最近因為武漢肺炎事件,國家必須用各種方式通報國民,包含嚴重性、通報的方法、交付有意義的資訊。
這整個過程就是事件管理是一樣的。摘錄我在 2017 年分享的一段想法:淺談系統監控與 CloudWatch 的應用,其中第四部分談的異常通報 就是談事件通報與管理的核心概念。
Updated 2023/07/19: 本文部分收錄在個人著作 《SRE 實踐與開發平台指南》 - 2023/08 上市
最近因為武漢肺炎事件,國家必須用各種方式通報國民,包含嚴重性、通報的方法、交付有意義的資訊。
這整個過程就是事件管理是一樣的。摘錄我在 2017 年分享的一段想法:淺談系統監控與 CloudWatch 的應用,其中第四部分談的異常通報 就是談事件通報與管理的核心概念。
Updated 2023/07/19: 本文部分收錄在個人著作 《SRE 實踐與開發平台指南》 - 2023/08 上市
整理我認識的計算機科學家。
在組織裡推動事情,最困難的往往不是技術上的執行問題、不是成本問題、溝通問題、協作問題,困難的是:
如何讓高層、主管、團隊成員
意識 (Awareness)到:這是一個必須被正視的問題。
當問題被正視了,大家都 Awareness 了,接下來才有開始討論如何解決、如何 有效定義目標與執行、落地、資源才會進來 …
SRE 讀書會 Round 3 從今年 2019/03/15 開始,在 2019/12/05 (四) 的寒流之下完結了,大家頂著 15 度低溫、加上下著雨,依舊準時出席讀書會,走完這次最後的章節。
今年一整年,起了好幾個跨部門、跨組織的任務,在這過程一直在嘗試讓一個成員、或者讓一個團隊可以自主完成任務的方法,過程中踩了很多雷,像七傷拳一樣,常常是還沒發拳自己就先中了內傷,內力不夠深厚打七傷拳才會傷到自己,後來慢慢梳理出一套可以執行的方法,年底也看到成果了。
除了這些大範圍的協作,工作上經常交付任務給團隊執行,交辦的方式會是口頭交辦、公開的指派、正式的賦予權責,交辦的對象則有自己團隊的資深、到資遣成員,協作團隊的成員 … 不管怎樣的交付任務,都需要一個有效的方法來確立目標是可以執行。
這篇整理了一些歷程與土炮方法,分成以下幾個部分:
CloudFront 是 AWS 非常重要的服務,用了幾年,斷斷續續有一些心得與想法,這次換個方式整理筆記,先全部用 Q and A 方式記錄學習。
本文整理的 Delivery Method 以 Web 為主
最近有朋友問我一些測試的問題,問題層面很廣,像是去一家新創 Startup 如何 Build Up QA Team?自動化測試該用哪一套?測試的方法論該怎麼落地?聊到後來我發現問題背後的期待有問題,期待是什麼?
測試想要一步到位
基於這個前提,後來我把觀察到的現象與問題寫下,起筆是 2018/07/03 的隨筆,在不同時間陸陸續續整理以下文章:
這篇文章整理上述文章的想法與整合。
本文的思路,後來整理成專文: 如何意識到問題的存在
20230523 更新:本文內容部分收錄在 共同著作《軟體測試實務》 第一冊 第一章之中,歡迎大家彭場指導。
這幾年工作關係,經常讀一些資料,但有幾篇是經常重複閱讀、重複分享,這幾篇文字影響我很多,整理起來需要分享時比較快 XD
所有文章標題都是原文連結。
整理 EKS 的 Networking 相關的問題,主要有規劃、管理 … 等觀測,如下:
這段個別剪接出來的三分鐘錄影,是今年 (2019) 四月我在新竹敏捷 (交大) 分享的,我稱為 軟體交付的三體問題。
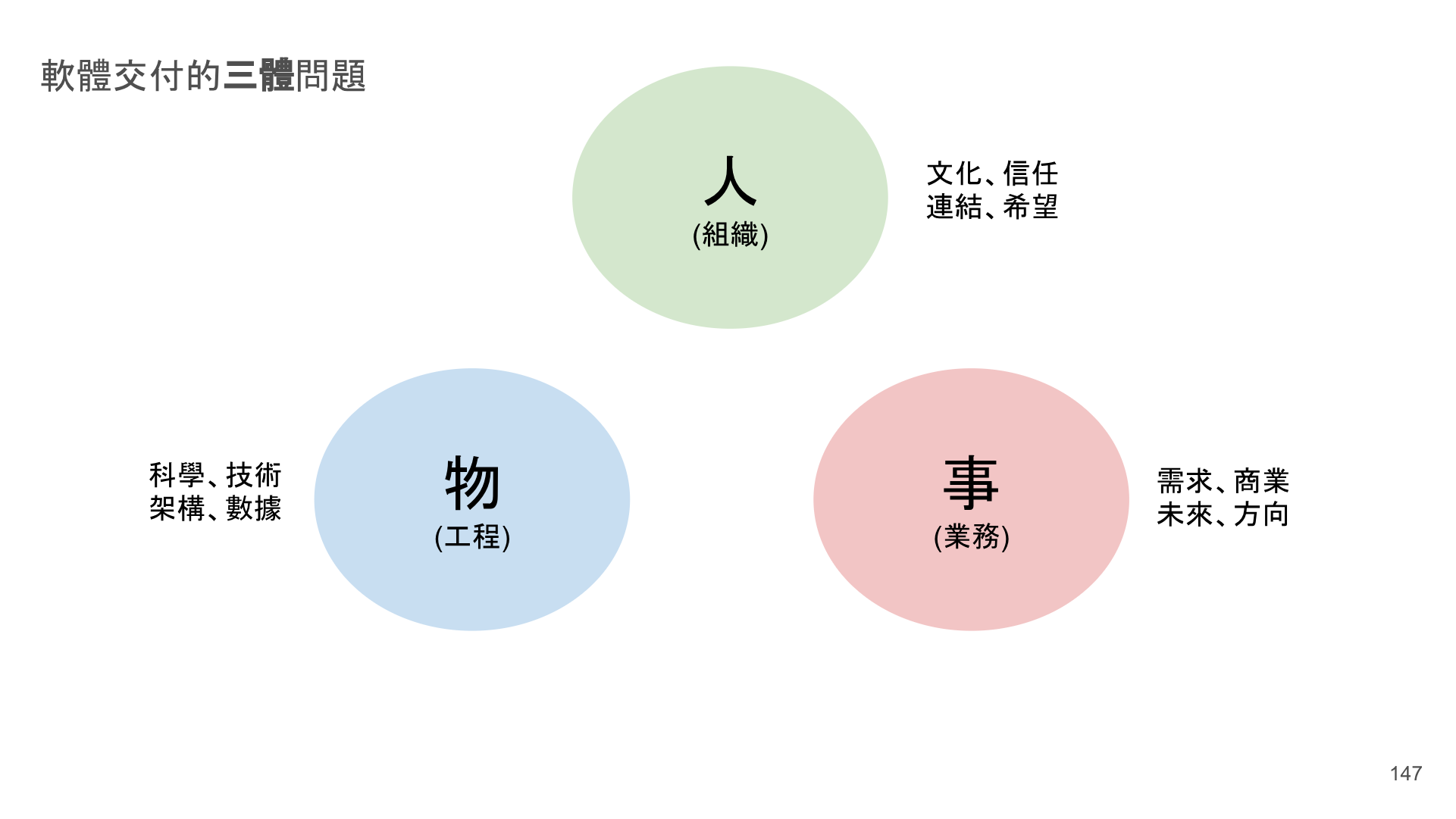
Updated 2023/07/19: 本文收錄在個人著作 《SRE 實踐與開發平台指南》 - 2023/08 上市
整理相關 EKS 的學習筆記,包含規劃 (Planning)、建置 (Provisioning)、管理 (Management / Operation) 等。
上一篇 整理了使用 kubeadm 安裝 K8s Cluster / Worker Nodes / CNI … 等,同樣的,本文整理使用 AWS EKS 安裝 K8s v1.14 的筆記,安裝過程則以 AWS CLI 為主,同樣方式也可以使用 eksctl、AWS Console、CloudFormation 執行。
如同之前提及,雖然 EKS 是 Managed Service,但是實際上只有針對 Master Nodes,而 Worker Nodes 還是需要自行管理以及維護的,另外針對 Ingress、使用者權限、Log 蒐集、資源監控、網路 (CNI 相關) … 等,還是需要額外規劃。
筆記內容:
這也是個朋友問的問題,問題截圖如下:

先不管誰有沒有穿褲子,從整體來看,重新整理問題:
系統發生異常時,第一時間如何快速止血?
底下整理我經常在處理分析時的思路。
Updated 2023/07/19: 本文收錄在個人著作 《SRE 實踐與開發平台指南》 - 2023/08 上市
淺談效能測試 整理了關於 Capacity、Reliabilty、Stability 的概念與定義。本文針對如何量測 系統容量 (Capacity),整理怎麼做的方法論,可以當作 Capacity Plan Guideline。
系統容量是透過
量測 (Measure)出來的,結果是數據統計的報表,而測試的結果通常是 pass or fail,故本文的描述不用測試這個動詞。
這篇文章整理的是如何執行的概念,但不包含以下:
20230523 更新: 本文全文收錄在 共同著作《軟體測試實務》 第二冊 第一章之中,歡迎大家彭場指導。
CloudWatch Agent (底下簡稱 CWA) 是 awslogs 的後續版本,提供了更強大的功能與整合能力。整理 CWA 的基本概念、如何安裝與配置、以及常見問題。
本文範例為
地端 (On-Premise)Linux (Ubuntu 16.04) 為例。
幾段隨筆,談 IoC / DI 與管理的想法。
以下這張照片是 Jan, 2015 在 AWS Virginia Data Center 火災的照片:

圖片來源: Amazon data center on fire in Virginia - CNN
其實災難,不管是個人還是在企業,隨時隨地都有可能發生。當企業成長到一定的規模,災難還原計畫,就越來越重要。但是做災難還原準備工作,本身在公司裡面不是所謂的 產出 任務,他屬於 備援 計畫,而且災難復原在傳統的 IT 架構裡,所需要的預算、人力、資源、時間是相當龐大的,大部份的老闆,對於這件事情是不會支持,或者也不太願意投資的。最多做所謂的 異地備援 就算是很不錯的了。
以下整理 Whitepaper - Using AWS for Disaster Recovery (Oct, 2014) 內容。大部份的圖檔都是文件裡擷取出來。
整理 Linux 效能工具 top 的一些資訊,範例是在 ubuntu 16.04, AWS EC2 c5.large 上的資訊。
簡譯這篇精彩的分享:Scaling Infrastructure Engineering at Slack
才 2.5y ,就可以把整個 Infrastructure Engineering 弄成這樣的規模。她提到的有很多情境,架構、招募、組織 … 很有感 … XD
要聽她說 (她有點激動 XD) 。。。
Using API Gateway as DynamoDB Proxy 一文提及可以透過 API Gateway 直接整合 DynamoDB ,而不一定要透過 Lambda,其實 Lambda 只是大家最常整合的服務而已。同樣的概念,其實 API Gateway 可以直接整合除了 Lambda 之外的很多服務,像是 DynamoDB、SQS、Step Functions、Kinesis、 … 等。
延伸這個應用,我很常被問的一個問題:
發送給 API Gateway 的請求,會不會掉?怎樣避免 Request 遺失?
這個問題很多人都問過我,本文提供一個架構設計的想法。
這篇的想法是埋藏在心裡很久的,因為工作關係、身份關係,常常需要被灌輸一些觀念,但是每次聽到哪些『說法』怎麼聽,都是覺的怪。
管理工作經常需要量化產能,量化產能經常的會拿工廠生產線來比喻,最後就把軟體開發的管理度量,用生產線的思維來比喻,然後就把軟體開發者、軟體工程師當作產線作業員來管理,荒謬至極的想法。
以下是我下班坐公車時,寫下積累、醞釀的 隨筆 (2019/07/09)。
管理工作範圍廣大,人事管理 (People Management) 是其中一個重要的工作範圍,本文整理身為一個管理者必須面對的課題:資遣、解僱、辭呈。
2018/10/21 GitHub 發生重大的異常,服務中斷超過 24h。事後官方釋出完整的事件分析報告,包含非常詳盡的事件過程、架構、應變等。這篇是我當時整理在 SRE 社群的簡譯,原始連結。
如同電影 薩利機長,SRE 應該要多閱讀 異常事件報告,從中學習應變的方法與經驗,同時也了解別人的 系統架構 為何如此設計,有什麼問題?
這個事件,讓 Github 整個組織認真思考 Site Reliability Engineering 的重要性。
整理如何設定 AWS SSO 的流程,主要參考: How to Set Up Federated Single Sign-On to AWS Using Google Apps 這篇文章,用 SAML 2.0 (Security Assertion Markup Language) 協議做使用者的 認證管理 (Authentication),並且延伸管理上實際遇到的問題。
議題追蹤 (Issue) 最重要的就是資料來源的管理,讓需要被關注的事情都放到同一個籃子 (Pool),然後才得以檢傷、分類、處理。而 SaaS 年代,如何讓使用者的聲音,快速的被蒐集與處理,則是非常重要的。
本文整理如何設定讓 Email 訊息,自動導入 Redmine,變成可以追蹤管理的設定方式。
Step Functions 在 2016 re:Invent 發佈後我就一直放在心裡,他是令人興奮的功能。本文整理 Step Functions 的學習筆記。
去年翻譯了這本書: 分散式系統設計 (Designing Distributed Systems, DDS) 在 2019/05/20 上市了。以下純粹是譯者自己的筆記與心得,非官方。

Redmine 的安裝流程相對於一般的網站應用程式來講,是複雜的,特別是如果不熟悉 Ruby on Rails 的生態系,或者不熟悉 Nginx 的配置,那麼整個安裝過程會是非常挫折的。
本文記錄如何在 Ubuntu 16.04 安裝與配置最新版 Redmine 4.0.3 (201905) 筆記,相關資訊放在 GitHub 供參考。