Identifier Design Consideration
整理一些設計 Identifier 要考慮的事情,特別是要揭露給使用者的時候,像是 RESTful API 的設計。原文來自 facebook 寫的草稿。
Consideration
用途
Identifier (經常縮寫成 Id or ID),本質就是 識別,用來找到特定的資源 / 物件,在系統中具備 唯一性 (Unique)。
生活中常見的例子:
- 身分證字號:用於識別個人身份,是各國政府機構核發的獨特識別碼。
- 產品編號:用於識別產品,通常由製造商分配,有助於追蹤產品的製造和銷售情況。
- 網域名稱 (DNS): 用於識別網路上的各種資源,例如網站、郵件伺服器等。
- IP Address:用於識別網路上的設備,是通訊協定中的一個重要元素。
- 手機 IMEI 碼:用於識別手機設備,有助於防止偷竊和盜版。
- 電商的訂單:訂單編號、取貨號碼
適用範圍 (Scope)
前面一段舉例很多例子,但實際上 Id 都有適用範圍。
身分證字號:適用範圍是國家之內,如果是護照號碼,範圍就是全球。產品編號:適用範圍就是生產公司的範圍。IP Address:以 IPv4 而言,本身就有區分 保留 (Private | Broadcast) / 公有 (Public) … 等,Public 就是全球範圍網域 (WAN)、私有就是私有網域 (LAN) …登入帳號:App 登入的帳號本身則是看使用 SSO 還是 Local,就可以區分範圍。
用 EC2 Instance Id 當例子,EC2 InstanceId 的設計是為了 可程式化 (Programmable),具備全局的唯一性 (Global Unique)。也就是每個 InstanceId,不管是在哪一個 AWS Region or Zone、或者跨 AWS Account,都是唯一的 Id,而且不可重複使用。詳細參閱 Instance ID uniqueness
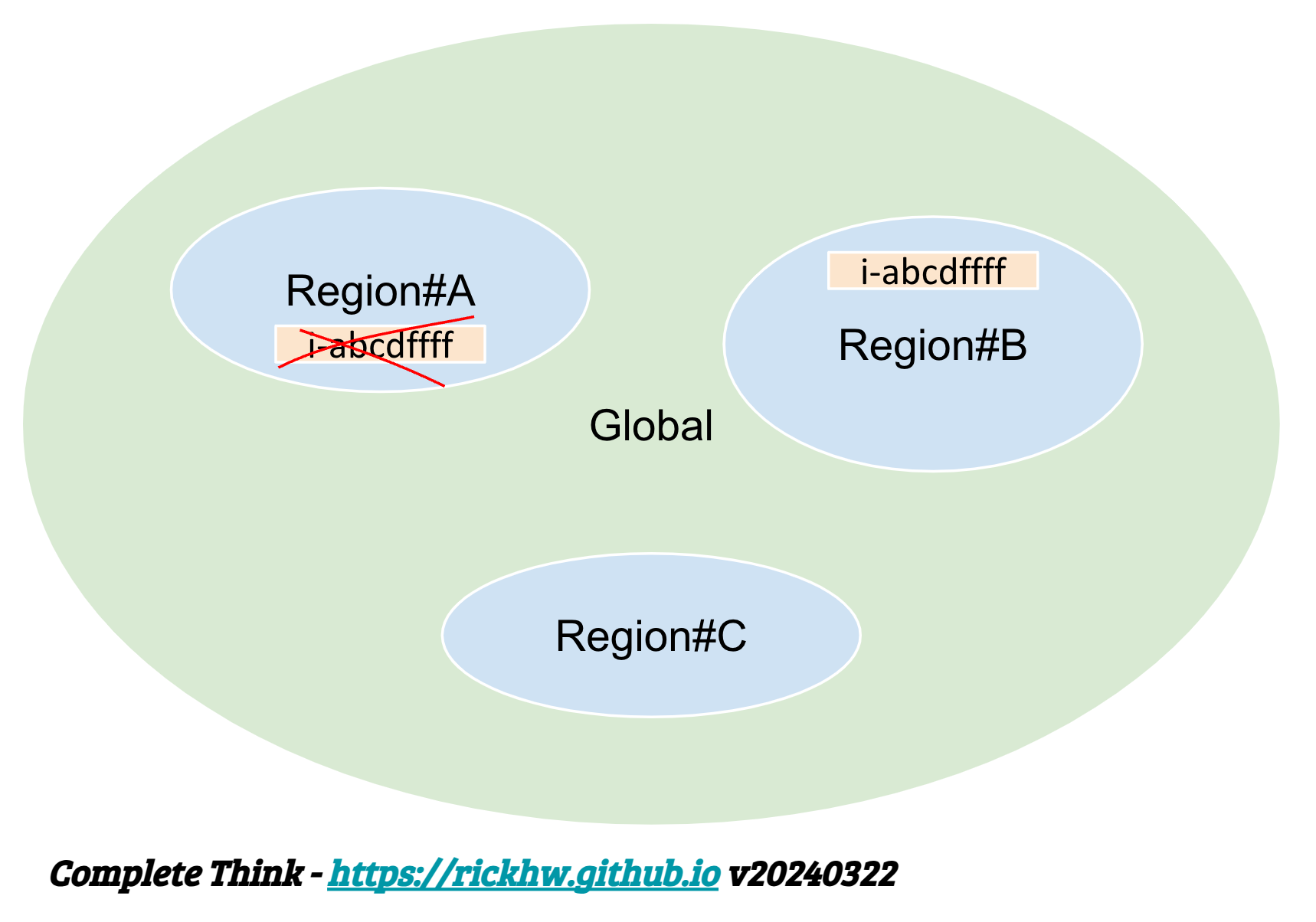
程式語言裡的變數可以當作一種 id,範圍有 global variable or local variable。當名稱衝突的時候,依照程式語言的設計,可能會有不同層度的錯誤或者警告。
1 | name = "rick" |
縮小範圍
電商為例,訂單編號本身是個全域變數,是電商系統的在看的,不管有怎麼好的設計、編碼規則,單一個編號通常會很長。
設計時要讓使用者可以快速定位,基本的做法就是改變範圍,所以現在很常用的縮小範圍就是:
區域範圍:一家超商能放的商品數量多則上百件、少則數十件反向檢索:透過使用者的手機末幾碼,反向索引編號。因為訂單編號是電商系統產生的,本質上跟使用者示弱關聯,取貨的是使用者,用一個弱關聯的號碼讓使用者取貨,是不好的使用體驗。所以反向的用使用者的電話號碼或者身分證末幾碼,可以達到同樣效果,同時可以快速過濾。
可數 與 不可數
這概念跟英文的 可數 / 不可數、數學上的 窮舉法 (Proof by exhaustion)、程式語言的 迴圈 (for)、white / iterate (迭代器) … 等概念是一樣的。
Id 的數量會很多,通常會歸類成不可數,像是:
- 每隻手機
IMEI碼:代表這只手機的唯一性與合法性。但手機的數量很多,基本上發展到現在已經數量多到不知道怎麼數了 …- 可以透過
*#06#查到
- 可以透過
- 電腦網卡的位址 (Mac Address)
- 全球的網頁數
- 地球的沙子
可數的 Id 相對於不可數的是比較少,數量級大概會少於 100 以內,比較多的會是 1000 以內,不管怎樣,會 有明確上限,可以 正面表列、列舉清單 。像是:
- 台灣郵遞區號
- 國際電話號碼的前幾碼
- AWS region 代號
可討論:
- 電腦的編碼系統 (Unicode) 嚴格講是個可數系統,因為字元 (character) 會直接正面表列被定義,像是英數字的數量、雙位元語系數量 (中日韓)、後來定義的 emoji 等符號。不過 Unicode 的數量很大,版本 15.1 共定義了
149,813個字元。
設計系統的時候,要稍微思考一下,這個東西的數量級是可數 or 不可數。
可數有點像是 寵物 ,不可數像是 畜生 來想,更多參閱 Cattle vs Pets | DevOps Explained
格式
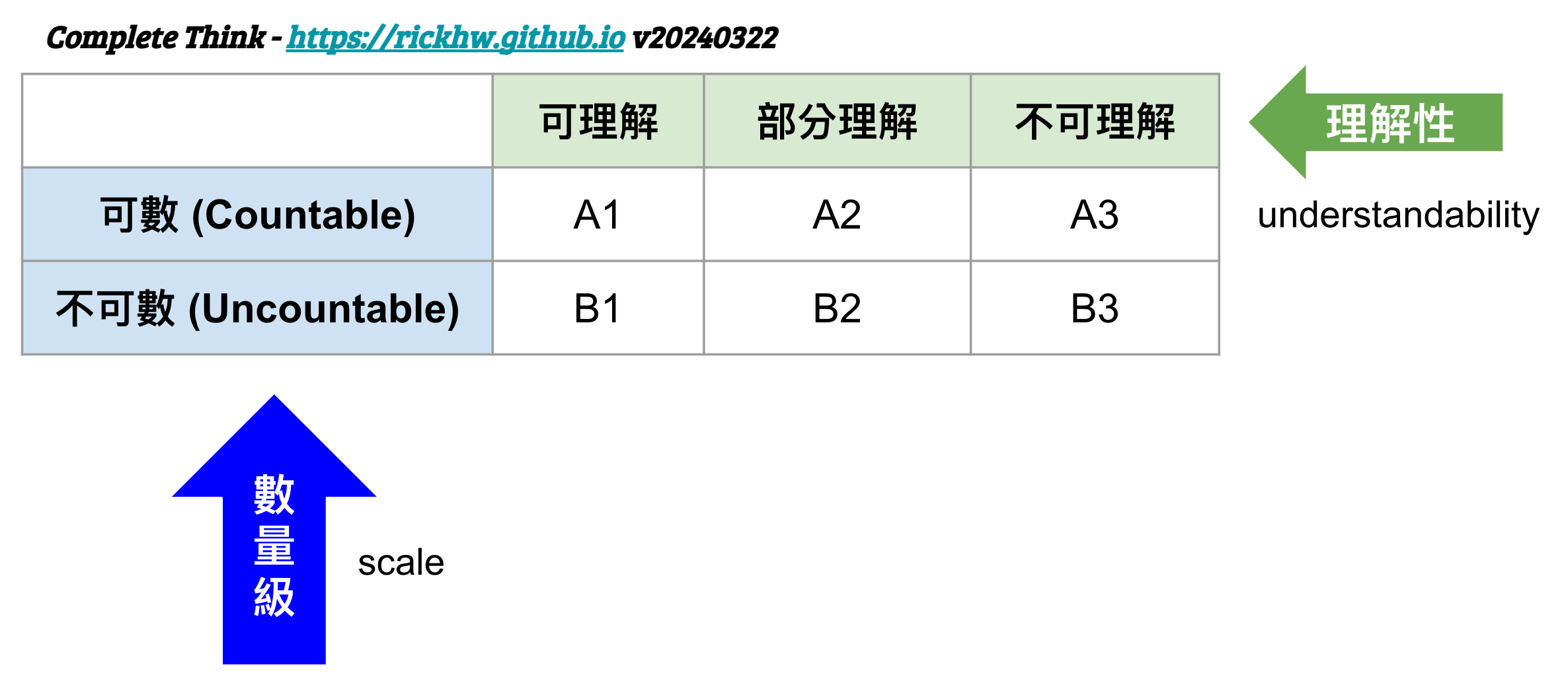
設計 Id 最多人討論的是格式 (Format / Pattern),格式要考慮的有幾點:
數量級 (scale):可數 (countable)、不可數 (uncountable)理解性 (understandability):可理解、部分理解、完全不可理解
這樣的設計角度,會有以下六種排列組合的設計思路:
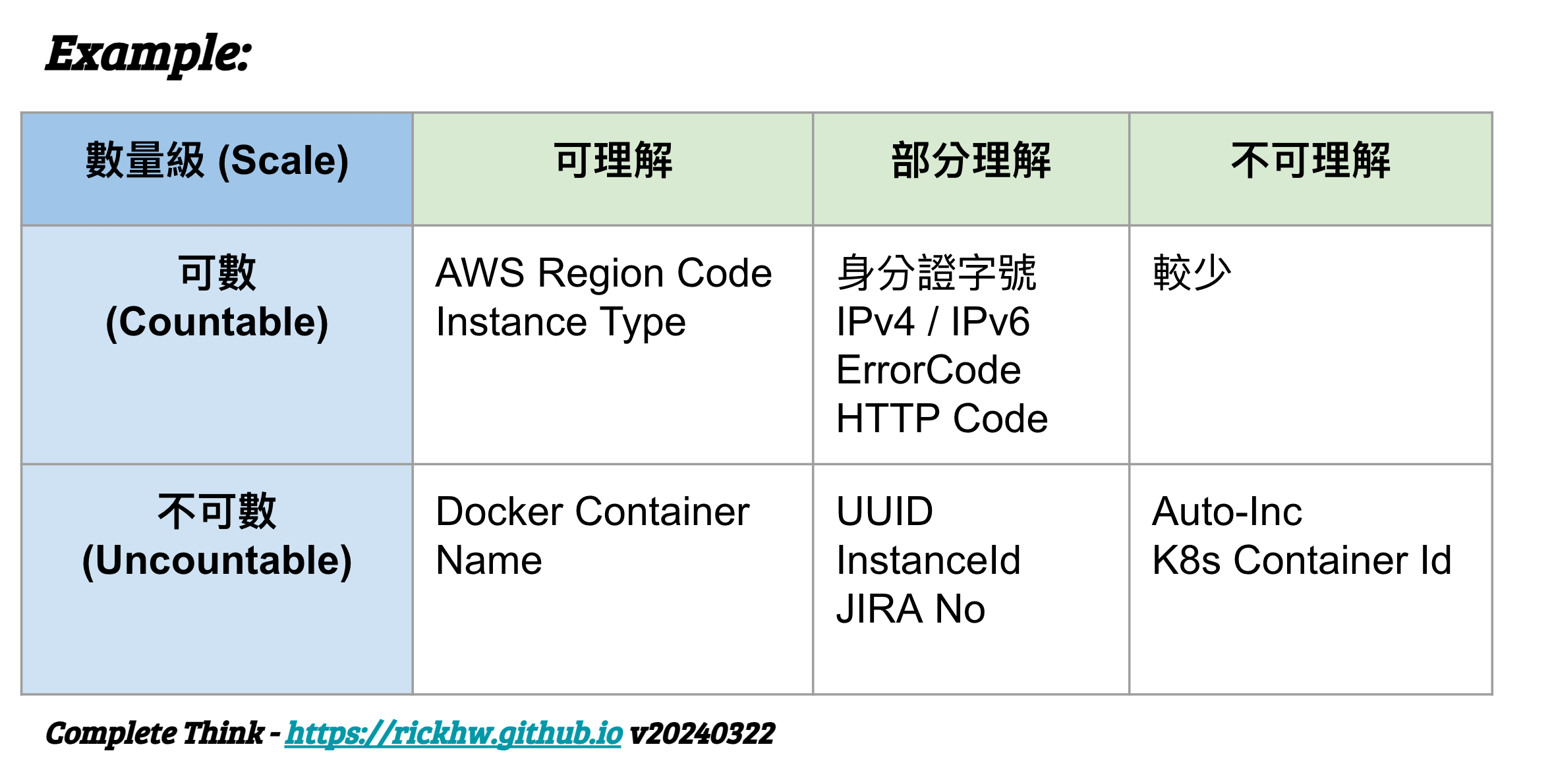
A1 可數 + 可讀性
可數 代表數量極有限,數量 <= 100 or 1000,通常會搭配 可讀性設計原則,也就是定義一個命名規則,讓我們使用上可以一目瞭然。
幾個來自 AWS 的經典例子:
region code: ap-northeast-1, us-east-1, us-west-2 … etc,詳細參閱 Regions and ZonesEC2 Instance Type: t2.small, c5.large, r5.xlarge … etc,詳細參閱 Instance typesSecurity Group Name: 允許使用者輸入一段自己定義的名稱,官方文件說明,命名規則可以參閱我的設計:Plan and Design Multiple VPCs in Different Regions
這類通常在程式語言或者 API,都會直接用 enum 的方式列舉。
A2: 可數 + 部分理解
可數 可以搭配固定理解的組合,像是:
- 系統 Log 的 ErrorCode:
E10-03這樣代表一個錯誤訊息, 有個編碼[IEW][0-1]{2}-[0-1]{2}這樣的規則…. - 台灣身分證字號:規則可以參閱 如何寫程式處理中華民國的身份證字號?, Rust 實作
HTTP Status Code:5XX, 4XX … 等,可數、有明確上限
A3: 可數 + 完全不可理解
可數 + 完全不可理解 這個組合比較少用,我會用在資訊敏感的,卻要對外直接揭露的,像是企業內部對外 egress 的節點。
實際上有些公司對外的 egress 可能是不可數的 XDD
B1: 不可數 + 可讀性
不可數 + 可讀性:這個設計沒啥意義,但是工程師喜歡挑戰這種東西,像是 …. docker container 的 random name …
B2: 不可數 + 部分理解
不可數 + 部分理解,這其實跟 可數 + 部分理解 是類似的概念。
最經典的例子是 UUID 的設計,基本上就是懶人設計。
另外一個很常見的應用案例,AWS 的 resourceId (insanceId, vpc id, ebs id … etc) 都是這種設計.
著名的專案管理系統 JIRA 的 Issue number 可以前綴專案代號,也是一樣的概念。
B3 不可數 + 不可理解
不可數 + 完全不可理解,不知道 UUID 結構的會把它擺這裡。。。基本上這個設計大概就是個只想要一個唯一就好的設計,內容是啥完全不想管。。。像是 MySQL 常用的 auto-increment。
上述六種排列組合,整理常見範例如下表:
實作與 API 設計
可數的 Id 通常在程式語言或者 API 參數,都會直接用 enum 的方式列舉,也就是透過列表方式呈現給使用者查詢。
不可數的 Id 則轉化成 API 讓使用者自行查詢。
常見問題
Q: Id 碰撞
通常是使用不適當的屬性作為 Id,像是電腦的 hostname 當作唯一個識別,這個例子在 Windows 體系的 Active Directory (AD) 很常見。
解法的邏輯就是透過 限縮範圍、亂數命名,降低碰撞。
- 透過子網域的方式
- 透過亂數命名 hostname,但是用 attribute 標記 部門、組織、專案屬性
Q: 數量太龐大,難以使用
資源的數量太多,造成 Id 長度很大,使用時需要提供完整 Id 資訊,才能確認。對於人而言,這是個苦差事。
幾種解法:
QR Code:透過圖形化的方式,轉化超長的 IdBar Code:概念同 QR Code,經常用在水費、電費帳單縮小範圍:常見的例子是電商購物取貨,透過兩階段範圍限縮,達到精準取貨:- 限縮範圍:
超商本身就是個小範圍的籃子 (Bucket), - 索引反轉:原本訂單編號是難以理解的,反轉成使用者自身的資訊,像是身分證末三碼、手機末三碼,重新對應到訂單編號
- 限縮範圍:
常見的實作
幾個常見的 ID 實作 (以下部分由 ChatGPT 產生):
UUID (Universally Unique Identifier)
設計考量: UUID 是由標準定義的一組算法來生成的,其中包括基於時間、隨機數或其他唯一性來確保生成的 ID 全球唯一。常見的版本包括 UUIDv1(基於時間戳)、UUIDv4(隨機生成)等。
適合的場景: UUID 非常適合需要全局唯一性的場景,例如分佈式系統中的唯一標識符,以及需要在不同系統之間進行數據交換的情況下。
針對資料庫設計的 TSID (Time-Sorted Unique Identitifer)
雪花演算法 (Snowflake ID)
設計考量: Snowflake ID 是 Twitter 提出的一種分布式 ID 生成算法,它結合了時間、機器 ID 和序列號來生成全局唯一的 ID。時間戳確保 ID 是有序的,機器 ID 確保唯一性,序列號則確保在同一時間內生成多個 ID 時的唯一性。
適合的場景: Snowflake ID 適用於需要大量且分佈式生成的 ID,例如分佈式系統中的數據庫主鍵、消息隊列的消息 ID 等場景。
Auto-Increment
設計考量: 自增 ID 是由資料庫管理系統(如 MySQL、PostgreSQL)自動生成的,每次插入一條新記錄時,ID 會自動加一。這樣的設計簡單且高效,但僅限於單機系統或資料庫範圍內的唯一性。
適合的場景: 自增 ID 適用於單機系統或者資料庫範圍內的唯一性要求不高的場景,例如小型網站的用戶 ID、文章 ID 等。
KGS (Key Generation Service)
設計考量: KGS 是一種由中央伺服器生成的 ID,並使用了分佈式的生成機制,確保全局唯一性。它可以採用類似於 Snowflake 的方法,但由中央伺服器統一管理 ID 的生成,以防止 ID 的重複和衝突。
適合的場景: KGS 適用於需要強大唯一性保證和集中管理的分佈式系統,例如大型企業應用系統中的全局唯一標識符、金融交易系統中的訂單 ID 等。
結論
Id 設計背後要思考用途、未來性、實作的選擇,上述還有很多沒有整理:
驗證:如何驗證這個唯一性是否有被篡改過,也是設計要考慮的外部操作與內部操作:外部指的是 User Interface 的 Id,內部指的系統內部操作。前者是會揭露給使用者,使用者會拿來操作與溝通,後者則是系統內部自己在用的。
這些之後有空再來整理。
題外話: 你是 ID 還是 Id?
延伸閱讀
站內資料
參考資料
- Unicode
- Cattle vs Pets | DevOps Explained
- 如何寫程式處理中華民國的身份證字號?
- TSID – Time-Sorted Unique Identifiers
- Instance ID uniqueness
Comments
About
著作
演講
- 演講錄影 @ Youtube
- 探索職涯、複利人生 - AWS Career Exploration Day 2023
- 個人著作 SRE 書友見面會
- 軟體測試實務 - 新書發表會
- 探索職涯、成就未來 - AWS Career Exploration Day 2022
- 從理想、到現實的距離,開啟品味軟體測試之路
- 91APP 在 AWS 上的 SRE 實踐之路
- 在矩陣型組織裡,如何有效管理 AWS 的成本結構與系統架構
- 災難演練 @ AWS 實戰分享
- 導讀持續交付 2.0 - 談當代軟體交付之虛實融合
- 聊聊軟體交付的濫觴 談產出物管理
- 從緊急事件 談 SRE 應變能力的培養
- 邁向 API 經濟 - API Gateway 導入之旅
- Monitoring Tools 大亂鬥 - AWS CloudWatch
- Ops as Code using Serverless
- 淺談系統監控與 CloudWatch 的應用
AWS Certifications


