系統發生異常時,第一時間如何快速止血?
這也是個朋友問的問題,問題截圖如下:

先不管誰有沒有穿褲子,從整體來看,重新整理問題:
系統發生異常時,第一時間如何快速止血?
底下整理我經常在處理分析時的思路。
Updated 2023/07/19: 本文收錄在個人著作 《SRE 實踐與開發平台指南》 - 2023/08 上市
事件當下的應變
理想的前提
以下都是理想,也是很多人覺得的 default 要有的:
- 清楚知道架構,包含邊界、依賴性、網路拓墣、應用服務的架構
- 每個服務、每個 Layer、網路、APP 都有完整的 Tracing 機制
- AP 都有寫出完整的 Log、有 Log 系統可以查詢、Log 具備可讀性
- 所有的資源 (CPU / Memory / I/O) 都有已經有 Metrics
- 都有 Alert,然後有對應的通知
- …
還可以寫很多 理想 的前提,但這些都是理想,真實世界往往不是這樣的,異常發生時,就必須要脫光光,看得清清楚楚。
找問題的思路
底下截圖是我當時的回答,也是實務上在幫很多團隊、內外部問題查找時的基本思路:

把上述文字重新整理如下,分段處理描述:
服務邊界與依賴性:把每個 service 的 downstream / upstream or dependency (外部依賴) 搞清楚- 服務本身的上下游依賴
- 內、外部依賴
通訊:確立每個來回的通訊協議 / 通訊模式- 通訊協議:http / https, tcp, gRPC, ampq … etc.
- 通訊模式:sync, async
基本監控與 AP Log:- 運算資源有沒有蒐集系統的 metrics: cpu / mem / disk / tcp / disk i/o, network throughput …
- AP 的 log 吐去哪 … 怎麼收集?
吞吐量:把這條路徑上的瓶頸找出來. 對口的水管可能大小不一, 例如 t2.nano 對 c5.large 的不對等的水管 …AP 本身的特性: CPU-Bound, Mem Bound, IO Bound, Time Bound …
通常到 3 能確認,問題就大概知道了,很常是 AP 本身沒寫好、沒處理好 Exception、資源吃太多炸鍋 ….。
但經驗告訴我,很多時候,是連 1) 有哪些都搞不清楚,或者不知道要找誰,所以 1) 一開始會花很多時間疏理清楚,特別是內、外依賴。通常 1) 搞清楚後,會發現整個架構很詭異,但是每天卻要跟他共生共存 XDD
以架構的演進原則來看,勢必要適度的收斂,最好是把網狀結構,往星狀結構走,否則整個維運會很難搞的。好吧,我去年有講啦,在 P66 … 連 1) 都搞不清楚,本身就是災難。根本不用談什麼架構 …
這段概念,在 DevOpsDays Taipei 2018: 從緊急事件 談 SRE 應變能力的培養 都有提到,參閱 P64 ~ P98
再談一次 理想的前提
找問題的假設前:
請當做沒有前述的
理想的前提
為什麼這樣說,因為我個人接觸過的,不管是在公司內部、或者外部協助,遇到的問題都是:
理想前提 根本不存在
普遍的人 (80+ %) 不會把圖畫下來,組織裡面也沒人在維護,系統已經上線一段時間,所以出問題的時候,通常很少人能夠拼得出系統架構的全貌。
所以當把理想前提協助客戶、團隊疏理清楚之後,通常到上一段的步驟三,他們自己就知道問題在哪了,這個步驟大概可以解決八成的問題,像是 JVM 的調成、依賴性問題、系統資源問題、架構性問題。
剩下兩成的問題,需要有完整的 Log 與 Metrics,然後透過分析工具處理,才能抓到方向。
觀測系統狀況:分散式追蹤 (Distributed Tracing)
分散式系統是現代架構的常態,所以有效的追蹤就非常重要,其中很重要的概念就是 分散式追蹤 (Distributed Tracing)。
常見的實踐技術:
- Kiali
- Jaeger
- AWS X-Ray
不過這些都 假設已經 在系統上,但通常這個假設都不成立,而你要在不成立的狀況,判斷系統的狀況。另外是,這些工具的目的都是在觀測系統狀況,有這些工具能加速、精準的判斷問題點。而系統問題點的判斷,是取決於對於整體的了解的深度與廣度。
所以一開始朋友的問題,理想的情境,就是有分散式追蹤。
結論
這問題其實就是去年我在 DevOpsDays Taipei 2018: 從緊急事件 談 SRE 應變能力的培養 談的,當時我畫了底下這張圖:
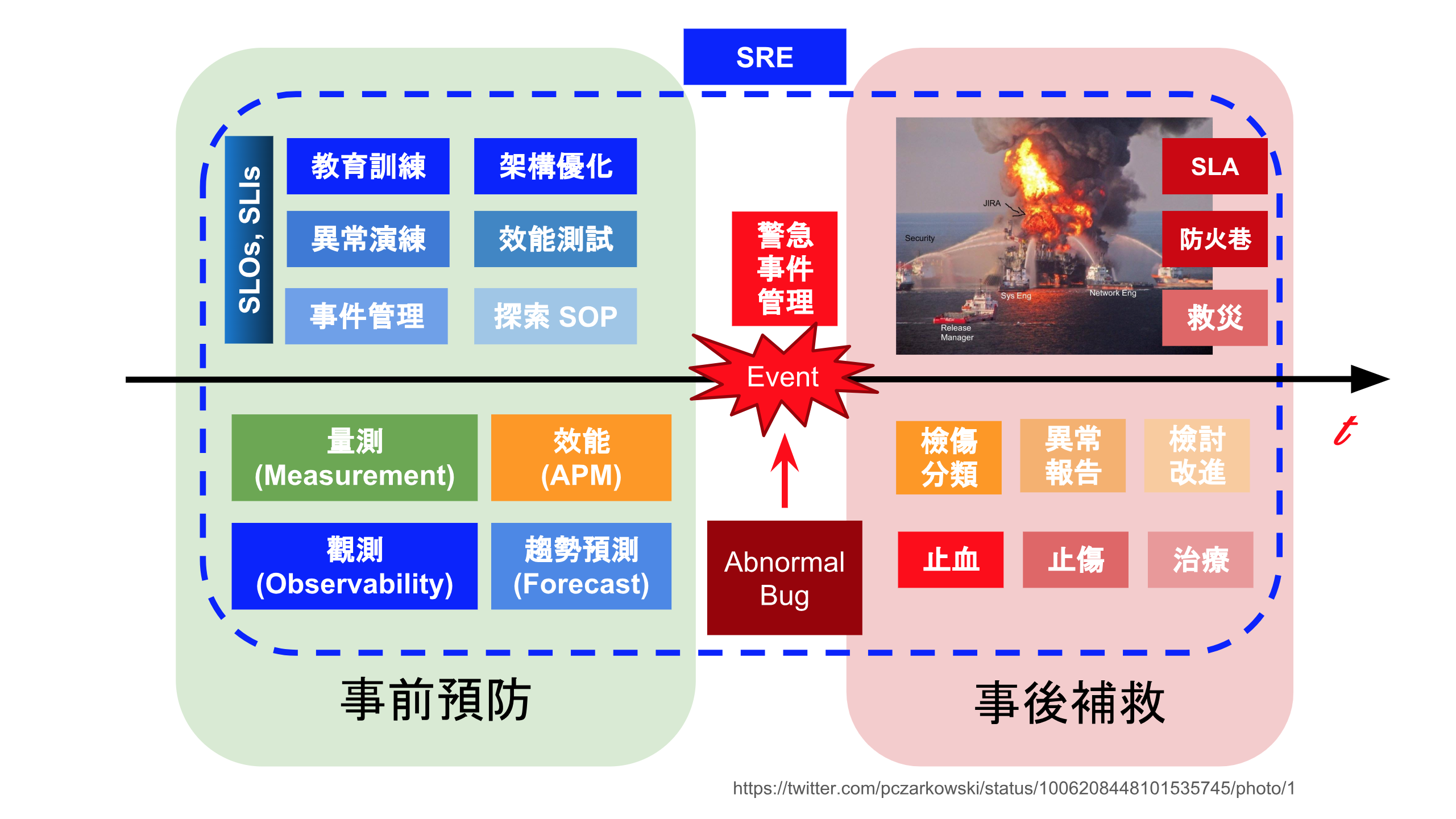
這張圖左上方藍色部分,就是我平常就在做的事情,特別是花很多時間在讓同事:
如何去了解自己的架構
了解架構現況
通常我不談 設計架構 這個題目,但我只要你清楚了解自己現況的架構,然後怎麼與其他團隊協作。
底下是我設計的一套了解架構方式,以 服務 Service 為單位:
High Level View: 跨服務的依賴、邊界定義- 通常大的架構 Overview 就是透過這個層次拼奏出來。
- 我在 AWS reInvent reCAP 2019 的分享:災難演練 @ AWS 實戰分享,其中 Page 20 的整體架構區塊圖,就是這張圖拼揍的。
- 這張圖可以跟公司各單位溝通,也可以用在外部文案。
Service Definition: 看進去,了解抽象角色定義與關係,不談技術- 抽象概念就是不談技術實踐,談的是角色的定義 (Role)、角色與角色之間的依賴關係
- 角色 (Role) 定義以功能為主,像是 Web、DB、API、Batch、LB … 等
- 角色之間溝通的通訊協議、資料流、通訊模式 (主動被動)
- 存取控管:Public、Protected、Private
- 要搭配 User Story 講使用情境。
- 這張圖通常可以跟產品經理溝通
Go Live: 具象架構實踐,包含測試環境、正式環境的實踐技術 (K8s, AWS or others.)- 技術實踐是工程團隊相互溝通用的。
- 技術呈現的 Slide 會搭配 Definition 一起使用。
- 考量實踐的原則,例如 AWS Well-Architected Framework 的概念。
- 考量可測性:環境建置、部署、效能、可測性
- 考量實際維運,包含部署、建置、監控、維護、資安、成本、治理。
這三個層次的基本想法就是:
- 跳出來 看全景
- 看進去 學本質
- 動手做 找實踐
所以如果連這些都不清楚,出問題的時候,會有很長的時間在釐清整個架構的樣子,然後可能沒搞清楚的狀況之下,做了誤判,錯誤的方向會讓整個問題越來越複雜,甚至造成無法挽回的遺憾與事故,所以釐清這些東西對我來講是必要的。
相關說明,在 從緊急事件 談 SRE 應變能力的培養 的 Part 2 有簡單說明。
另外,釐清這個,不見得要有前述那些工具,因為實際狀況常常是:
你必須在只有基本的系統資訊,沒有那些工具的狀況中,作出判斷。
如果你的公司是接案型態,那麼有很大的機會會接到一個已經跑了一段時間的系統,完全不知道架構的狀況,第一個任務就是要解決他的異常。
Slogan in SRE
這段是 Ch12 Effective Troubleshooting 一開始的引言,也是我自己很有感的一段話:
Be warned that being an expert is more than understanding how a system is supposed to work. Expertise is gained by investigating why a system doesn’t work.
值得警惕的是,理解一個系統應該如何工作並不能使人成為專家。只有靠調查系統為何不能正常工作才行。
– Brian Redman
延伸閱讀
站內文章
- 從緊急事件 談 SRE 應變能力的培養 - DevOpsDays Taipei 2018
- 淺談系統監控與 CloudWatch 的應用 - AWS User Group Taiwan
- 如何量測系統的容量?
- Slogan in SRE
- 事件管理與康威定律
- AWS Well-Architected Framework
- 個人著作《SRE 實踐與開發平台指南》 (2023/08 上市)
Comments
About
著作
演講
AWS Certifications


