GitHub Post-Incident Analysis
2018/10/21 GitHub 發生重大的異常,服務中斷超過 24h。事後官方釋出完整的事件分析報告,包含非常詳盡的事件過程、架構、應變等。這篇是我當時整理在 SRE 社群的簡譯,原始連結。
如同電影 薩利機長,SRE 應該要多閱讀 異常事件報告,從中學習應變的方法與經驗,同時也了解別人的 系統架構 為何如此設計,有什麼問題?
這個事件,讓 Github 整個組織認真思考 Site Reliability Engineering 的重要性。
背景摘要
主要是例行性維運,網路短暫中斷,造成資料庫同步問題,產生一連串事件。其中最久的還是怎麼還原資料,不同資料中心資料同步以及同步過程要處理的問題。中間有遇到服務降級 (degrade)、網站反應變慢 (資料抄寫未完成)、非同步作業等問題 … 。
官方提供的網路架構圖:

正常的網路拓墣:

事件時間軸
時間軸的摘要如下 (文長,沒照翻 …):
10/21 22:52 UTC: DB 從美東 failover 到美西
更換 100G 光纖設備的常規維護工作,導致 US East 海岸網路接口與 US East 資料中心短暫中斷 43 秒。這中斷的過程,原本在 US East 負責 Master DB 無法將資料同步到 US West 的資料中心。此時負責 管理 MySQL Cluster 的機制 (Orchestrator) 自動處理 failover,重導網路流量到 US West,也就是 Master 原本在 US East 改為 US West 資料中心。
Orchestrator 是 MySQL HA and Replication 的管理服務,他使用 Raft 一致演算法實作分區容錯與共識機制。
10/21 22:54 UTC (事件後兩分鐘): 定位事故肇因
內部監控系統監控到數個異常訊息,發出內部 Alert ,好幾位工程師進入處理狀態。23:02 (事件後 10 分鐘) 確認是 資料庫叢集的拓墣問題。
10/21 23:07 UTC (事件後 15 分): 定義事件等級
Responding Team 決定手動暫停 (Lock) 所有部署程序,避免額外的問題。23:09 (事件後 17 分) Responding Team 把網站狀態燈調整成黃燈,三分後 (23:11) 事故協調小組 加入,兩分鐘後決定調整狀態為紅燈。
10/21 23:13 UTC (事件後 21 分): 恢復資料庫配置,確認資料差異
確認問題原因,Database Engineering Team 進來,主要研究有哪一些配置需要手動調整,讓 US East Database 重新配置成 Master ,同時要把 Cluster 的 Slave 從 US West 抄完,這段時間 US West 已經寫入 40 分鐘的資料了。此外,已經有一些資料寫入 US East ,但還沒被寫回 US West,這同時還要避免又從 US West 重新寫回 US East … (好亂啊 orz …)

10/21 23:19 UTC (事件後 27 分): 提高資料完整性、系統降級
確認有一些 DB 查詢動作,像是 Push 要先暫停,研究過後決定執行部分的降級 (degrade),包含了 webhook delivery、GitHub Page Build。選擇的策略就是以資料完整性高於功能的易用性。
10/22 00:05 UTC (事件後 01h13m): 解決資料不一致計畫,資料庫還原
在 Incident Response Team 裡的工程師們,開始規劃 解決資料不一致 以及 MySQL failover 的實踐。計畫是從備份還原資料、同步在兩個資料中心的副本資料、回到正常服務的資料庫拓墣架構、還原暫停在 Queue 裡的排程任務。這時候對外公告上述的 計畫
MySQL 每四個小時備份一次,這樣的資料存在公有雲好幾年了(沒寫哪朵雲)。資料回復的量有好幾個 TB,也就要花好幾個小時。主要的時間都花費在資料傳輸,做資料完整的檢查 (checksum, prepare, load, test …)。在這意外之前,我們從不需要重蓋整個資料庫叢集,和回覆整個資料。

10/22 00:41 UTC (事件後 01h49m): 開始執行還原
還原程序開始執行,工程師監控執行程序。其他團隊開始研究如何加速還原。
共花了六小時還原!
10/22 06:51 UTC (事件後 07h59m): 提升系統讀取效能
US East 資料中心,好幾座資料庫叢集已經還原,然後開始從 US West 抄寫新資料回來。這會導致頁面讀取資料非常的慢,因為如果讀取新的資料 (US East 還沒有),那麼就要先等資料從 US West 寫回來之後,但這段資料傳輸是跨美西到美東的網路。
這時候團隊發現可以直接從 US West 資料中心還原資料,不會被下載的速度限制。同時可以利用 Replication 抄寫機制,這時候在 Twitter 對外公告還要兩小時 (如下圖) 完成。

10/22 07:46 UTC (事件後 08h54m): 對外公告
在 GitHub Blog 發佈一篇 異常公告訊息 (如下圖),說明異常原因是因為網路區段異常,造成資料不一致現象。為了確保資料完整性,暫停了部分功能和內部發佈程序。

10/22 11:12 UTC (事件後 12h20m): 處理資料不一致
Master 資料庫已經切回 US East,讓網站的響應速度變快,但是因為有部分的副本 (Slave) 還是落後幾個小時的資料,這個延遲造成使用者發現資料不一致。實際上副本寫入是非線性的,所以將讀取的請求分散到各個副本,讓資料慢慢一致。
寫入的負載程度會開始在歐洲和美洲的上班時間,所以還原花費的時間會比原本預估的還要長
10/22 13:15 UTC (事件後 14h23m): 尖峰時間,增加複本
這是 Github.com 流量尖峰,網站的回應速度變慢。事件回應小組針對這個狀況持續討論。事件之前已經決定在 US East 公有雲上增加副本。只要這些機器就緒,就可以提供更多服務。
10/22 16:24 UTC (事件後 17h32m): 資料持續複製中
一但複本同步完成,將執行故障移轉回到原本的拓墣架構,解決延遲和可用性問題。當我們還在處理這些資料的時候,覺得資料完整性優先,所以保持服務為紅燈。
10/22 16:45 UTC (事件後 17h53m): 系統效能恢復,關閉降級,開始執行非同步作業。
到這個時間,已經完成恢復,提升回應,服務幾乎 100% 恢復。但是還有五百萬的 hook 事件、八萬的 Page 建置在 Queue 裡。開始處理這些資料,約有 20 萬的 webhook 因為 TTL 過期了,所以我們找出了這些 event,條整 TTL 重新執行。
為了避免這個問題,未來會先進入 degrated 狀態,確認服務恢復了,在開始啟動這些 event 處理的程序,確保系統效能不被影響。
10/22 23:03 UTC (事件後 01d01h11m): 確認系統狀態,改變燈號。
所有暫停的 webhook 和 Page Build 已經處理完了,所有系統狀態確認正常運作。切換裝態為綠燈。
想法
扁鵲三兄弟的故事
扁鵲是中國古代歷史上非常著名的故事,這個故事最早出於《鶡冠子·卷下·世賢第十六》中卓襄王與龐暖的問答。原文如下:
煖曰:「王獨不聞魏文王之問扁鵲耶?曰:『子昆弟三人,其孰最善為醫?』扁鵲曰:『長兄最善,中兄次之,扁鵲最為下。』魏文侯曰:『可得聞耶?』扁鵲曰:『長兄於病視神,未有形而除之,故名不出於家。中兄治病,其在毫毛,故名不出於閭。若扁鵲者,鑱血脈,投毒藥,副肌膚間,而名出聞於諸侯。」魏文侯曰:「善。」使管子行醫術以扁鵲之道。 此借扁鵲區別醫術高下喻治國方略之高下,未入《史記•扁鵲列傳》。魏文王,即魏文侯,前445——前396年在位。
底下翻譯是網路上找到的:
魏文王問名醫扁鵲說:「你們家兄弟三人,都精於醫術,到底哪一位最好呢?」
扁鵲答:「長兄最好,中兄次之,我最差。」
文王再問:「那麼為什麼你最出名呢?」
扁鵲答:因為 長兄治病於發作之前,中兄治病於情嚴重之時,我是治病於病情嚴重之時。
長兄治病,是治病於病情發作之前。由於一般人不知道他事先能剷除病因,所以他的名氣無法傳出去
中兄治病,是治病於病情初起時。一般人以為他只能治輕微的小病,所以他的名氣只及本鄉里。
而我是治病於病情嚴重之時。一般人都看到我在經脈上穿針管放血、在皮膚上敷藥等大手術,所以以為我的醫術高明,名氣因此響遍全國。
其實事後控制,不如事中控制,事中控制不如事前控制 !
預防勝於治療
每次異常、每次事件(通常是行銷活動、部署),都是一次學習,而每次學習應該都是前、中、後的紀錄:
- 閱讀別人的異常事件報告可以學到一些
- 寫事件報告會學到很多多
- 處理異常事件會學到超多(但也超痛)
但不管怎樣,異常事件是一個 SRE 必須坦然面對的工作。
沒有經驗的新手 SRE 可以藉由閱讀事件報告,學習如何面對、吸收前輩的經驗。已經在線上的 SRE 藉由每次整理報告的過程,重新梳理自己的思緒、系統架構、事件處理方法,從回顧中學習,找到改善的方法與策略。團隊透過討論報告內容,分享處理經驗一起成長。
電影 薩利機長 ,劇情中機長提到自己私下開一家公司,就是專門研究各種飛機失事案例,從案例中找出如何改善飛安,協助降低飛安事件。
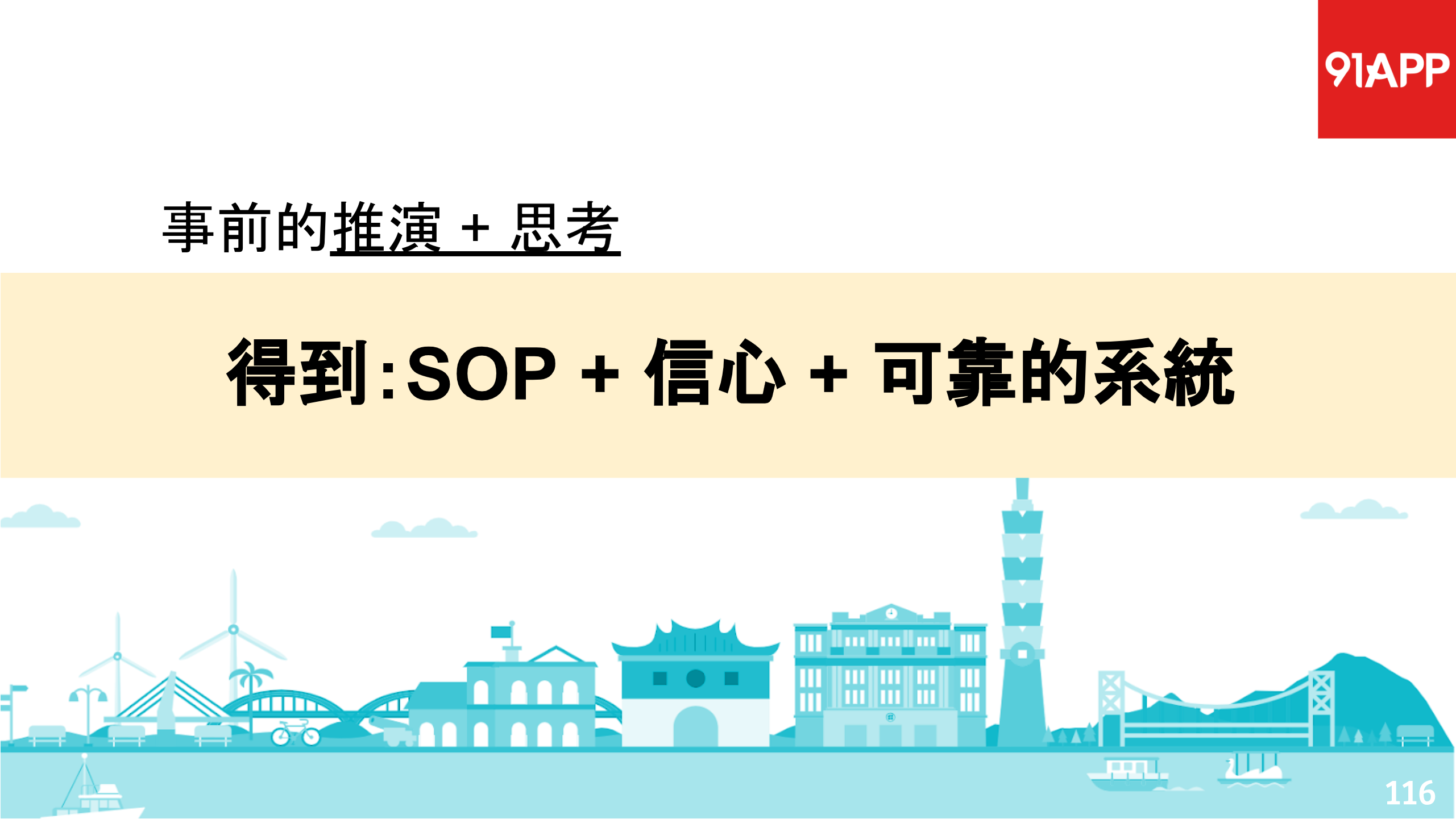
去年在 DevOpsDays 的 演講:從緊急事件 談 SRE 應變能力的培養 有分享很多這樣的想法,主要核心概念就是:
- 預防勝於治療
- 千金難買早知道,早知道,值千金。
以下是當時簡報的結論:


相關文章 (站內)
SRE 相關
參考資料
Comments
About
著作
演講
- 演講錄影 @ Youtube
- 探索職涯、複利人生 - AWS Career Exploration Day 2023
- 個人著作 SRE 書友見面會
- 軟體測試實務 - 新書發表會
- 探索職涯、成就未來 - AWS Career Exploration Day 2022
- 從理想、到現實的距離,開啟品味軟體測試之路
- 91APP 在 AWS 上的 SRE 實踐之路
- 在矩陣型組織裡,如何有效管理 AWS 的成本結構與系統架構
- 災難演練 @ AWS 實戰分享
- 導讀持續交付 2.0 - 談當代軟體交付之虛實融合
- 聊聊軟體交付的濫觴 談產出物管理
- 從緊急事件 談 SRE 應變能力的培養
- 邁向 API 經濟 - API Gateway 導入之旅
- Monitoring Tools 大亂鬥 - AWS CloudWatch
- Ops as Code using Serverless
- 淺談系統監控與 CloudWatch 的應用
AWS Certifications


