混沌工程 (Chaos Engineering)
整理一些關於 Chaos Engineering 的資料。
前言
- 當代架構和基礎設施通常是變動的、短暫的、不可預測的 …. 聽起來根本是來亂的 XD
- 災難還原 (DR) 通常不容易執行,因為本身就是個災難,而且很貴、是個大錢坑 …
- 關於 DR 的概念請參閱這篇整理: Using AWS for Disaster Recovery
- 我在 AWS reInvent reCAP 2019 的分享:災難演練 @ AWS 實戰分享
- 每個 IT Team 都要考慮架構性問題,但是各自的層次可能不一樣,有的專注在 OS / Networking Level、有的專注在應用層 (AP)、有的專注在資料 (Data),但是 Chaos Engineering 專注在整體。
- Chaos Engineering 是一個可以探索和管理未知問題的方法,進而提升系統的韌性
- 要玩 Chaos Engineering 請先做好監控、決定哪些服務是最重要的。。。否則混屯工程會變混亂工程。。。
經典好文
底下整理一些我個人讀過的文章、演講,並摘錄一些重點。
Intro to Chaos Engineering
By Tammy, she is
- Principal Site Reliability Engineer at #remlin
- former Senior SRE Manager at Dropbox
- and co-founder of GirlGeekAcademy
Published: 2018/02/06
Chaos Engineering: Compaines, People, Tools & Practices
一張很大的 mindmap (如下圖) 呈現 Chaos Engineering 相關的公司、推廣的人、工具、實踐原則 … 等資訊
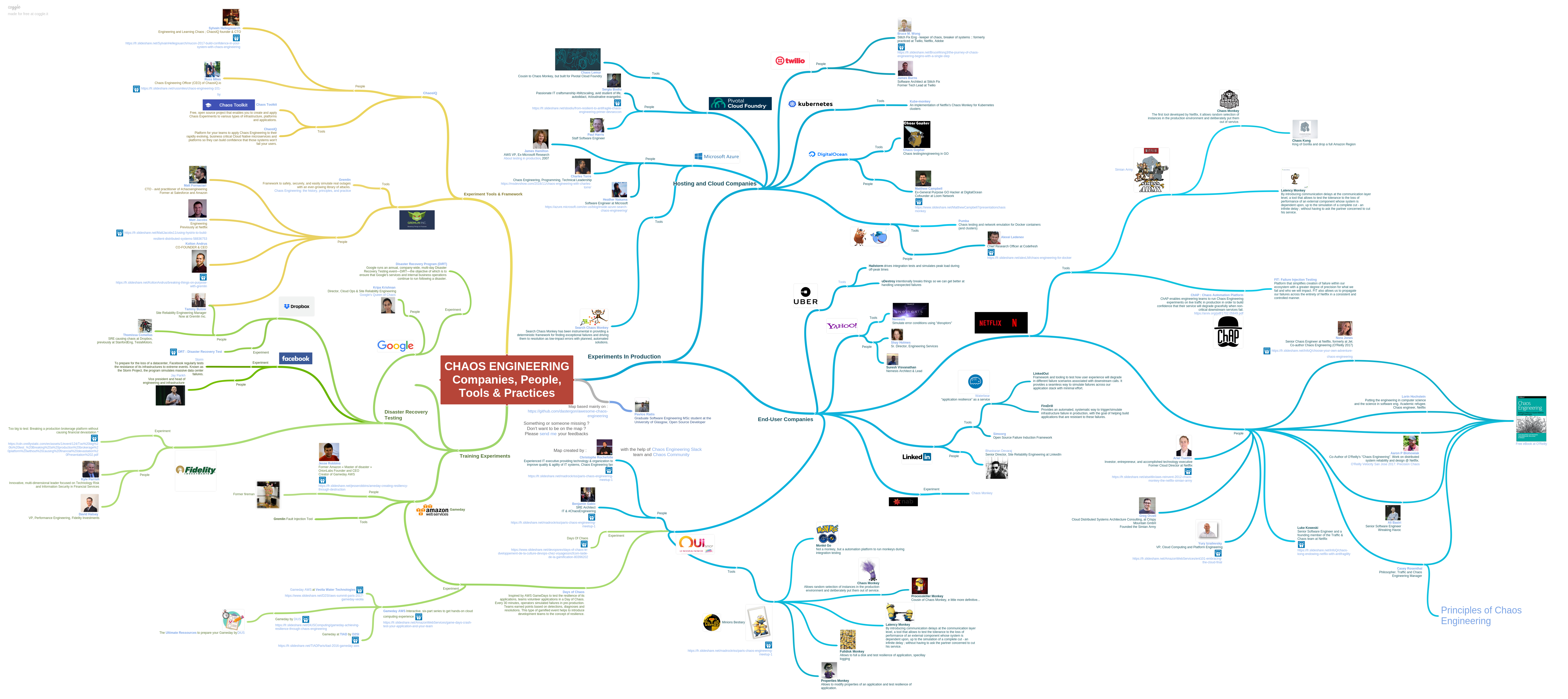
Awesome Chaos Engineering
如標題,我只能用 Awesome 來形容!這個 github 上整理了大部分 Chaos Engineering 的經典資料,包含文化面、書本、教育、工具、論文、Blog、新聞、研討會 … 等,幾乎想得到的,都可以在這裡找到。如果想要深入了解 Chaos Engineering 到底是什麼,把這裡的文章爬過就得到了!
混沌工程实践经验:如何让系统在生产环境中稳定可靠
這篇文章整理提到在正式環境中面對的挑戰以及問題,特別像是 Netflix 這種公司。底下是自 Netflix 2013 QCon 很經典的圖:

我很喜歡文章中的這兩句話,常常拿來提醒自己:
不是你選擇那一刻,是那一刻選擇你,而你唯一能選擇的就是作好準備。 (You don’t choose the moment, the moment chooses you. You only choose how prepared you are when it does.)
混屯工程不是製造問題,是揭露問題。
Chaos 談的很多是 連鎖性 問題,這點在 SRE CH22 有類似的介紹,也可以說是我在談系統測試 的概念。
Chaos Engineering的历史、原则以及实践
這篇整理了很多 Chaos Engineering 相關的資料,入門必讀。底下摘錄一些重點:
- 混沌工程最先出現在互聯網巨頭公司中,這些公司擁有大規模的分佈式系統,因為這些系統太過複雜,他們需要一些新的手段來測試它們。
- 為什麼要有目的地搞破壞?就像打疫苗可以預防疾病一樣,我們可以通過混沌工程來提升系統的免疫能力。我們向系統注入故障(比如延遲、CPU故障、網絡黑洞),找出系統潛在的弱點。
- 這些試驗增強了我們應對故障的能力,就像防火演習一樣。通過有目的地搞破壞,可以識別出未知的問題。
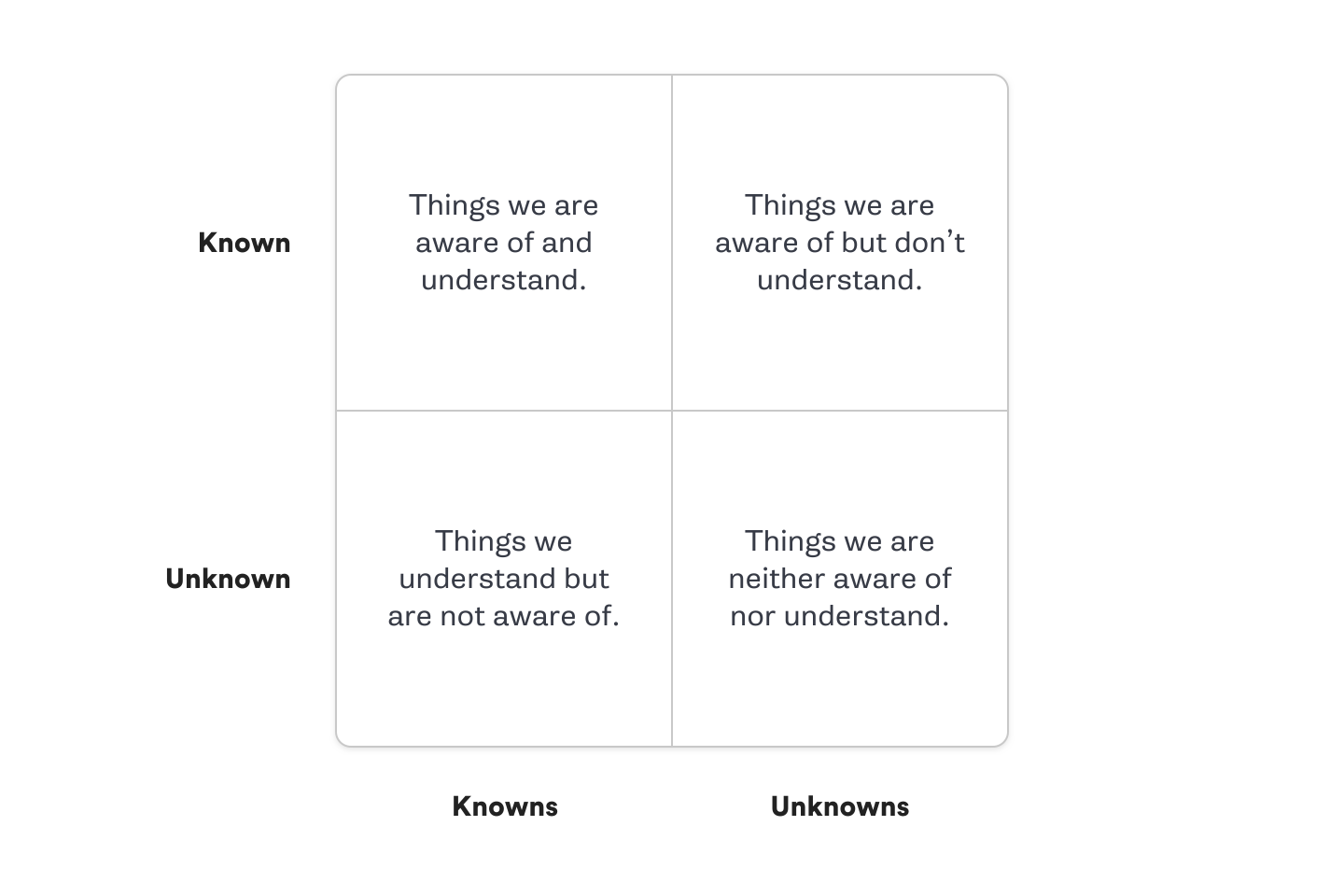
- Peter Deutsch 提出的分佈式系統八大謬論概括了程序員新手可能對分佈式系統做出的錯誤假設:
- 網絡是可靠的、延遲是零、帶寬是無限的、網絡是安全的
- 拓撲結構不會變、存在管理員這樣的角色、傳輸成本是零、網絡是同質的
- 混沌工程執行次序:已知、未知的排列組合
Published: 2018/04/08
Chaos Engineering for the Business
這篇整理曾商業角度來看道 Chaos Engineering 這個很技術性、很工程性的任務,他整理六個點,其中第四點是工程師一定要知道的。
底下摘錄重點:
- Tip №1: Don’t be afraid to drop the term
- Tip №2: It’s about Confidence, not Breaking Things
- Tip №3: Put Blast Radius and Learning Front and Centre
- Tip №4: Not just about Infrastructure, or even just the Technical
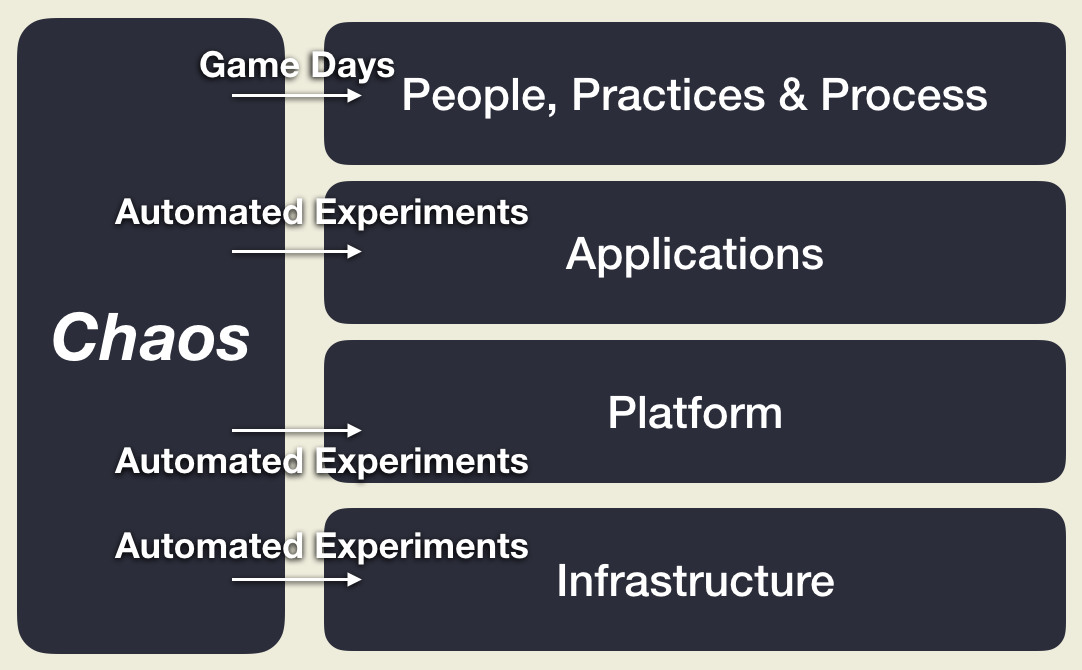
- Tip №5: It doesn’t have to be a big, up-front investment
- Tip №6: Know the benefits, know the limitations; don’t over-promise!
Adrian Hornsby
Adrian Hornsby 是 AWS 的技術傳教士 (Evangelist),他專注在 Chaos Engineering、Resilient、Operational 相關主題,底下系列文是我非常推薦的文章:
- Why Breaking Things Should Be Practiced - AWS Developer Workshop at Web Summit 2018
- Chaos Engineering
- Patterns for Resilient Architecture
- Towards Operational Excellence:
- Towards continuous resilience - 2021/03/25
相關詞彙
Chaos Engineering 的詞彙很多,底下是我在文章中常看到的,僅供參考:
- 理論
- Chaos theory, 混沌理論
- 三體問題
- 量子力學
- 蝴蝶效應
Antifragile (反脆弱): Chaos 的目的是什麼?反脆弱應該是其一。- 黑天鵝效應 (black swan):在一群白天鵝中出現一隻黑天鵝(black swan),被解讀為「最不可能發生但總是發生的事」。
- 所謂黑天鵝,是指看似極不可能發生的事件,它具三大特性:
不可預測性、衝擊力強大、以及,一旦發生之後,我們會編造出某種解釋,使它看起來不如實際上那麼隨機,而且更易於預測。 - Google的驚人成就就是一個黑天鵝事件;九一一也是。
- 為什麼要等到事情發生之後,我們才認得出黑天鵝現象呢?部分的答案是,在應該注意普遍現象時,人們長久以來卻習慣注意特定事件。我們習慣注意已經知道的事情,卻一而再再而三忽略我們所不知道的事情。
- 所謂黑天鵝,是指看似極不可能發生的事件,它具三大特性:
- 工程方法
- Chaos Monkey: Netflix 發明的搗亂方法
- SRE: Chaos Engineering 跟 SRE 有密不可分的關係
- Distributed Systems (分散式系統): 之所以會有這樣的需求,肇因於分散式系統這麼複雜的東西被大量實踐。
- Microservices: 微服務是分散式系統的實踐方法之一。也是現代最流行的架構,想當然耳,他一定要面對 Chaos Engineering.
- Disaster Recovery (災難還原)
- GameDay: 大家來找碴的一天
- resilience (韌性): 不倒翁
- elasticity (彈性): 我進來啦 我又出去啦
其他資訊
相關資訊很多,底下是我看過的。如果你不知道從哪開始,那就從 Awesome Chaos Engineering 開始,這裡整理的算是最完整的。
- Netflix 在 github 的 Chaos Monkey
- Chaos Engineering Working Group: Chaos 加入 CNCF 討論群
- Chaos Engineering: Why the World Needs More Resilient Systems
- Chaos Engineering: Why Breaking Things Should Be Practised
- Intro to Chaos Engineering
- Chaos Engineering 的历史、原则以及实践
- Chaos Engineering: Why Breaking Things Should Be Practised
- What is Chaos Engineering? Failure Becomes Reliability
- How Chaos Engineering Can Drive Kubernetes Reliability
- Awesome Chaos Engineering: A curated list of awesome Chaos Engineering resources.
- AWS re:Invent 2017 - Nora Jones Describes Why We Need More Chaos - Chaos Engineering, That Is
- Mastering Chaos - A Netflix Guide to Microservices
- Resilience4j
- 書
更新紀錄
- 2020/03/05: 新增 Adrian Hornsby 的 Towards Operational Excellence 系列文章
Comments
About
著作
演講
AWS Certifications


