CloudWatch for Monitoring and Alarm Systems
本文整理 CloudWatch 最主要的應用:監控服務 與 告警系統 的建置。
監控系統
下圖是我畫的 CloudWatch Services 做系統監控的流程:
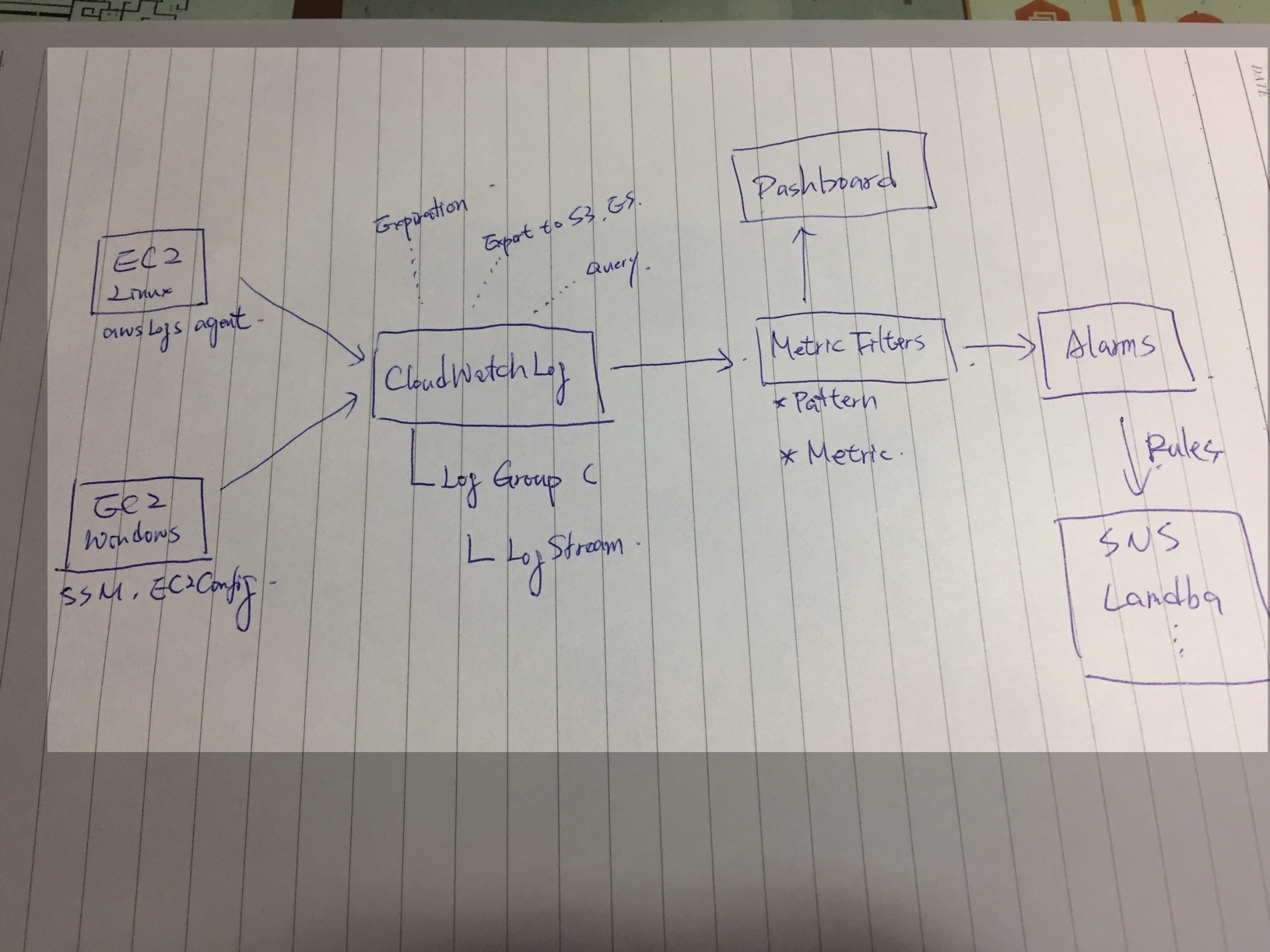
這個流程會使用到整個 CloudWatch Services,包含 Logs / Alarms / Metric Filers / Custom Metric / Dashboard,最後配合 CloudWatch Rules / SNS / Lambda 做事件驅動,最後通知到 Slack / SMS .. 等。
值得一提的是,這整串流程是 即時 (Realtime),如果自己蓋類似的服務,我 Survey 過知名的組合,像是:
- ELK: 使用了兩年,C/P 值不高,費用以及維護成本驚人,雖然後來有系統架構的解法,但是基於成本考量,打算慢慢換掉。
- Telegraf / Collectd + InfluxDB + Grafana: 很容易安裝,效果也不錯,但是 InfluxDB 需要有好的 File System 支撐。
- Grafana 每個 Metric 只能設定一個 Alert, 而且 Source 如果是 CloudWatch 就不支援 Alert
- Grafana 可以跟 Slack + S3 整合,然後把 Metric 圖檔直接丟到 S3,然後在 Slack 呈現。這是我一直很想要的功能,Datadog 有。
- aws-cloudwatch-chart-slack
- Fluentd + Prometheus + Grafana: 理由同上
這些都要自己養機器,特別是維護 Storage 部分,會有很多額外的 Operations、教育訓練、權限管控、安全性,最重要的是成本高很多,而且效果不見得好,C/P 值不高。
使用 AWS CloudWatch 整套方案,幾乎可以避免上述我擔心的問題,而且維護 CloudWatch 本身,除了 Dashboard 之外,都可以程式化。唯一要注意的是 CloudWatch Price,要留意 Log 的使用狀況,以及設定 Expiration。
告警系統 (Alarm Systems)
底下是我利用 CloudWatch + Lambda 設計的告警系統 Alarm System,主要設計概念如下:
- 監控通知定義三種:
Info、Warning、Urgent- Info:設計成 Reporter 形式 (Long Polling),定時把資訊丟到 Slack 的特定 channel,這樣的設計讓系統維運人員可以隨時掌握系統狀況,而且不用帶電腦
- Warning:超過指標的臨界值,就會通報道 Slack 主要負責單位的 channel,並且
@channel - Urgent:同時丟 Slack Channel + 送簡訊給對應的人 (SNS -> SMS)
- 通報只有一個重點:出問題要能知道問題是啥、然後有人可以去處理
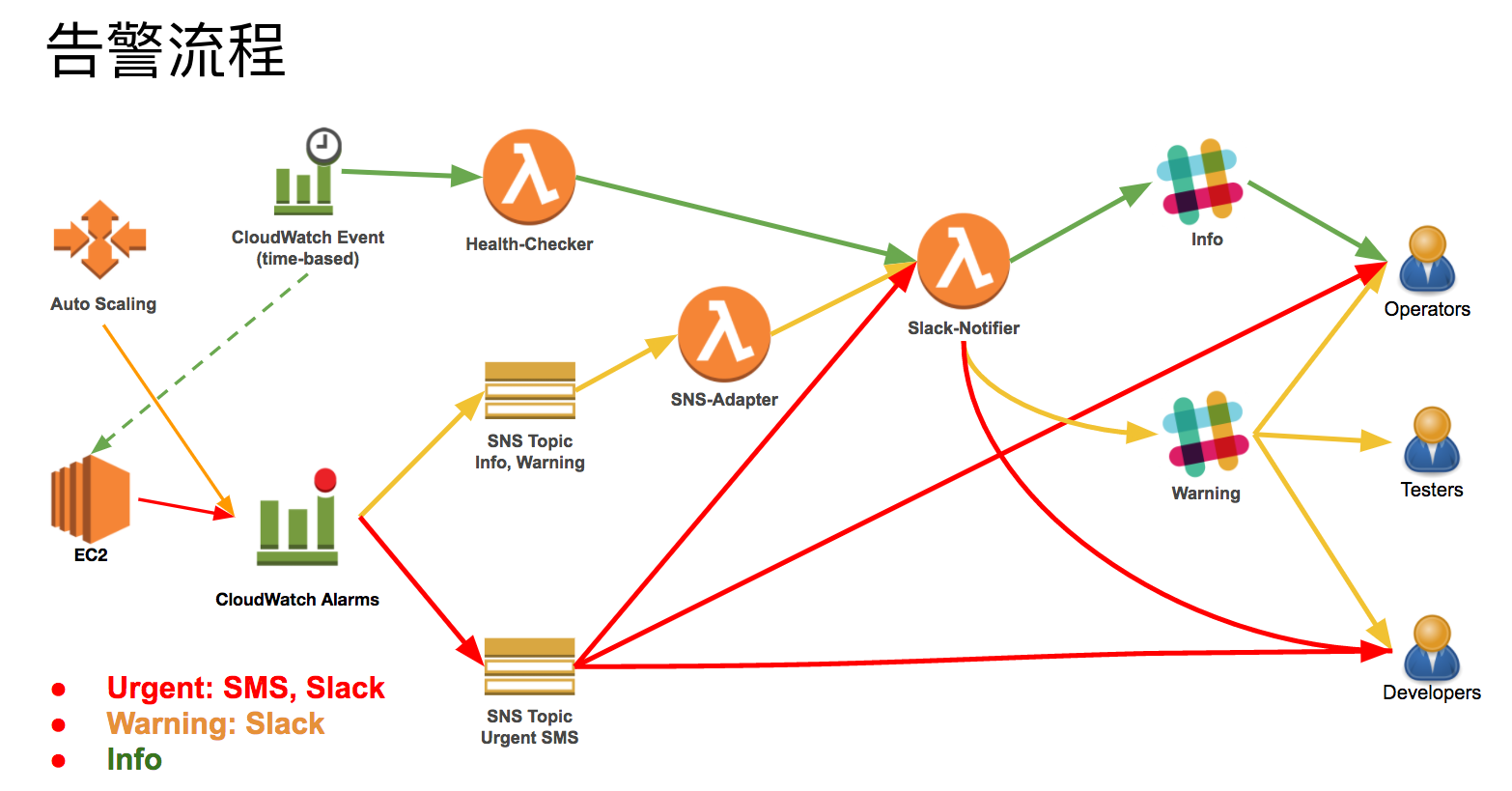
設計的重點在於:
- 什麼樣的
告警等級,用什麼樣的方式,通知到什麼人?告警一詞是我當兵時任務用詞,我們主要維護實體通訊線路,確保線路正常,當出現異常時,稱『告警搶修』
- 等級、方式、人
等級:不同人看不同等級,不需要全部的人都知道方式:有即時性以及時效性的問題人:找到對的人,才能快速把問題排除
參加 AWS User Group 有人推薦用 Push …. 我回家路上一值想,為啥我都沒想到這個方法??因為,我從來不會看 APP 的 Push,因為跟山一樣多,都直接忽略 XDD
延伸閱讀
系列文章
- Study Notes - CloudWatch
- Study Notes - CloudWatch Core Functions
- Study Notes - CloudWatch Agent for Linux
- Study Notes - CloudWatch awslogs
- Study Notes - CloudWatch Metrics
- Study Notes - CloudWatch FAQ
- Solution - CloudWatch for Monitoring and Alarm Systems
- Solution - CloudWatch for Log Analysis
- Solution - CloudWatch for Performance Testing
- 2017/06/21: 淺談系統監控與 CloudWatch 的應用 - AWS User Group Taiwan
站內延伸
- AWS Certified SysOps Administrator - Associate 準備心得
- Lambda Network Traffic Test in VPC w/ or w/o Endpoint
- Resource Provisioning and DevOps
- Study Notes - AWS VPC (Virtual Private Cloud)
- 軟體自動化測試常見的問題
- AWS Study Roadmap
參考資料
- CloudWatch Monitoring Supported AWS Services
- Monitoring Memory and Disk Metrics for Amazon EC2 Linux Instances
更新紀錄
- 2018/12/25: 從 Study Notes - CloudWatch 解構
Comments
About
著作
演講
- 演講錄影 @ Youtube
- 探索職涯、複利人生 - AWS Career Exploration Day 2023
- 個人著作 SRE 書友見面會
- 軟體測試實務 - 新書發表會
- 探索職涯、成就未來 - AWS Career Exploration Day 2022
- 從理想、到現實的距離,開啟品味軟體測試之路
- 91APP 在 AWS 上的 SRE 實踐之路
- 在矩陣型組織裡,如何有效管理 AWS 的成本結構與系統架構
- 災難演練 @ AWS 實戰分享
- 導讀持續交付 2.0 - 談當代軟體交付之虛實融合
- 聊聊軟體交付的濫觴 談產出物管理
- 從緊急事件 談 SRE 應變能力的培養
- 邁向 API 經濟 - API Gateway 導入之旅
- Monitoring Tools 大亂鬥 - AWS CloudWatch
- Ops as Code using Serverless
- 淺談系統監控與 CloudWatch 的應用
AWS Certifications


