記錄 之前 寫下的 Service Catalog 的概念。
Service Catalog
2019/05/06 12:43:00
導讀持續交付 2.0 - 談當代軟體交付之虛實融合
2019/04/27 19:55:31
敏捷三叔公 David Ko 的邀約,讓我有機會到新竹交大跟大家分享 持續交付 2.0 的心得~
底下整理這次分享的簡報、摘要與錄影。
Java Version Manager
2019/04/07 18:21:00
現在各個語言都有 Version Manager,像是 node 的 nvm、ruby 的 rvm、golang 的 gvm,Java 沒有官方的工具,但也有類似的工具。
底下整理的都是針對 macOS。
Study Notes - VPC FAQ
2019/04/07 13:30:00
整理 VPC 一些常見的問答。
一個人的 Working Backwards
2019/04/05 10:30:00
AWS CTO 在他的 Blog 提到 Amazon 產品規劃的方法: Working Backwards,最近我把這想法放在 個人、團隊、還有 企業發展 三個地方。
軟體交付的四大支柱 (Four Pillars of Software Delivery)
2019/04/04 23:43:00
上週 (2019/03/28) DevOps Meetup 分享的主題:聊聊軟體交付的濫觴 談產出物管理 (Artifacts Management),我提出了 軟體交付四大支柱 (Four Pillars of Software Delivery) 的想法,如下圖:
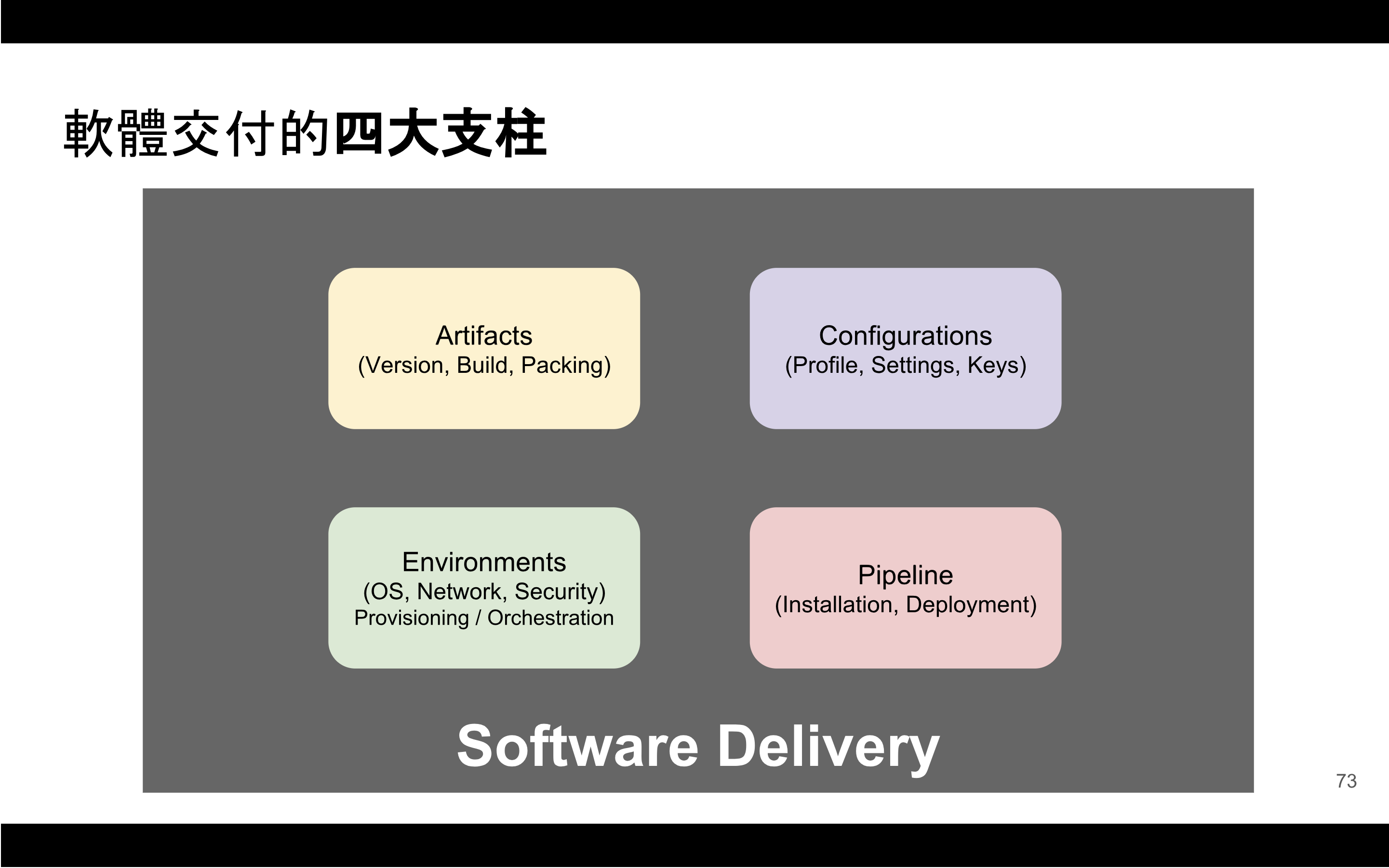
支柱 (Pillar) 的意思就是在交付軟體過程,如同蓋房子,要先蓋地基與支柱,然後才能疊加其他的東西、蓋牆壁、放水電管線等,對應到軟體開發也就是開發、測試、維運任務。
Pillars 的命名想法參考自 AWS Well-Architected
Updated 2023/07/19: 本文收錄在個人著作 《SRE 實踐與開發平台指南》 - 2023/08 上市
依照四大支柱的描述,整理過去寫的文章列表,以及對應到這四個 Pillars 的關係:
Study Notes - EC2 Auto Scaling 導入與應用
2019/04/04 23:30:00
整理導入 EC2 Auto Scaling 到新的系統、新架構過程中,在團隊協作溝通、前中後的技術確認、以及常見問答 … 等問題。
EC2 Auto Scaling 系列文章
Study Notes - EC2 Auto Scaling 常見問題
2019/04/04 23:30:00
整理導入 EC2 Auto Scaling 過程中,常見的問答。
EC2 Auto Scaling 系列文章
Study Notes - EC2 Auto Scaling - Termination Policies
2019/04/03 23:30:00
Auto Scaling 會自動增加機器,也會自動刪除機器,那 Auto Scaling 怎麼知道要砍哪一台?看最舊的?看最新的?還是看心情?
如同前面說描述,一個通用的機制的考慮必須是全面性的,所以接下整理的就是很多人會關心的問題:EC2 Auto Scaling 對 Instance 的 刪除策略 (Termination Policies)。
EC2 Auto Scaling 系列文章
Study Notes - EC2 Auto Scaling - Scaling Policies
2019/04/03 23:30:00
EC2 Auto Scaling 是自動控制 EC2 橫向擴展 (Scalable) 的機制,名稱有個 Auto 的字眼,很多同事就會問這樣問題:
不是
Auto了,為什麼還要設定?
這是個好問題,因為大家都以為自動了,就啥都不要管了 XD
實際上自動只是一種最終目的,而整個機制必須保留彈性,讓過程中,如果有非預期的狀況,可以做各種適度的橋整與安排,而這就叫做 Scaling Policies。
EC2 Auto Scaling 系列文章
再談『為什麼寫文件?』
2019/04/03 10:30:00
寫文件,對很多人是很痛苦的事情,特別是工程師。不過,我卻一直很享受這件事情,享受重新組織整理知識的過程,因為這個過程獲得最多的是我自己。
將與才之『縱觀全局』
2019/04/02 01:21:00
我喜歡有這種特質的人:
讀整個系列的小說看整個系列的電影玩整個系列的遊戲聽整個系列的音樂用整個系列的產品- ….
他們對於這些作品,有一系列、完整的體驗、心得、想法、延伸、甚至是創作。
管理者如何持續學習技術?
2019/03/30 00:16:00
很多技術背景的工程師,隨著年紀與歷練,會有機會帶團隊,成為 Team Lead / Techincal Lead,甚至轉換身份成為管理者。這些轉換很常是學而優則仕、公司上級的期待、被逼上火線 … 但這都算是被動因素,也就是不是自己願意的。
管理 實際上是另一個高度專業的工作,所需要的技能與技術工作者是截然不同的,像是協調、溝通、用人、管人、管事、領導、激勵 … 等看起來像是打雜的任務。因為需要漸漸地放手最熟悉技能 (技術) 讓團隊去執行,也因此很多初任管理工作會常常出現 患得患失 的狀況。
這一收一放,一段時間之後會發現,自己對技術會越來越陌生,跟團隊成員比較起來會越來越不如,很常會被底下的人質疑自己的技術能力,可是頭上戴著主管的帽子,需要做技術決策、選擇、提出建議 … 等,很多人因此就打退堂鼓放棄了,回到純粹的 Tech Leader 的角色。
接下來,我打算整理一些心得,分享從工程師到技術管理者的心得,先以這個問題開始:
管理者如何持續學習技術?
聊聊軟體交付的濫觴 談產出物管理 (Artifacts Management)
2019/03/28 23:43:00
Artifacts Management (以下簡稱 AM) 這個題目很少人在談,大部分 持續交付 也不太會著墨,有趣的是大家每天都在用它,卻從來不知道他是什麼,所以 AM 有以下這三個特色:
- 沒啥存在感
- 很少人知道這是什麼
- 大部分『持續交付』的書不會談
大概就是這樣:
有趣的是,Google “Artifacts Management“ 這個關鍵字,我的文章居然是排在第一位。。。表示這題目真的不多人在討論 XD
Updated 2023/07/19: 本文部分內容收錄在個人著作 《SRE 實踐與開發平台指南》 - 2023/08 上市
K8s 學習筆記 - 維護與常見問題
2019/03/17 19:41:58
延續 K8s 學習筆記 - kubeadm 手動安裝 的整理,本文整理 K8s Cluster 安裝或者維護過程遇到的問題。
K8s 學習筆記 - 工具篇
2019/03/17 19:41:58
延續 K8s 學習筆記 - kubeadm 手動安裝 的整理,本文整理一些 K8s 常用的工具,主要參考自 K8s 官方的 Addons。
K8s 學習筆記 - kubeadm 手動安裝
2019/03/17 19:41:58
K8s Cluster 安裝分幾種選擇:
全自動: Master / Worker Nodes 安裝都不用管,連升級 K8s 版本都不用管,像 GCP 的 GKE半自動: Cluster 的建置與管理是半自動,需要自己處理 K8s 升級。類似產品如下:- kops: Master / Worker Nodes 都自己裝,除了這些,也包含網路規劃、權限等
- EKS: Master Node 由 AWS 管理,使用者管理 Worker Nodes,詳細筆記參閱:K8s 安裝筆記 - AWS EKS
- Experience EKS Anywhere: AWS OpenSource 的 EKS 版本,可以安裝在自己的環境。
半手動: 從 VM / Machine 開始就要自己來,也就是本文,主要是使用 K8s 官方工具kubeadm。全手動: 全都自己來,每個 k8s 的角色都自己安裝,從 kube-apiserver、etcd、kube-proxy … 等。
本文整理的是半手動的安裝筆記,也就是以 kubeadm 為主,嘗試過的排列組合 (K8s version x OS x Hypervisor) 如下:
- QNAP Virtualzation Station
- Ubuntu 20.04:
- 1.21.1
- 1.23.4 (2022/03)
- Ubuntu 18.04:
- 1.16.14
- 1.18.0, 1.18.6
- 1.14.7, 1.14.9
- Ubuntu 20.04:
- Proxmox
- Ubuntu 18.04:
- 1.18.0, 1.18.6
- 1.14.7, 1.14.9
- Ubuntu 16.04:
- 1.11.3
- Ubuntu 18.04:
- VMWare Fusion (macOS)
- Ubuntu 18.04:
- 1.18.0, 1.18.6
- 1.14.7, 1.14.9
- Ubuntu 16.04:
- 1.11.3
- Ubuntu 18.04:
- AWS EC2
- Ubuntu 16.04:
- 1.11.3
- Ubuntu 16.04:
針對開發者本機環境,請參考 Experience minikube、microK8s、K3d、K3s … 等
看見怎樣的全貌 - 軟體開發的三體問題
2019/03/17 10:30:00
自從 Ruddy 老師提倡:《專案之初,首重看見全貌》的觀念,這想法與我過去引導團隊的 視野 很雷同。因為我一直用 視野 在思考全貌這件事,這反映了各個組織層面的運作、協作、溝通、產能。
我這邊講的『視野』一詞,可以是 Perspective (遠景)、Aspect (觀點)、View (視圖)、Dimension (維度)、 …
視野包含的 X、Y、Z 軸,三軸構成的整體全貌:
X 軸 - 產品 (Product): 抽象的事,也就是產品的概念,例如 ERP、CMS 都是一些產品Y 軸 - 團隊 (Team): 具象的人群,可以是技能團隊、跨職能團隊 (任務團隊)或者管理團隊Z 軸 - 架構 (Architecture): 具象的物,也就是技術架構與實踐,包含單體架構、微服務、分散式架構 … 等。
這些會構成三種主要排列組合 (XY、XZ、YZ),形成了全貌的層次。除了三軸,另外看不到的是 時間軸 (T),會牽動 X / Y / Z 的改變,講的是 企業的發展階段。我畫了一張圖,呈現如何用三軸看到視野與全貌在組織運作的關係,底下分別說明三軸的關係。
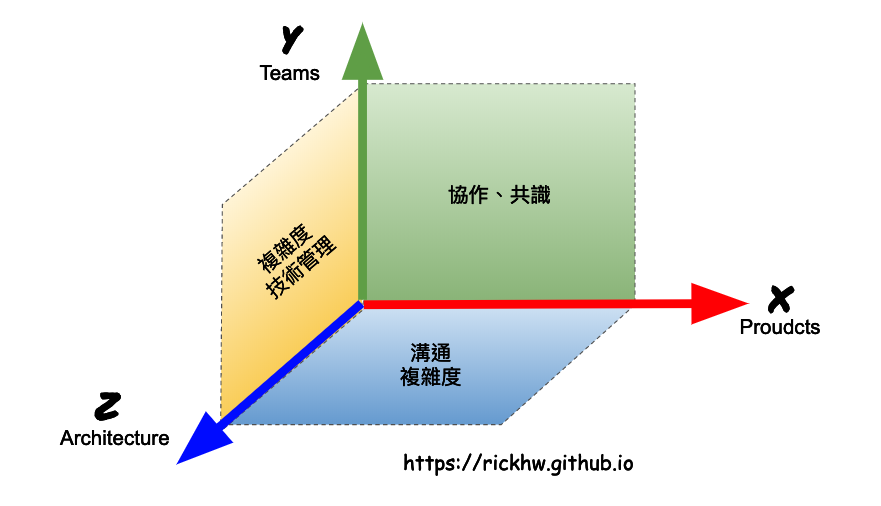
updated 2019/04/27
這張圖於新竹敏捷社群 Meetup 的分享:導讀持續交付 2.0 - 談當代軟體交付之虛實融合
文件的持續交付
2019/03/10 19:55:31
在 協同合作系統建制與導入 一文中,有個段落在說明 文件管理,主要概念就是如何讓 文件的持續交付 這件事情,在組織裡能夠落實。底下文字整理自今年 02/22 的 草稿
Study Notes - I/O Models
2019/02/27 22:30:00
很久以前在研究 nginx 時,過程針對他的 I/O Model 有了初步的了解,但是追本朔源還是經典著作 UNIX Network Programming Chapter 6. I/O Multiplexing,本文整理 BIO、NIO、AIO 等著名的 I/O Models 筆記。
W. Richard Stevens 美國電腦科學家,有多本經典著作,像是
UNIX Network Programming、TCP/IP Illustrated 系列。
SRE Team Lifecycles
2019/02/04 12:43:00
整理並且簡譯 Google Blog 文章:Do you have an SRE team yet? How to start and assess your journey 的摘要,這篇文章描述如何建立 SRE 團隊,以及三種階段的 SRE 團隊。
Issue Tracking 在企業裡的價值 - KM
2019/01/21 23:30:00
這篇整理去年公車上寫的三段 memo:
- 2018/10/16: 談 Issue Tracking 在組織裡的價值 - 知識管理
- 2018/12/05: 談議題管理層次
- 2018/11/28: 複雜的資訊流,造成的資訊落差
基本的概念如下圖:
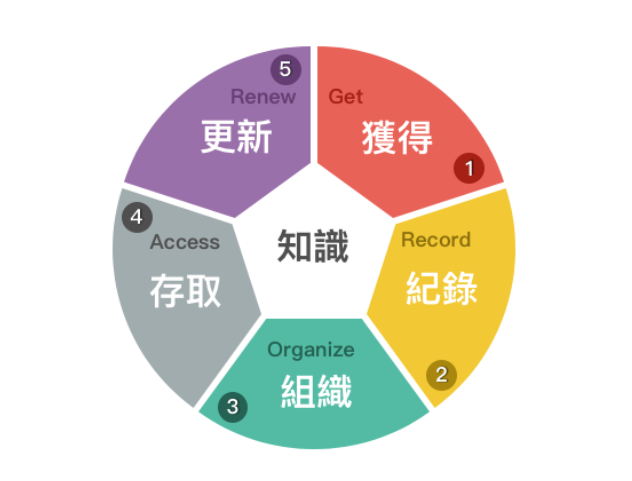
閱讀能力的重要性
2019/01/20 21:42:30
天賦與努力
2019/01/12 21:42:30
2018 的思考隨記:下半年
2019/01/10 21:42:30
2018 的思考隨記:上半年
2019/01/10 21:42:30
有時候樂手在舞台上表演的時候,同一首歌彈了幾百次、甚至幾千次,彈久了即興是理所當然的。但可能因為現場氣氛、溫度、當天晚餐的食物、空氣的味道、聽眾的情緒 …. 眾多因素,最後即興出一段自己都不知道怎麼彈出來的經典,事後也很難彈出那樣的感覺與味道。有些我個人喜歡樂手的 Live ,同一首歌重複找了 n 個版本,錄音室版、Live、Unplugged、Rock、Orchestration、Pinao、Acoustic Guitar …. 通常會有幾版本特別的棒,但也就出現那一次而已。
很多想法,是在特定情境、時空背景之下疊加出來的,而那些時空背景激盪的想法,在事後回顧的時候,會想,為什麼平常的我想不出這樣的東西?底下的截圖,是 2018 年我在特定條件之下,寫下的想法整理,有些有公開,有些則沒有。
- 因為是私人的筆記,所以圖中的人名就馬賽克了。
- 整理過程發現有點多,拆分成 H1、H2 兩篇。
關於 DevOps 的討論與想法
2019/01/08 12:39:00
這篇整理我 2018 年在 DevOps Taiwan 發言過的文字,談論到的包含軟體測試、持續交付、Artifact Management、軟體開發流程、維運 … 等,主要是記錄一些想法、觀念、觀察、經驗分享,然後截圖作紀錄。
這些文字發文的時間大多在上下班的公車路上,可以集中精神的狀況留下的,一些想法都是透過討論以及問題激盪出來的。
- 因為是公開發言,所以文中的人名我就不馬賽克啦 XDD
- 為了避免爭議,發言以截圖方式紀錄。
人力招募 - 六、到職:訓練、目標、評核
2018/12/22 03:21:00
需要專職的 Release Engineer?
2018/12/16 12:43:00
本文整理 SRE 讀書會 Round 2 的討論與筆記。問題是:
團隊 Release 的角色是否應該專職? (不管是叫 DevOps Engineer, Release Engineer, or SRE)
那天 (2018/09/13) 討論的章節是 第七章 提交階段,我在回程公車上寫下這段 筆記,重新整理成文章,也補充一些想法。 這問題討論通常到最後會分成兩種:
不該專職:團隊成員輪著做,不應該專職 (偏向 Agile 的概念)應該專職:技術 know how 很深,應該專人專職 (偏向傳統、大型組織)
我想想都對、也都不對,因為這兩個都沒有提到 前提條件與背景,這樣的討論不會有結論。我從以下幾個面向分析:
- 企業階段
- 架構與組織
- 產品特性
Updated 2023/07/19: 本文收錄在個人著作 《SRE 實踐與開發平台指南》 - 2023/08 上市
DevOps 8 字環的誤區:左環問題
2018/12/15 23:43:00
本文整理 2018/12/07 我寫的一篇論述:DevOps 8 字環的誤區。
Eventually Consistent 與 Dynamo NWR 模型
2018/12/09 13:30:00
整理 AWS CTO - Werner Vogels 著名的論文: Eventually Consistent (ACM), (Blog) 重點與筆記。
IPv6 基本概念
2018/11/29 10:30:00
Products Naming for AWS
2018/11/18 19:35:00
我心裡一直有這樣問題:
AWS 有些產品用 Amazon 開頭(像 Amazon EC2、Amazon API Gayeway、Amazon CloudWatch),有些則是用 AWS 開頭(像是 AWS CloudFormation、AWS Lambda、AWS IoT),如下圖:
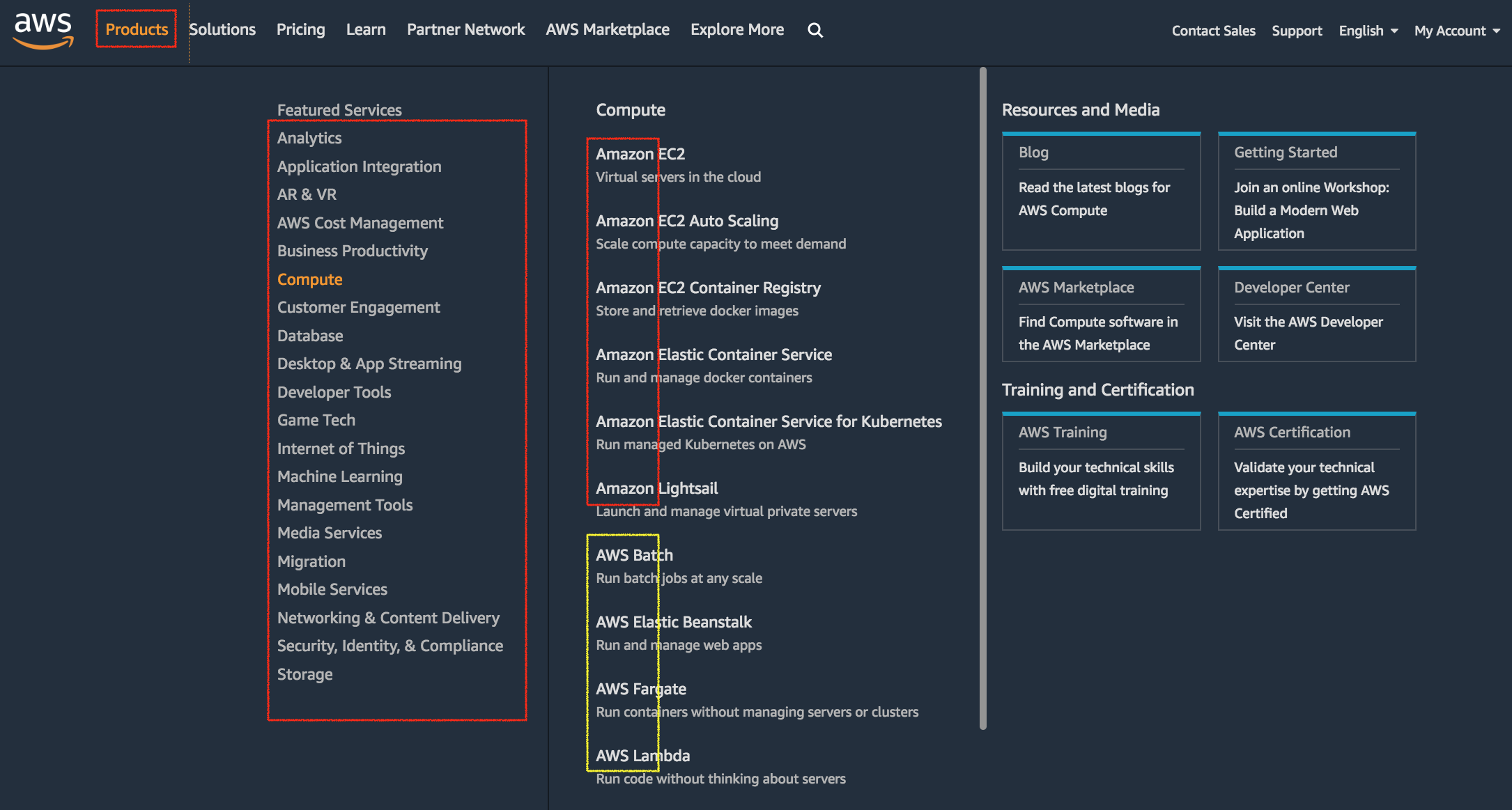
底下整理我對於命名前置詞命名的猜測。
心得:持續交付 2.0
2018/11/14 22:30:00
今年 (2018) 三月,我在公司內完成長達半年的 SRE (Site Reliability Engieering) 讀書會,快結束時就在盤算下一本候選書,希望激盪團隊更多想法。那時候首選就是當代軟體工程的經典之作:持續交付 (Continuous Delivery)。
在讀書會開始不久,有次跟朋友聊到持續部署想法,當時我提到因為時空背景的關係,這幾年各種新的概念與技術快速發展,特別是雲端架構應用、微服務與分散式架構的實踐概念,彷彿不斷的在提醒大家,持續部署 應該有不同的想法與實踐。當時的筆記如下圖:
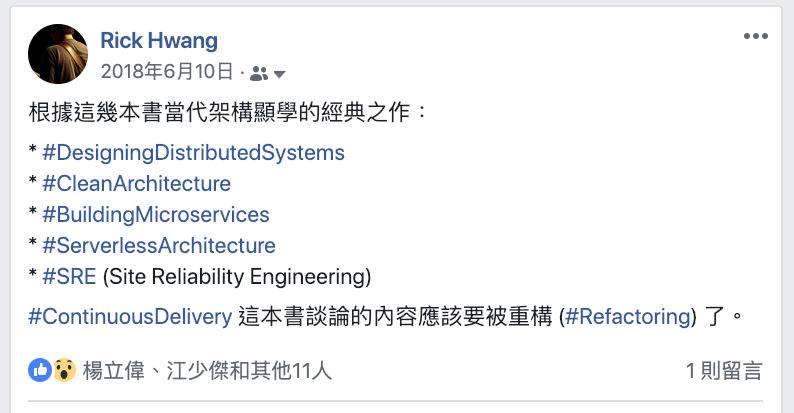
同時 DevOps 與敏捷開發 (Agile Development) 概念鋪天蓋地的出現,大家意識到 霧卡世界(VUCA) 正在驅動整個軟體產業,除了持續部署,持續交付商業價值將面對更大的挑戰!VUCA 是 Volatility(易變性)、Uncertainty(不確定性)、Complexity(複雜性)、Ambiguity(模糊性)的縮寫。
戰爭之前,不管做了多少參謀作業,戰爭第一聲槍響的時候,所有計畫都會隨之改變。
– 美國名將
麥克阿瑟
雖然世界變化之快,常常讓人迷失,但變化越快,越要靜下心思考。正當我在思考,是否將這些資訊做通盤整理,彙整成更有意義的文字時,十一月七日早上,是立冬之日,Ruddy 老師在我桌上放了一本書,作者是人稱喬幫主的喬梁老師大作,書名:持續交付 2.0。當時的我心裡想:『嗯,我想要的,應該都在這裡面了。』

2019/04/27 於新竹敏捷社群 Meetup 的分享:導讀持續交付 2.0 - 談當代軟體交付之虛實融合
混沌工程 (Chaos Engineering)
2018/10/08 18:53:00
整理一些關於 Chaos Engineering 的資料。
About
著作
演講
AWS Certifications


