Designing Configuration Loading Strategies
應用程式 在啟動 or 初始化 (Initial / Startup)的時候,配置 (Configuration) 載入的流程經過這麼多年的發展,基本上已經有一個常見的策略模式了,這些概念很重要,卻也很常被忽略,最後系統上線後只能夠透過改 Code 重新部署才能處理問題,好的設計應該是改配置就能滿足需求。
這篇原文是寫在 SRE 社群的一篇 筆記,借保哥的 整理 發揮另一個常見的東西:配置與設定的讀取策略設計
設計摘要
名詞定義
配置 (Configuration): 通常指的是儲存在某種 Storage 形式,像是檔案或者 存在 DB 的 Table設定 (Settings): 每個配置裡的 K/V 一對一對的東西稱為設定應用程式 (Application):經常簡寫 AP or App,以獨立 Process 存在的 Deamon (Web) 或者透過 CronJob 短週期執行的批次應用。像是用 Java / C# / Golang / PHP 寫的 Web App、或者非同步作業 Console 應用。
讀取策略
在大部分的應用程式 (特別是 Open Source Software, OSS) 設計的配置大概都有下圖的概念:
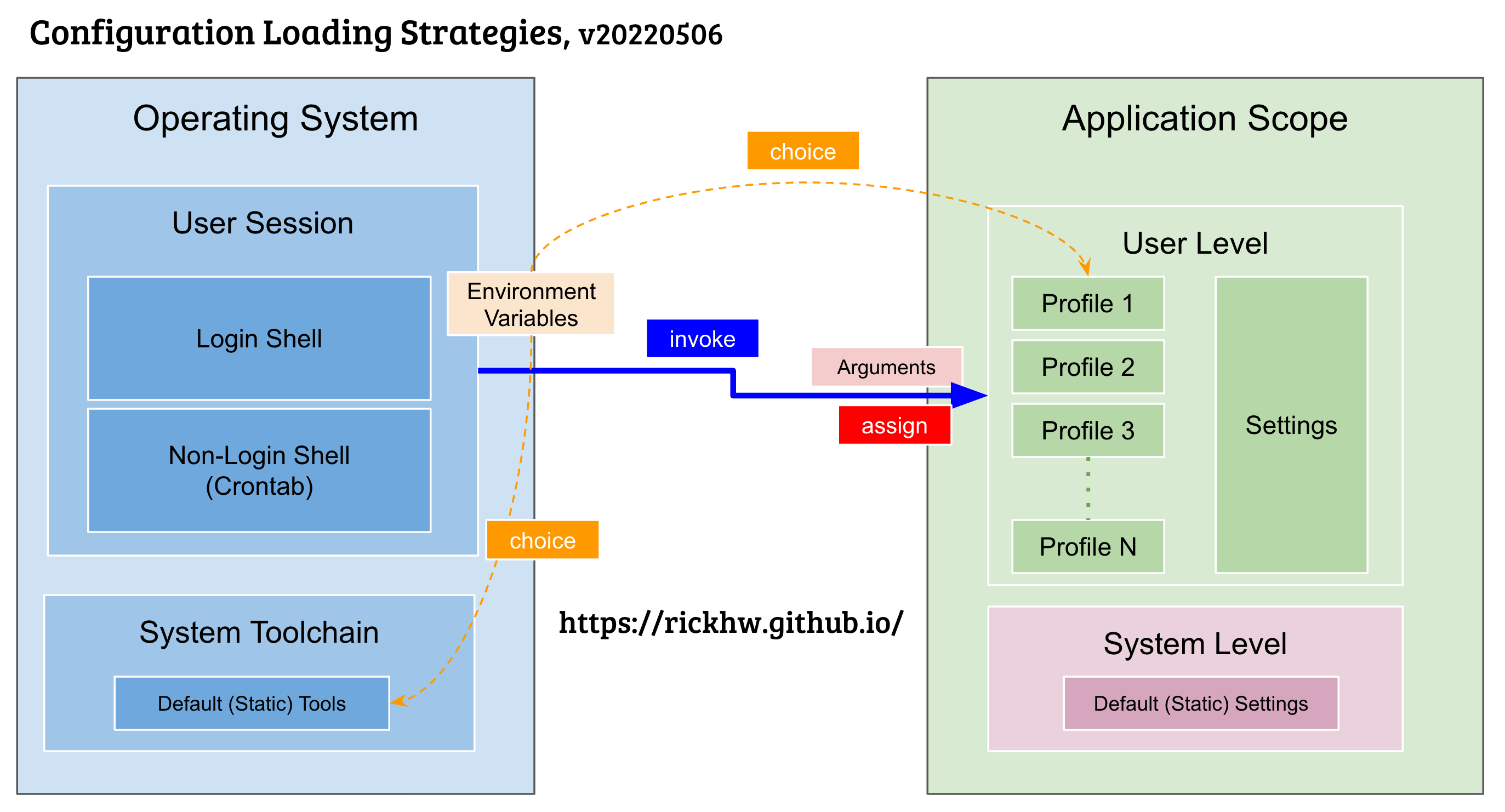
黑色實線區塊:代表實體存在 Storage 的軟體白色實線區塊:代表存在於 Memory 的 Runtime左邊區塊:表示從作業系統角度切入,User Session 分成 Login Shell 和 Non-Login Shell 兩個狀態。右邊區塊:User Session 的狀態下,應用程式 (例如 nginx or express app、dotnet console … etc) 透過中間藍色的invoke帶起 Process 的過程。- 環境變數與 Arguments 隨著 invoke 帶給 Process
而這些配置讀取的策略大部分的 先後次序 :
[紅底]讀取環境變數設定值:根據現在的 Session ,讀取環境變數 (Environment)- 環境變數的用途是
選擇用途,而不是指定數值,像選擇 Profile,而不是指定 port number。 - 選擇 Profile 表示包含選擇不同認證授權的 Token 來源。
- 注意 Session 的狀態讀取的來源有所差異,例如 Login-Shell 跟 Non-Login Shell 初始的流程就不一樣,相關參閱 Shell and Bash Concepts 的說明。
- 環境變數的用途是
[橘色]先看看參數是否有指定 (args / options),有的話會覆寫或者跳過2) User Level 的設定[綠色]讀取 使用者設定檔 (Config):通常讀取次序在環境變數之後,透過環境變數的選擇用途,指定大範圍的檔案或者目錄結構。- 配置檔的
形式分成靜態、動態兩種,靜態像是存在 storage 的 json / yaml,動態像是存在 RDB / Consul 裡的 K/V - 配置讀取的
模式分成Pull、Push兩種。- Pull 是應用程式主動去某個地方拿,像是檔案系統、DB … etc;
- Push 則是配置檔的來源自己透過 Event 的方式把異動推給 Application。
- 配置檔的
[紫色]上述如果都沒有,直接使用 System Level (程式碼) 裡的預設值,像是寶哥舉例的kRestrictedPorts
常見的一些工具讀取配置的策略大概都是這樣,像是大家常用的 kubectl、aws cli、 vscode 、git … 有些除了上述四的步驟,會多了認證授權的 credential.
這個 配置與設定的讀取策略設計 是大家可以留意的,出問題時,或者在用新工具、在開發新應用程式的時候,依照這個邏輯,才能正確確認應用程式有讀取到正確的配置。
實際上實作讀取策略的讀取次序,有可能跟上述描述剛好相反,但是結果是一致的,例如透過繼承概念實作讀取策略,那就是先讀預設值。
注入來源
通常 APP 在設計時,在 Code Level 會有一些 預設 設定值,然後在第一次啟動應用程式時,自動產生使用者配置,裡面會寫入一份預設值 (或者留白)。另外應用程式本身的執行程式通常也可以透過參數 (保哥文中提到的 --explicitly-allowed-ports=10080) 複寫這些設定值,或者可以透過 環境變數 (ENV) 選擇不同的 配置。
所以配置的設定值的來源有這些地方:
程式碼裡的預設值 (Code Level):在應用程式裡宣告的預設值。- 通常是寫在 Constants or Interface or Enum 或者 c 的 header (.h)
- 相對於
使用者層級設定,預設就是系統層級設定 (System Level Settings),像是 Linux/etc底下的都是系統層級的設定。
使用者層級設定 (User Level Settings):- 使用者層級的配置,通常會放在
$HOME/.<appname>/ (目錄)或者$HOME/.<appname>rc (檔案) - 第一次應用程式初始的時候,初始設定的策略有幾種,依照應用程式設計特性而定。
- 大家可以在自己系統 (macOS / linux / Windows)
$HOME底下發現很多 用點 (dot) 開頭的目錄或者檔案 - 我很常舉例的就是 unix 登入時的初始流程 Login Shell 與 Non-Login Shell 的概念,相關說明參閱 Shell and Bash Concepts
- 使用者層級的配置,通常會放在
臨時的參數啟動 (Inject by Arguments)- 通常給進階使用者、開發者自己使用,可以臨時替換配置檔裡的設定,不需要改檔案內容就能測試。
- Designing Test Architecture and Framework 提到的 Testcase 的 Config Management 就有這樣的設計。開發測試案例者,可以透過參數化的方式 overwrite 檔案的配置,提高
測試 - 測試案例的便利性。
環境變數指定 (Environment Variables):選擇適當的配置項目,像是選擇不同身份以及配置- AWS CLI 預設就是透過
AWS_PROFILE選擇不同的 AK/SK,沒有指定則讀取default - Environment Variables 的來源跟 unix shell 初始流程很有關係,相關說明參閱 Shell and Bash Concepts 的 Login Shell 與 Non-Login Shell。
- AWS CLI 預設就是透過
環境變數的應用
環境變數常見的用法有以下幾種:
- 指定使用者的 Profile:環境變數本身是 Session Base,適用的情境就是依照使用者身份,提供 Profile 選擇。
- 關鍵路徑的指定,像是
HOME、LOG_PATH、Lib Path等 - 系統層級的交互餐數:像是 C compiler command 、 LDFLAGS (linker flags)
應用程式自己業務邏輯的參數,建議都放在 Configuration 裡,而不是透過 Environment 注入。
參數的設計
另外,通常建議設計一個 Flag (像是 --verbose、--debug、--dryrun) ,讓應用程式初始化之後顯示上述的配置,可以用來快速確認目前啟動是否正確。甚至直接做 Validation,只要配置有錯誤,就直接中斷應用程式。
預設值
Application Interface Spec
通常在除錯時,都要確認一些基礎資訊的正確性:
a. 由外而內: 輸入資料來源的正確性 (API Request Payload)
b. 由內而外: 應用程式的配置正確性
如果系統已經執行一段時間,通常找問題的點都會在 a),也就是輸入資料的正確性,像是 API 的 Payload 某些值有錯誤、超出範圍。
如果系統是新部署 (更版 / 業務拓展 / 測試環境),通常要先確認的是 b)、再來才是 a)。很多時候都是應用程式初始過程中的配置有問題,像是外部依賴的位址給錯了 (通常是 copy & paste 忘了改)、或者某些 secret 給錯、對於系統外部程式的依賴版本錯誤 … 等,而怎麼初始配置的流程則是除錯過程中必要知道的 Know How。
註:這裡的
內、外指的是應用程式從 Artifact 跑起來變成 Process 之後,給予的資訊流。以 WebApp 來講,由外而內就是透過 WebAPI 提供資訊所造成的行為。而由內而外則是 Process 自身內部 Event 或者生命週期提供的資訊,像是 Configuration。
上述的 a) + b) 我把它稱為 Application Interface Spec (暫時縮寫成 AppInterSpec) ,範圍涵蓋以下:
由外而內:使用者看得到的介面,形式有以下API: 形式包含WebAPI、Libraries API通訊協議與資料結構:- L7/HTTP:
- RESTful 的 request / response
- HTTP Header
- JWT Payload
- Cookies
- RPC 溝通的資料結構
- L7/HTTP:
- 通訊認證:
- 企業內部系統之間的通訊認證模式,相關概念參閱 聊聊分散式架構的服務治理
- 對外部系統的通訊認證模式
由內而外:開發團隊看得到的介面Environment Variables: 明確環境變數的用途與適用範圍Configuration: Config 與 Settings 的定義、配置檔案的策略、設定操作策略 (static / dynamic)Static (or 被動 / pull): file or db baseDynamic (or 主動 / push): event base, 像是 feature toggle 的實作, consul … etc.
Secret: 算是 Configuration 的一環,牽涉敏感,所以通常獨立於 Configuration 之外。- Loading 的技術概念與 Configuration 一致,同樣分成 static / dynamic or pull / push 等模式。
- Data Storage Source 會配合 KMS 方式加解密,也會有其他的管理政策配合。
Database Schema: 不管是 RDB or NoSQL,都是要有結構定義的Storage Structure: 非結構性的資料存放結構,通常都要有目錄結構的定義與宣告。
而本文談的是 2.1)、2.2) 的設計原則。
結論
開發者很常討論 OOD 的 DI (Dependency Injection, 依賴注入 or Dependency Inversion, 依賴反轉),談的是 Code Level 的注入資訊反轉、與注入策略與模式,這些都是程式啟動後 Runtime 過程 Object 的行為,不管是範圍 (Scope) 還是物件啟動的生命週期。
而本文著眼的是應用程式初始化 (Initial / Startup) 時,配置載入的流程策略與模式,我把這些配置稱為 Application Interface Spec 的其中一部分。Configuration 是應用程式層級的 DI,透過他可以靈活的控制應用程式的行為、邏輯,讓使用者有能力控制整個應用程式的行為,不需要改程式碼,重新編譯打包。
這個設計一個新的應用程式時候,就必須確立好 AppInterSpec 的範圍,然後經過開發的持續迭代,持續修正與調整。
延伸閱讀
- Shell and Bash Concepts
- Designing Test Architecture and Framework
- Study Notes - Key Management Service
- 聊聊分散式架構的服務治理
Comments
About
著作
演講
- 演講錄影 @ Youtube
- 探索職涯、複利人生 - AWS Career Exploration Day 2023
- 個人著作 SRE 書友見面會
- 軟體測試實務 - 新書發表會
- 探索職涯、成就未來 - AWS Career Exploration Day 2022
- 從理想、到現實的距離,開啟品味軟體測試之路
- 91APP 在 AWS 上的 SRE 實踐之路
- 在矩陣型組織裡,如何有效管理 AWS 的成本結構與系統架構
- 災難演練 @ AWS 實戰分享
- 導讀持續交付 2.0 - 談當代軟體交付之虛實融合
- 聊聊軟體交付的濫觴 談產出物管理
- 從緊急事件 談 SRE 應變能力的培養
- 邁向 API 經濟 - API Gateway 導入之旅
- Monitoring Tools 大亂鬥 - AWS CloudWatch
- Ops as Code using Serverless
- 淺談系統監控與 CloudWatch 的應用
AWS Certifications


