Site Reliability Engineering (SRE, 網站可靠性工程)
SRE 全名是 Site Reliability Engineering 網站可靠性工程,是 Google 提倡的系統管理實踐之道、指導思想,這個名詞同時也是 軟體工程師 (Software Engineer) 的角色,可以類比於傳統的維運工程師或系統工程師,但是 SRE 是用 計算機科學 和 軟體工程 手段,實踐 大型系統維運、分散式系統 的設計與開發。
Updated 2023/07/19: 個人著作 《SRE 實踐與開發平台指南》 於 2023/08 上市,內容整理個人過去數年實踐的經驗與總結。
推薦閱讀
這本書我個人分成以下幾個部分,讀者可以依據個人身份、角色、經驗,選擇有興趣的部分:
一、指導原則:這段是描述 SRE 時會提到的關鍵原則二、事件管理:該如何面對異常事件、管理、從失敗中學習三、工程實踐:用軟體工程來看待系統維運四、管理與訓練:管理者如何在團隊中實踐 SRE 的精神。五、箴言:書本有很多讓人省思的箴言,值得深思
一、指導原則
這本書 Part 2 談 SRE 的指導原則,也是大部分在描述 SRE 的文章、或者職缺描述 (Job Description, JD) 時,一定會有的原則,這些原則包含了:
- 擁抱風險、錯誤預算 (Error Budget):重點在於激勵團隊共同承擔責任,從錯誤中學習,這點跟 DevOps 精神是一致的。
- 服務水準目標:討論 SLIs, SLOs, SLAs 等概念
- 減少瑣事:用 50% 的時間,開發自動化維運工作
- 監控分散式系統
- 自動化、簡單化:自動化可能的問題以及其必要性
- 發行工程 (Release Engineering):可以說是對應到 持續交付 (Continuous Delivery) 的概念
- 軟體工程實踐維運工作:這也是 SRE 跟一般維運工程師、系統工程師不一樣,重點在於 Ops as Code 的概念
這段是認識 SRE 想法的入門心法,要如何讓團隊理解 SRE,這些章節提供了很多指導原則。
二、事件管理
書本 Part 3 具體實踐 針對 事件管理 有很多著墨,我以時間點來看整理事件的 前、中、後 ,團隊應該做什麼?下圖是我整理的想法,也是 SRE 書中提到的概念:
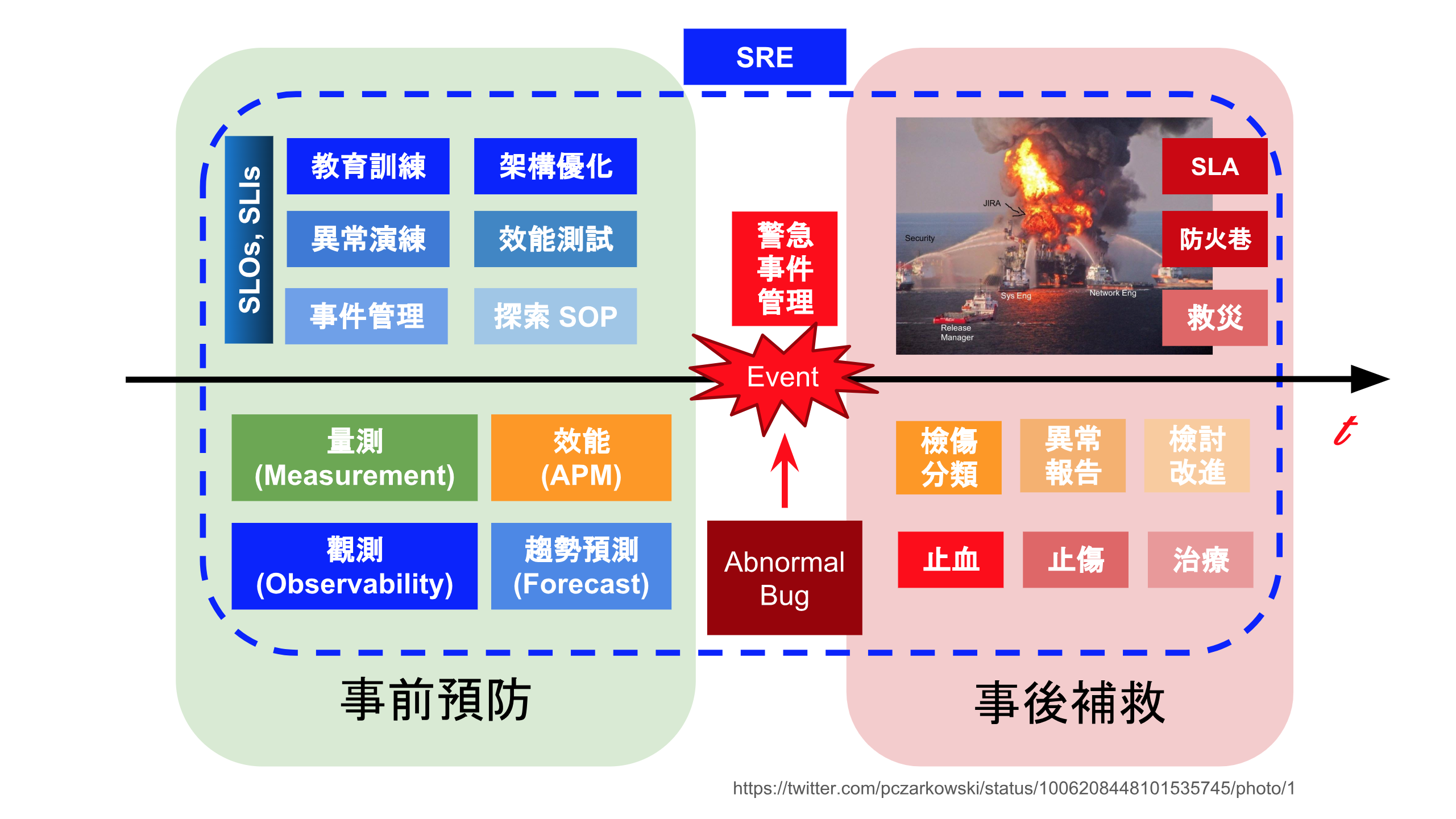
詳細參閱:演講:從緊急事件 談 SRE 應變能力的培養:我在 DevOpsDays Taipei 2018 分享的心得
書本章節先後次序剛好是時間軸次序,整理如下:
- CH11 Being On-Call: 從事件發生之前,如何平衡 On-call 的工作
- CH12 Effective Troubleshooting: 討論事件當下,如何有效地故障排除技巧
- CH13 Emergency Response: 整理了緊急事件處理的案例,以及面對的方法
- CH14 Managing Incidents: 討論事件管理的方法,事件當下的角色、協作、作業、程序、溝通 … 等
- CH15 Postmortem Culture: Learning from Failure: 如何從錯誤中學習的文化、不究責
- CH28 Accelerating SREs to On-Call and Beyond: 如何培養 SRE 加入 On-Call
- CH33 Lessons Learned from Other Industries: 從不同專業背景學習
異常事件處理非常仰賴紮實的軟體工程、團隊協作能力、應變管理,在各種領域都有類似的案例。特別用了其他領域的經驗,整理了類似的想法給大家參考:
- 緊急應變 (Emergency Response):這篇整理幾個例子,其中電影『薩利機長』是我最喜歡引用的例子。
- 跨領域的緊急應變 - SRV 斷弦事件:音樂舞台表演看異常事件的處理
如果你的時間有限、如果你不是技術背景,那麼推薦閱讀這些章節!會讓你有醍醐灌頂的感覺!
三、工程實踐
SRE 很強調用 計算機科學、軟體工程 實踐維運工作。書裡 Part 3 具體實踐有一半的章節都在談論這些屬於硬技能的工程實踐,特別是 分散式系統 (Distributed Systems),包含了以下:
- 前端伺服器的負載平衡、資料中心內部的附載平衡
- 處理系統超載 (QPS, Rate Limit)、處理連鎖反應
- 分散式系統:分散式一致化提高可靠性、分散式排程任務、資料處理管線、資料讀寫一致性 (CAP theorem)、分散式共識
- 可靠的進行大規模發行 (Launch Coordination Engineers, LCE)
其中對於 負載平衡 (Load Balancer) 有很多技術、原理的著墨,特別是在 分散式架構 盛行的年代,很多人不會注意到 分散式系統謬論、Rate Limit and Throttling、分散式共識、Message Bus … 等核心問題。
想要深入了解大型分散式系統是如何運作、背後的原理,想要成為架構師、規劃出能面對大流量的系統,這些章節是必讀的!
Updated 2019/05/17: 由小弟翻譯的書 分散式系統設計 在 2019/05/20 上市。
四、管理與訓練
如何把 SRE 的概念放入既有的團隊是不容易的,如果你是團隊的 Leader、技術管理階層、企業經營者、產品經理,這些章節是可以好好研究的:
- 可靠的進行大規模發行
- 迅速培養 SRE 加入 on-call
- SRE 與其他團隊的溝通與協作
- SRE 參與模型的演進歷程
- 其他行業的實踐經驗
DevOps 的精神強調團隊的垂直整合,而身為管理者的你,如何讓這樣的新觀念、想法落實到現場,落地到組織,讓團隊能夠自主學習,這些章節有詳細的說明。
五、箴言 (Slogan)
這本書很多章節開頭有一些意義深遠的 箴言 (Slogan),完整請參考『Slogan in SRE』的整理。如果想要快速、簡單的了解這本書的精神與想法,快速讀過這些句子,你大概知道這本書的想法。底下整理我個人很喜歡的句子:
- Hope is not a strategy. (不能將運氣當作策略)
- Be warned that being an expert is more than understanding how a system is supposed to work. Expertise is gained by investigating why a system doesn’t work. (值得警惕的是,理解一個系統如何工作,並不能使人成為專家。只有靠調查系統為何不能正常工作才行。)
- Things break; that’s life. (東西早晚要壞的,這就是生活。)
- If you haven’t tried it, assume it’s broken. (如果你還沒開始親自測試過某件東西,那麼就假設他是壞的。)
- The cost of failure is education. (學習是避免失敗的最好辦法。)
這些只是其中一小部分,而我個人最喜歡的句子:
Things break; that’s life.
這句話在 AWS Whitepaper 也經常提到類似的概念,像是 Design for failure:不管是什麼東西,都會壞掉,設計架構時,就要思考壞了怎麼辦?同樣的, Chaos Engineering 也是同樣的概念。
另外一段話也是我很喜歡的:
值得警惕的是,理解一個系統如何工作,並不能使人成為專家。只有靠調查系統為何不能正常工作才行。
這段話呼應到我平常 鼓勵同事的話:
沒什麼大神,雷踩多了,還活著的,就是大神。
這是一種推坑的概念,但是延伸想法平常的開發流程,就是要多做 系統性的測試。
FAQ
Q1: DevOps 和 SRE 有啥不一樣?
Google 說 SRE 是 DevOps 的實踐,用程式碼表示就是:class SRE implements DevOps。我個人的看法:DevOps 是
理念原則,SRE 則是實踐方法。
DevOps現在的我是用整個企業經營的角度來看 (高大上),也就是 Development 其實是產品開發週期,包含從需求、寫程式、測試、部署等段落,各式各樣的開發流程,不管是敏捷開發、還是我整理的 Software Development Lifecycle 都是在討論這段;而 Operation 則是企業整體的營運。從業務把客戶引入之後,開始使用產品,形成營收 (Incoming)、系統維運成本、企業經營成本、最後算出的淨利、毛利 … 等。Operation 我看的是COO (營運長)的概念,Development 我看的是CPO (產品長)的概念。
Q2: SRE 要會啥技能?
SRE 也是軟體工程師,他除了需要具備傳統系統工程師 (System Engineer) 的技能之外,同時要具備
軟體開發的能力、分散式系統知識。至少會一種 script、一種 compiling language 是基本的,了解基礎的計算機科學知識,像是 OS、Algorithm、Data Structure、Computer Architecture、Networking … 都是必要的基礎專業。
Q3: SRE 跟傳統的 MIS、機房 OP 有什麼差異?
SRE 的主軸任務是維持系統的穩定服務,必須用程式自動化完成這些任務。自動化 代表著,要瞭解如何
軟體工程達到目的,而不只是為了自動化而自動化。
Q4: SRE 這本書翻譯的好嗎?
SRE 簡、繁中文版譯者 孫宇聰,中國人,2007-2014 在 Google SRE Team。因為他本身就在 Google SRE 待過很長的時間,所以語意上不是問題,簡繁中文版我都有看過,閱讀上是可以接受與理解的。
Q5: 有哪些領域和 SRE 有關係?
這個問題有點意思,用這張圖來回答比較生動:
原文 點這裡,歡迎來喇低賽 XD
Q6: SRE 的概念會不會跟 敏捷開發 有衝突?
這些想法不會衝突。SRE 是強調用
軟體工程、機算機科學做維運任務。敏捷開發團隊具備高度的學習、彈性、自組織的特性,在這樣的條件之下,SRE 可以協助團隊更快速面對 真實的世界、給予團隊建議。團隊可以因此更的快地適應,更快地面對市場的挑戰!對我個人來講,不管是敏捷、SRE、DevOps,目的都是
Getting Things Done,當這樣想的時候,做事的過程,自然而然就會有更 宏觀的視野 來面對。相關文章:
Q7: SRE 這本書適合什麼人看?
如同章節的介紹,這本書很適合開發團隊各種角色一起閱讀討論。非工程背景、管理職適合閱讀 Part 1、CH12-16 事件管理部分、以及最後的管理與教育訓練。工程背景則建議完整閱讀整本書。
Q8: 哪裡有 SRE 相關資源以及討論?
Facebook 社群 DevOps Taiwan、Site Reliability Engineering Taiwan 有很多讀書會的資料: SRE 讀書會筆記
結語
知道 SRE 這個又新又潮的詞,是在 2016 年的 媒體報導 文章開始,那時候我已經負責系統維運工作一段時間,每天面臨各式各樣系統管理、與維運的任務,處理各式各樣系統異常、寫了 n 篇異常報告,要監控、值班、要管理團隊、要學習 Cloud 相關知識,在這些日常維運的過程,同時因為 DevOps 一詞在社群鋪天蓋地的湧現,各種研討會、新技術如荒洪般的衝向我。這樣的衝擊、經歷,讓我不斷的在思考底下這些問題:
- 維運的精神?
- 什麼是維運?維護甚麼?運轉什麼?
- 什麼是監控?量測與觀測的差異?
- DevOps 字義上是有開發、維運,那 測試 呢?
那段人生的歲月就在這些思考中起起伏伏、跌跌撞撞中度過,而 SRE 的出現讓我有了新的方向,特別是書本前言這段讓人非常有感的話:
軟體工程有的時候和育兒類似:雖然生育過程痛苦、艱辛,但是養育成人的過程才是真正耗費心力之處。傳統的軟體工程花費很多精力討論軟體開發的過程,而不是其後的維護過程。統計顯示,一套軟體系統的 40% ~ 90% 成本,其實是花費在建置之後,不斷維護的過程。
業界流行的一個說法:一套系統如果已經開發完成,部署在正式環境上,那麼他就是『穩定的』,不需要那麼多工程師花費精力去最佳化、維護。
我們認為這樣的說法是錯的,從這個角度來看,如果軟體工程主要專注於設計和建構軟體系統,那麼應該有另一個種職業專注於整個軟體系統的生命週期管理:從其設計一直到部署,經歷不斷改進,最後順利除役。這樣的職業必須具備非常廣泛的技能,並且和其他職業的專注點不同,Google 把這個職位稱為
網站可靠性工程師 (SRE, Site Reliability Engineering)。
因為個人 Dev、QA、Ops 三段完整的經歷,有一些深刻的體悟與心得,加上書本開場這段話,讓我更深刻的體悟到 Dev & Ops 從來就不只是口號,而是具體且深刻的實踐,是動詞!SRE 告訴大家 Google 如何 做,站在巨人肩膀,讓大家有機會走得更穩、更強壯!
本文授權 DevOpsDays Taipei 2018 及 天瓏網路書店 全文轉載
最難的事









相關文章 (站內)
SRE 相關
- 個人著作《SRE 實踐與開發平台指南》
- 演講:從緊急事件 談 SRE 應變能力的培養
- SRE Opening and Chapter 1
- Conclusion SRE
- Slogan in SRE
- 跨領域的緊急應變 - SRV 斷弦事件
- 緊急應變 (Emergency Response)
- 分散式一致性問題與共識演算法
測試與自動化相關
維運、運維
- 系統維運的精神
- What is Ops?
- 再談啥是維運?
- 演講:Ops as Code using Serverless
- Go Live
- What is Monitoring?
- 演講:淺談系統監控與 CloudWatch 的應用
- AWS Certified SysOps Administrator - Associate 準備心得
延伸閱讀 (站外)
- 孙宇聪:来自 Google 的 DevOps 理念及实践
- Google 儲存 SRE 團隊負責人第一手經驗大公開 - iTHome
- DevOps Engineer、SRE 徵才求職雜談 - 凍仁的筆記
- SRE 讀書會筆記
Google 官方資料
- What’s the Difference Between DevOps and SRE?
- SRE vs. DevOps: competing standards or close friends?
- SRE fundamentals: SLIs, SLAs and SLOs
- What is ‘Site Reliability Engineering’?
相關資料、書
- Atlassian’s Incident Management Handbook - Free Download
- Database Reliability Engineering: Designing and Operating Resilient Database Systems
- Seek SRE
- The Site Reliability Workbook - Online
相關 FB 社群
Comments
About
著作
演講
- 演講錄影 @ Youtube
- 探索職涯、複利人生 - AWS Career Exploration Day 2023
- 個人著作 SRE 書友見面會
- 軟體測試實務 - 新書發表會
- 探索職涯、成就未來 - AWS Career Exploration Day 2022
- 從理想、到現實的距離,開啟品味軟體測試之路
- 91APP 在 AWS 上的 SRE 實踐之路
- 在矩陣型組織裡,如何有效管理 AWS 的成本結構與系統架構
- 災難演練 @ AWS 實戰分享
- 導讀持續交付 2.0 - 談當代軟體交付之虛實融合
- 聊聊軟體交付的濫觴 談產出物管理
- 從緊急事件 談 SRE 應變能力的培養
- 邁向 API 經濟 - API Gateway 導入之旅
- Monitoring Tools 大亂鬥 - AWS CloudWatch
- Ops as Code using Serverless
- 淺談系統監控與 CloudWatch 的應用
AWS Certifications


