淺談效能測試
本文整理重新摘分在 淺談軟體測試的階段與策略 整理的效能測試部分。
Scope of Test Stages
下面這張圖表達 淺談軟體測試的階段與策略 的概念:
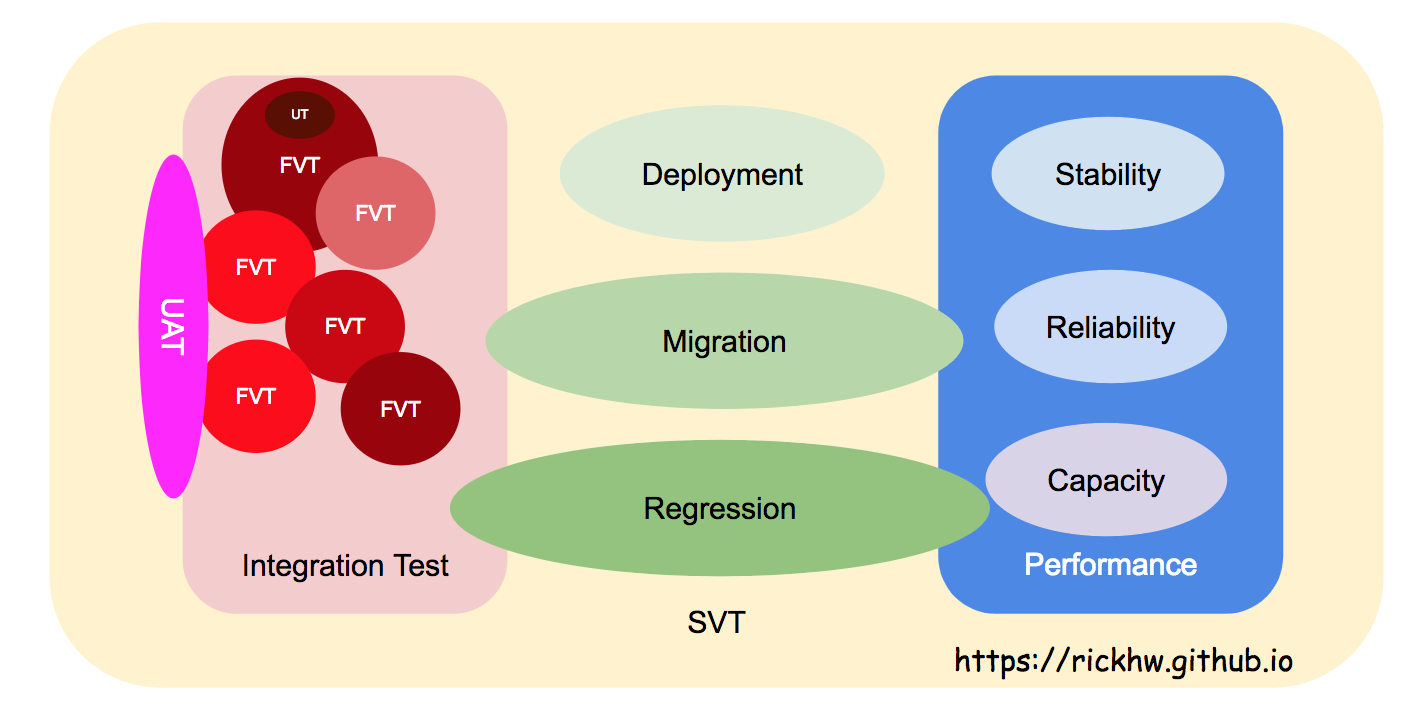
其中關於 效能測試 包含三大部分,也是本文描述的主軸:Capacity, Reliability, Stability
Performance Test
分成幾種: Stability, Reliability, Capacity
前提
作 Performance Test 的前提:FVT、Integration Test 要過。
我做 SQA Manager 的時候,本來是要去做 Performance Test,但是發現功能根本就不能用,所以就整個砍掉重來,先把
功能守住,直到通過率到一定程度之後,才開始 Performance Test。這段故事在 協同合作系統建制與導入 - 以 Redmine 為例 有提到一點。
環境建置考量:必須跟 Production 一致,可以利用 Cloud (ex. AWS, GCP) 快速建立完整的 Scale,測完就刪掉。
效能測試的準備工作
如果是測試 Web System ,那就要花時間把整個系統建置起來,準備好測試資料,餵到 DB … 等。
實際上不只是待測要花時間準備,測試的 Client 的準備也是要花不少時間的,例如:
- 模擬商業邏輯的資料,像是 Database Schema or 模擬使用者資料的 資料 … (啥鬼XD)
- 測試程式的設計,模擬功能的行為。以 Live Stream 就是模擬 IPCam 的資料丟到 Server 然後傳給 App。
- 測試程式執行環境的準備,要確認網路 Throughput 是否足夠
- 測試環境能否自動化建置,最好利用像是 AWS CloudFormation 這樣的東西
- 平常就要做好 Resource Provisioning 的工作。
- 用 AWS 的話,確認機器等級的 Network 狀況,透過 VPC Flow Log 蒐集狀況
- 確認 Network Tolopology 狀況,基礎網路服務 DNS / NAT 是否能夠乘載。
- 測試流程 (HTTP Request) 模擬與建制,可以從既有的 Log 分析
- 測試過程要蒐集的資料與 Log, 如何觀測 (Observailitiy)?參閱 Monitoring vs Observability
- 預期會產生的資料如何分析?
這段 AWS NLB 的介紹中:Deep Dive: New Network Load Balancer 提到效能測試,Client 開了 c4.xlarge * 100
Capacity (容量量測)
目的:
量測 (Measure)系統可以乘載的數據,單位可以是線上使用者、單位時間內的交易量、單位時間內的流量 … 等,像是 QPS (Query Per Second)、RPS (Request Per Second) …
量測的對象就是整個系統,系統要考量以下:
- 一定的硬體資源,包含 Networking, Computing, Memory, Storage .. 等條件,應用程式能夠滿足多少的處理單位。
- 放在 AWS 上的網站來說,使用
c4.large的機器,最大能夠乘載多少的 HTTP Request,這個值稱為Benchmark. - 有了
Benchmark可以根據需求推論出系統需要的成本。例如已經知道c4.xlarge可以同時乘載 5k/second request,,那麼就可以推論如果有 100k/s request 需要準備多少台 c4.xlarge - Rate Limit: 服務提供固定的 SLA,像是可以乘載的數量上限,超過時候,告訴 Client 已經滿了。這種設計應用在
搶購 (flash sales)是必要的。
Performance 測試除了上述面向,另一個面向就是帶測體是屬於整個 stack,還是 layer or tier。
例如傳統的 web 有三層: Web -> Application -> DB,每個 layer 都有自己效能的問題,最終的目標是了解整個 stack 的 benchmark,但實際在執行上應該要先 bottom up,也就是先找到每一個 layer 自身的效能,最後才能測出 stack 的效能。
另一個例子是 realtime stream,像是影音串流的效能,先不考慮使用 p2p 技術,考慮使用 server relay 技術,一般實作就是: data source -> server relay -> client (app or web)
這三個端點都各自有傳輸的延遲時間 latency,每個節點都有運算時間,所以效能就包含兩個議題:
- Latency: 資料傳輸時間,相依於網路,WAN -> Gateway / LAN / NAT / Wi-Fi … 等節點
- Computing: 每個節點 encode / decode 的運算、protocol (RTSP)、mjpg / h264 … 等
從 Stack 的效能測試屬於 Top-Down View,大部分都會直接用這種方式開始,特別是沒有很多資源的狀況之下。一開始入門效能測試也都會從這個角度著手的比較多。
從 Layer 則屬於 Bottom-Up 方法,先找到每個 Layer 的 Capacity,然後再用數學方法模擬出整個系統的樣子,最後用 Infra as Code 的方式建立整套的系統,模擬測試。
執行容量的量測是需要一些方法,才能有效精準的進行。詳細參閱 如何量測系統的容量? 一文整理如何執行的方法論。
- 這些與系統架構會有直接關係,現代的常見的 Pattern 就是 API Gateway、Service Mesh
Reliability (可靠性)
目的:
- 不論時間與條件的運作,如果系統任一元件或角色 Crash 狀況,恢復之後,所有的資料以及狀態都會恢復正常。
- High Available (高可用性), Fault Tolerance (容錯), Resilience (彈性), Recoverability (可回復性), Loosely Coupled … 都是可靠性的實踐方法
- 可靠性工程是架構性議題。
- Nexflix 提出的
Chaos Engineering也算在這裡
更多參閱 可靠性工程 Reliability Engineering 一文的整理
相關參考:
Stability (穩定性)
目的:
- 一定的資源之下
- 長時間,且大量的 Request 之下
- 系統維持在穩定狀況,不會有 CPU / Memory 凸波、或者是 Memory Leak、Disk I/O 瞬間的狀況。
如果應用程式本身具備 GC 機制,當記憶體使用量到一定程度時,則會自動恢復。
現象:不倒翁
外在變因
效能屬於系統性測試的其中一個環節,其重點在於:
無論外在環境怎麼改變,內在系統都能夠穩定的運作
如同底下這些圖:



更多參閱: 輕鬆聊:系統測試 (SVT) 的三兩事
延伸閱讀 (站內)
- 淺談軟體測試的階段與策略
- 軟體自動化測試常見的問題
- Software QA 的職能條件
- 三種 QA
- 自動化 XXX 的陷阱
- 輕鬆聊:系統測試 (SVT) 的三兩事
- Designing Test Architecture and Framework
- 如何量測系統的容量?
- 可靠性工程 Reliability Engineering
Comments
About
著作
演講
- 演講錄影 @ Youtube
- 探索職涯、複利人生 - AWS Career Exploration Day 2023
- 個人著作 SRE 書友見面會
- 軟體測試實務 - 新書發表會
- 探索職涯、成就未來 - AWS Career Exploration Day 2022
- 從理想、到現實的距離,開啟品味軟體測試之路
- 91APP 在 AWS 上的 SRE 實踐之路
- 在矩陣型組織裡,如何有效管理 AWS 的成本結構與系統架構
- 災難演練 @ AWS 實戰分享
- 導讀持續交付 2.0 - 談當代軟體交付之虛實融合
- 聊聊軟體交付的濫觴 談產出物管理
- 從緊急事件 談 SRE 應變能力的培養
- 邁向 API 經濟 - API Gateway 導入之旅
- Monitoring Tools 大亂鬥 - AWS CloudWatch
- Ops as Code using Serverless
- 淺談系統監控與 CloudWatch 的應用
AWS Certifications


