聊聊 Harness Engineering
最近除了自己持續研究 “作業系統實作“ 相關議題,跟 AI 趨勢的概念也是沒有停下來。Harness Engineering 是最近我持續在關注的課題,相關的技術也是持續在爆炸的生出來。
整理 2026/04/28 隨筆: 聊聊 AI 發展趨勢 以及 Harness Engineering 的想法。
Harness?
知道 Harness (馬具) 這個字,是在我 “Designing Test Architecture and Framework“ 時期,就有整合一個叫做 CLI Harness 自動化程序,他主要負責測試 網路防火牆路由器 (待測產品) 的所有 CLI 指令是否正常運作,我記得有 400+ 的 Test Cases,全部透過 ssh / telnet 方式,透過比對輸出文字的方式驗證功能是否正常。這是每個版本出貨前都要測試的,當時有 4 個 LTS branch + main version (Trunk-Based) + 40+ 多個客戶版,所以只要改動 (feature or bug fix) 有影響的範圍都要跑,而這個產品的客戶都是歐美日各大銀行。所以這產品的 Regression Test 是非常重要的。
映像很深刻的是當時團隊的工作流程,用現在的眼光來看,其實就是一種 TDD 的概念,但在當時團隊的結構,是由開發者實作功能邏輯,由 QA 團隊實作自動化測試 (BlackBox),透過 CLI Harness 方式驗收功能是否正常。當時團隊開發與測試是同步作業,所以大家其實平常工作都是一起進行的。這個經驗放到現在來看更有意思 — 現在 Agent 系統幾乎都在強調 Eval-Driven Development (#EDD, 評估集驅動開發) ,本質上就是把當年我們做 BlackBox 測試的思維,直接內建到 Agent 的執行循環裡。
Harness Engineering
回到現在 AI 時代的 Harness Engineering,會跑出這樣的概念從整個歷史趨勢來看,一點都不意外。因為 Prompt Engineering、Context Engineering,都缺乏了一個可以控制 AI 能夠穩定的、持續輸出可靠品質的方法。最核心的 LLM 每個月都會有新的突破,誰又超越誰了。附圖整理過去 2023 - 2026 相關 AI 發展演進的時間點。
寫這篇文章的時間點是 2026/04/27,我相信很快地又會有誰超越誰,誰是 OOXX 之王的稱號 (媒體炒作)。同時,Open Source / Local LLM (Gemma4, Qwen, MiniMax, DeepSeek) 也同步在嘗試能否改變,兩邊整天打來打去。
所以,然後呢???
其實大家慢慢都發現了,單純擴大模型參數帶來的邊際效益正在遞減。注意,這不等於 LLM 整體能力觸頂,重點是已經轉移到別的地方:
推理時計算 (test-time compute):讓模型在回答前多想一下,像是 延長思考鏈、self-consistency 那種做法。OpenAI o1/o3 系列就是這條路線的代表。工具使用與 Agent 化:讓模型不只「回答」,而是真的「動手做」,呼叫 API、跑程式碼、操作檔案系統。後訓練階段的RL (Post-training RL):這是個關鍵變化。LLM 訓練分兩階段,先是 Pre-training (預訓練) 用海量網路文本學會「下一個 token 是什麼」,再來是 Post-training 用 RL 把模型雕琢成能聽指令、會推理、夠安全的樣子。
也就是說,現在 LLM 的能力提升主軸,已經從 「pre-training 加大模型」 轉移到 「post-training 用 RL 雕琢推理與工具使用」。這也是為什麼模型參數沒變多少,但 Agent 表現一直在跳。
Context Engineering
同時不管是哪一個 LLM 用久了,就開始會有幻覺、記憶力短缺,所以出現了 Context Engineering,試圖要處理這些問題,出現了一堆工具,像是 OpenClaw。特別是 Cloud 版本的 LLM,幻覺問題越來越嚴重,像是 Opus 4.6 在 2026/02 被一堆工程師靠北一直前後文不對,影響工作與產出。
來來回回,現在的狀況大概就是:
- 有個聰明的大腦 (LLM, Ph.D),不管這顆腦是在雲上、還是在本機 / 移動端
- LLM 只要用一段時間,就開始忘東忘西,跟老年癡呆沒啥兩樣
- 大家發現「把模型包好」帶來的效益,可能比「再訓練一個更大的模型」還高
LangChain 團隊就有個經典案例:
固定使用 GPT-5.2-Codex 模型不動,只調整 Harness 三個變數 (system prompt、tools、middleware hooks),就讓 deepagents-cli 在 TerminalBench 2.0 從 52.8% 提升到 66.5% (+13.7 個百分點),名次從 30 名外飆升到第 5 名。最有趣的是他們發現的失敗模式很「人性」 — Agent 寫完 code 自己 review 一下覺得 OK 就停手,所以解法是強迫 Agent 對著原始 spec 驗證,而不是 self-review。詳細參閱 LangChain Blog - Improving Deep Agents with harness engineering
Harness Engineering 就是要嘗試解決類似的問題,而比喻的概念就是像 作業系統,如下圖:
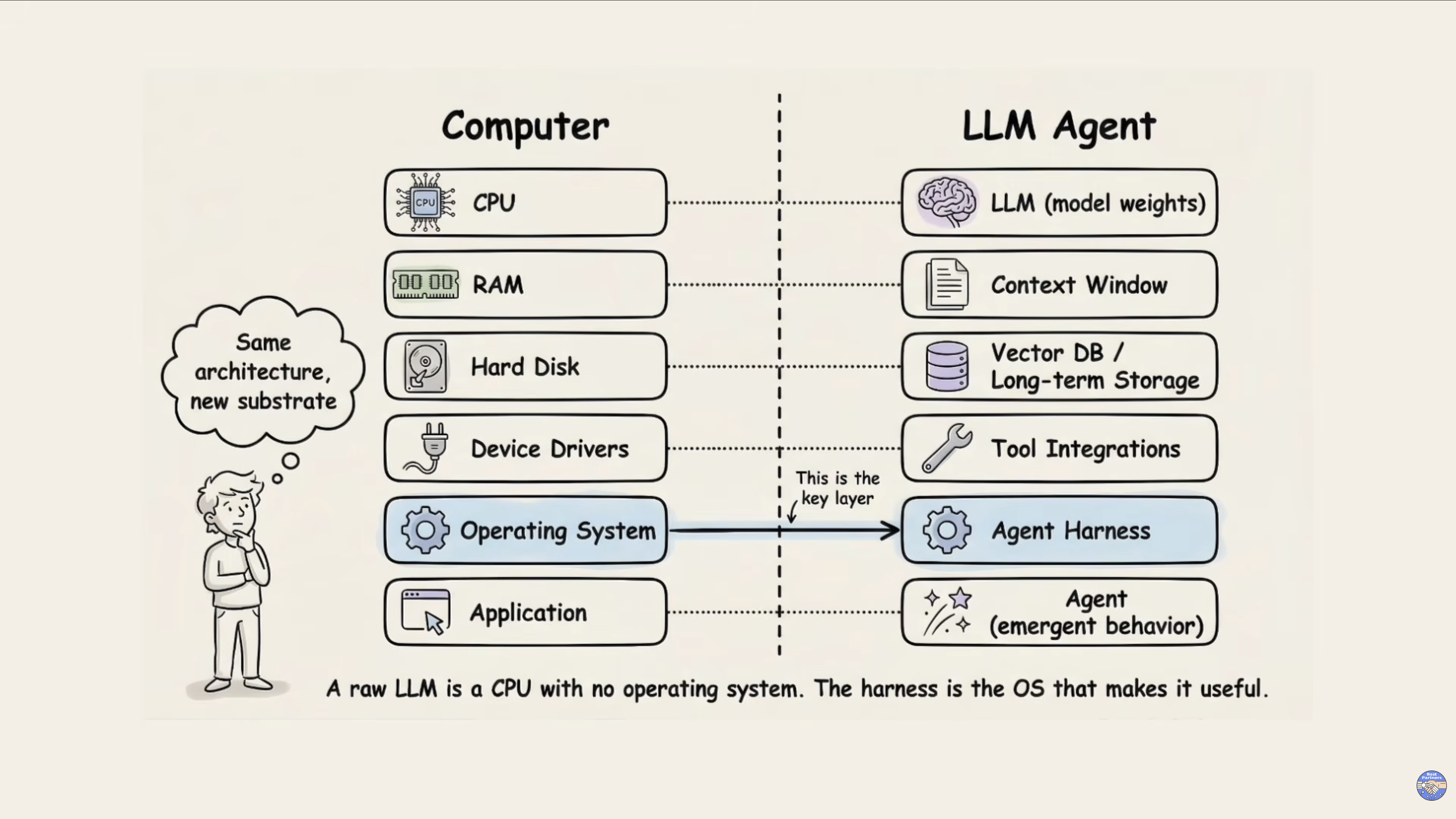
這個「Harness 像作業系統」的比喻其實不只是「資源調度」這麼簡單,作業系統真正的核心價值在於 抽象化與隔離:
把不可靠、無狀態、會幻覺的模型,包裝成一個對外看起來穩定可預測的系統。
回頭看我當年做的 CLI Harness 也是同樣思路:
把待測產品的不確定行為,透過 SSH/Telnet 的標準介面包起來,讓上層測試案例可以穩定執行。
本質上都是在處理 不確定性的封裝 ,而封裝的本質則是 隔離 (Isolation) – 更多參閱 “多租戶架構的核心設計“。
我想了三個問題,來思考 Harness Engineering:
- Harness Engineering 解決的問題是什麼?
- 它如何解決?
- 現在發展過程,出現哪一些使用 Harness Engineering 實作的系統或者服務、或工具?
這三個問題,只要丟到任何一個 AI 或者利用 NotebookLM 就可以整理出很多資料了。
小結
整體看下來,Harness Engineering 還在很早期的階段,現在大家在做的事情,比較像是 1970 年代各家在探索作業系統該長什麼樣子。等到這個領域成熟,可能會出現類似 POSIX 那樣的標準介面,讓不同 Harness 之間可以互通。但在那之前,每個團隊都還在用自己的方式試,這也是這個領域目前最有趣的地方。
我在整理 “自幹作業系統“ 的相關學習筆記時,也剛好在思考,是否要把 POSIX 標準加入,其實也是同樣的過程。寫 OS 的人,學的是「怎麼建立穩定可靠的執行環境」這套思維。而 Harness Engineering 本質上就是把這套思維搬到 LLM 上:
scheduler → 編排循環,memory hierarchy → 分層記憶,process checkpoint → 任務檢查點,syscall → tool calling,IPC → multi-agent 通訊。
所以我 剛好 等於同時在做這兩件事?
一邊在「最底層」用手親自把這些概念刻出來,一邊在「最上層」觀察這些概念怎麼被重新發明來服務 AI。
20260522 補充
這篇文章寫於 2026/04/28,如預測:
- 20260520: Google 發表新的 Model Gemini Flash 3.5, Antigravity 2.0 釋出,一堆工程師崩潰 …
- 20260520: 加碼演出 FB 裁員 8000 人開獎
延伸閱讀
站內文章
- 自幹作業系統 - SimpleOS
- 自幹作業系統 - 初探 Timer 原理
- Designing Test Architecture and Framework
- 聊聊 Harness Engineering
- 從《美麗新世界》看 AI 的發展
- SaaS 關鍵設計 - Multi-Tenancy - 探討真實世界的租賃關係
Comments
About
著作
演講
- 演講錄影 @ Youtube
- 探索職涯、複利人生 - AWS Career Exploration Day 2023
- 個人著作 SRE 書友見面會
- 軟體測試實務 - 新書發表會
- 探索職涯、成就未來 - AWS Career Exploration Day 2022
- 從理想、到現實的距離,開啟品味軟體測試之路
- 91APP 在 AWS 上的 SRE 實踐之路
- 在矩陣型組織裡,如何有效管理 AWS 的成本結構與系統架構
- 災難演練 @ AWS 實戰分享
- 導讀持續交付 2.0 - 談當代軟體交付之虛實融合
- 聊聊軟體交付的濫觴 談產出物管理
- 從緊急事件 談 SRE 應變能力的培養
- 邁向 API 經濟 - API Gateway 導入之旅
- Monitoring Tools 大亂鬥 - AWS CloudWatch
- Ops as Code using Serverless
- 淺談系統監控與 CloudWatch 的應用
AWS Certifications


