider 發生了幾次事件,特別是 AWS:
- 2019/09/04: 台灣捕夢網事件
- 2019/08/31: 美東 Virginia (us-east-1)
- 2019/08/23: 北亞 Tokyo (ap-northeast-1)
而我也正在準備年度的演練計畫,因為這些事件堆疊,藉由熱點事件,我也在內部做了教育訓練與宣傳,分享了以下的簡報。
最後引用 Chaos Engineering 裡一段我很喜歡的話結尾:
不是你選擇那一刻,是那一刻選擇你,而你唯一能選擇的就是作好準備。 (You don’t choose the moment, the moment chooses you.)
最後,更多實際的執行經驗談,參見:災難還原 - 實戰演練 - AWS reInvent reCAP 2019
延伸閱讀
站內資料
- Artifacts Management
- GitHub Post-Incident Analysis
- Service Catalog
- Chaos Engineering (混沌工程)
- 怎樣的 CI/CD 才夠 Quality?
- 軟體交付的四大支柱 (Four Pillars of Software Delivery)
- Resource Provisioning and DevOps
- 演講:從緊急事件 談 SRE 應變能力的培養
- 輕鬆聊:系統測試 (SVT) 的三兩事
- 災難還原 - 實戰演練 - AWS reInvent reCAP 2019
參考資料
- Whitepaper: Using AWS for Disaster Recovery, October 2014
- Whitepaper: Building Fault-Tolerant Applications on AWS, October 2011
- AWS Summit Series 2016 Chicago: Deploying a Disaster Recovery Site on AWS
- Amazon data center on fire in Virginia - CNN
- Best Practices for Backup and Recovery: Windows Workload on AWS
- AWS re:Invent 2018: Architecture Patterns for Multi-Region Active-Active Applications, Slide
- 業務連續性計劃
相關新聞
Comments
About
著作
演講
- 演講錄影 @ Youtube
- 探索職涯、複利人生 - AWS Career Exploration Day 2023
- 個人著作 SRE 書友見面會
- 軟體測試實務 - 新書發表會
- 探索職涯、成就未來 - AWS Career Exploration Day 2022
- 從理想、到現實的距離,開啟品味軟體測試之路
- 91APP 在 AWS 上的 SRE 實踐之路
- 在矩陣型組織裡,如何有效管理 AWS 的成本結構與系統架構
- 災難演練 @ AWS 實戰分享
- 導讀持續交付 2.0 - 談當代軟體交付之虛實融合
- 聊聊軟體交付的濫觴 談產出物管理
- 從緊急事件 談 SRE 應變能力的培養
- 邁向 API 經濟 - API Gateway 導入之旅
- Monitoring Tools 大亂鬥 - AWS CloudWatch
- Ops as Code using Serverless
- 淺談系統監控與 CloudWatch 的應用
AWS Certifications


